TL;DR
Ý chính: Google Research đã công bố Titans, một kiến trúc thần kinh mới sử dụng phương pháp đào tạo trong thời gian thử nghiệm để cho phép các mô hình học và ghi nhớ dữ liệu theo thời gian thực trong quá trình suy luận. Thông số kỹ thuật chính: Kiến trúc đạt được khả năng thu hồi hiệu quả tại các cửa sổ ngữ cảnh vượt quá 2 triệu mã thông báo, vượt trội đáng kể so với GPT-4 trên điểm chuẩn BABILong cho các tác vụ truy xuất. Tại sao lại quan trọng: Titans giải quyết tình trạng lãng quên nghiêm trọng Mạng thần kinh tái phát (RNN) và chi phí bậc hai của Máy biến áp bằng cách tích cực cập nhật các tham số để giảm thiểu sự bất ngờ về dữ liệu mới. Sự đánh đổi: Mặc dù nặng hơn về mặt tính toán so với các mô hình suy luận tĩnh như IBM Granite, Titans mang lại khả năng biểu đạt vượt trội cho các nhiệm vụ phức tạp như khám phá pháp luật hoặc phân tích bộ gen.
Google Research vừa ra mắt “Titans”, một kiến trúc thần kinh mới thách thức độ cứng nhắc cơ bản của các mô hình AI hiện tại bằng cách cho phép chúng “học cách ghi nhớ” trong thời gian thực trong quá trình suy luận.
Không giống như Transformers truyền thống dựa vào trọng số tĩnh hoặc Mạng thần kinh tái phát (RNN) sử dụng phân rã trạng thái cố định, Titans sử dụng mô-đun “Bộ nhớ thần kinh”. Thành phần này chủ động cập nhật các tham số của chính nó dưới dạng luồng dữ liệu, xử lý hiệu quả cửa sổ ngữ cảnh dưới dạng vòng lặp đào tạo liên tục thay vì vùng đệm tĩnh.
Thể hiện việc thu hồi hiệu quả tại các cửa sổ ngữ cảnh vượt quá 2 triệu mã thông báo, kiến trúc vượt trội đáng kể so với GPT-4 trên điểm chuẩn BABILong. Thử nghiệm “Kim trong Haystack”này thách thức các mô hình truy xuất các điểm dữ liệu cụ thể từ các tài liệu mở rộng, một nhiệm vụ mà các mô hình tiêu chuẩn thường thất bại.
Khuyến mãi
Sự thay đổi mô hình’Bộ nhớ thần kinh’
Các kiến trúc AI hiện tại phải đối mặt với sự cân bằng cơ bản giữa độ dài ngữ cảnh và hiệu quả tính toán. Máy biến áp, kiến trúc chủ đạo đằng sau các mô hình như GPT-4 và Claude, dựa vào cơ chế chú ý có tỷ lệ bậc hai theo độ dài chuỗi. Điều này làm cho các bối cảnh cực kỳ dài bị hạn chế về mặt tính toán.
Ngược lại, các RNN tuyến tính như Mamba nén bối cảnh thành một vectơ trạng thái cố định. Mặc dù điều này cho phép độ dài vô hạn nhưng nó thường dẫn đến “sự quên lãng nghiêm trọng” khi dữ liệu mới ghi đè lên thông tin cũ. Titans giới thiệu lộ trình thứ ba: “Đào tạo trong thời gian thử nghiệm”(TTT).
Thay vì cố định trọng số của mô hình sau giai đoạn đào tạo ban đầu, Kiến trúc Titans cho phép mô-đun bộ nhớ tiếp tục học hỏi trong quá trình suy luận. Bằng cách coi cửa sổ ngữ cảnh là một tập dữ liệu, mô hình sẽ chạy một vòng lặp giảm dần độ dốc nhỏ trên các mã thông báo đến. Cấu trúc này cập nhật các tham số bên trong để thể hiện tốt hơn tài liệu cụ thể mà nó đang xử lý.
Như nhóm Nghiên cứu của Google giải thích, “thay vì nén thông tin vào trạng thái tĩnh, kiến trúc này chủ động tìm hiểu và cập nhật các tham số của chính nó dưới dạng luồng dữ liệu.”
Thông qua quá trình học tập tích cực này, mô hình sẽ điều chỉnh chiến lược nén một cách linh hoạt, ưu tiên thông tin có liên quan đến nhiệm vụ hiện tại thay vì áp dụng chức năng phân rã một kích thước phù hợp cho tất cả.
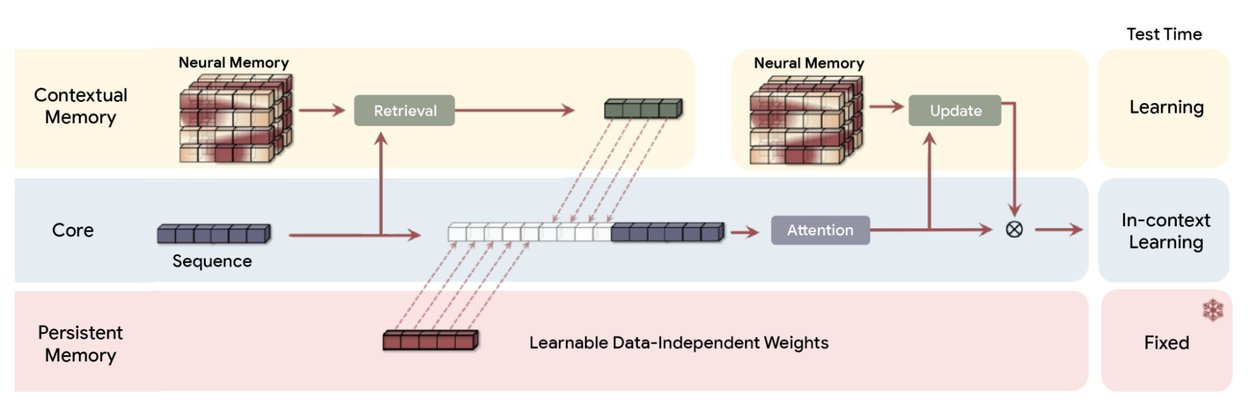
Tổng quan về kiến trúc Titans (MAC). Nó sử dụng bộ nhớ dài hạn để nén dữ liệu trong quá khứ, sau đó kết hợp phần tóm tắt vào ngữ cảnh và chuyển nó đến sự chú ý. Khi đó sự chú ý có thể quyết định liệu nó có cần chú ý đến sự tóm tắt của quá khứ hay không. (Nguồn: Google)
Để quản lý chi phí tính toán, Titans sử dụng “Chỉ số bất ngờ”dựa trên lỗi độ dốc. Khi xử lý mã thông báo mới, mô hình sẽ tính toán sự khác biệt giữa dự đoán của nó và đầu vào thực tế. Lỗi cao biểu thị”bất ngờ”, nghĩa là thông tin mới lạ và cần được ghi nhớ. Sai số thấp cho thấy thông tin đó là dư thừa hoặc đã được biết đến.
Sử dụng một ví dụ cụ thể, các nhà nghiên cứu lưu ý rằng”nếu từ mới là’mèo’và trạng thái bộ nhớ của mô hình đã mong đợi một từ động vật, thì độ dốc (bất ngờ) sẽ thấp. Nó có thể bỏ qua việc ghi nhớ một cách an toàn.”
Việc ghi nhớ có chọn lọc như vậy bắt chước hiệu quả sinh học, cho phép hệ thống loại bỏ dữ liệu thông thường trong khi vẫn giữ lại những điểm bất thường quan trọng hoặc sự kiện mới.
Bổ sung cho hoạt động học tập tích cực này là một phương pháp thích ứng “Cơ chế quên lãng.” Hoạt động như một cổng, chức năng này áp dụng sự giảm trọng số cho các tham số bộ nhớ khi bối cảnh tường thuật thay đổi đáng kể. Bằng cách cân bằng giữa việc tiếp nhận dữ liệu mới đáng ngạc nhiên với việc phát hành thông tin lỗi thời có kiểm soát, Titans duy trì khả năng trình bày bối cảnh với độ chính xác cao.
Điều này giúp mô hình không bị ảnh hưởng bởi tiếng ồn gây ra cho các mô hình trạng thái cố định. Mô hình Nested Learning xác định cơ sở lý thuyết cho phương pháp này:
“Nested Learning tiết lộ rằng một mô hình ML phức tạp thực sự là một tập hợp các vấn đề tối ưu hóa liên kết chặt chẽ, được lồng vào nhau hoặc chạy song song.”
“Mỗi vấn đề nội bộ này đều có luồng ngữ cảnh riêng, tập hợp thông tin riêng biệt mà nó đang cố gắng học.”
Nền tảng lý thuyết này thừa nhận rằng kiến trúc và tối ưu hóa là hai mặt của cùng một đồng tiền. Bằng cách xem mô hình như một hệ thống phân cấp của các vấn đề tối ưu hóa, Titans có thể tận dụng độ sâu tính toán sâu trong mô-đun bộ nhớ của nó. Điều này giải quyết vấn đề”quên thảm khốc”vốn từ lâu đã hạn chế tiện ích của các mạng lặp lại.
Bối cảnh & Điểm chuẩn cực đoan
Đáng chú ý nhất là hệ thống bộ nhớ hoạt động này xử lý các cửa sổ ngữ cảnh phá vỡ kiến trúc truyền thống. Điểm chuẩn của Google cho thấy Titans duy trì khả năng thu hồi hiệu quả ở độ dài ngữ cảnh vượt quá 2.000.000 mã thông báo. Để so sánh, các mô hình sản xuất hiện tại như GPT-4o thường được giới hạn ở mức 128 nghìn mã thông báo.
Trong các thử nghiệm đầy thử thách “Needle-in-a-Haystack”(NIAH), đo lường khả năng của mô hình trong việc truy xuất một thông tin cụ thể bị chôn vùi trong một khối lượng lớn văn bản không liên quan, Titans đã thể hiện tính ưu việt đáng kể so với các đường cơ sở RNN tuyến tính. Trong tác vụ “Single Needle” với tiếng ồn tổng hợp (S-NIAH-PK) ở độ dài mã thông báo 8k, biến thể Titans MAC đạt được độ chính xác 98,8%, so với chỉ 31,0% của Mamba2.
Hiệu suất trên dữ liệu ngôn ngữ tự nhiên cũng mạnh mẽ tương tự. Trên phiên bản thử nghiệm WikiText (S-NIAH-W), Titans MAC đạt 88,2%, trong khi Mamba2 gặp khó khăn ở mức 4,2%. Những kết quả như vậy cho thấy rằng mặc dù RNN tuyến tính hoạt động hiệu quả, nhưng khả năng nén ở trạng thái cố định của chúng sẽ làm mất đi độ chính xác quan trọng khi xử lý dữ liệu phức tạp, ồn ào có trong các tài liệu trong thế giới thực.
Hiệu suất điểm chuẩn: Titans so với Đường cơ sở hiện đại
Nhấn mạnh vào các khả năng ngoài tìm kiếm từ khóa đơn giản, nhóm Nghiên cứu của Google lưu ý rằng”mô hình này không chỉ đơn thuần là ghi chú; mà là hiểu và tổng hợp toàn bộ câu chuyện”. Bằng cách cập nhật các trọng số của nó để giảm thiểu sự bất ngờ của toàn bộ chuỗi, mô hình sẽ xây dựng sự hiểu biết về cấu trúc của cốt truyện. Điều này cho phép nó truy xuất thông tin dựa trên các mối quan hệ ngữ nghĩa thay vì chỉ khớp mã thông báo.
Google cung cấp bản phân tích chi tiết về tính năng xác định của kiến trúc: mô-đun bộ nhớ của nó. Không giống như Mạng thần kinh tái phát truyền thống (RNN), thường bị hạn chế bởi bộ nhớ ma trận hoặc vectơ có kích thước cố định, về cơ bản là một vùng chứa tĩnh có thể dễ dàng trở nên quá tải hoặc ồn ào khi dữ liệu tích lũy, Titans giới thiệu một mô-đun bộ nhớ dài hạn thần kinh mới.
Mô-đun này hoạt động như một mạng lưới thần kinh sâu theo đúng nghĩa của nó, đặc biệt sử dụng perceptron nhiều lớp (MLP). Bằng cách cấu trúc bộ nhớ như một mạng có thể học được thay vì một kho lưu trữ tĩnh, Titans đạt được sức mạnh biểu đạt cao hơn đáng kể. Sự thay đổi kiến trúc này cho phép mô hình tiếp thu và tóm tắt khối lượng lớn thông tin một cách linh hoạt.
Thay vì chỉ cắt bớt dữ liệu cũ hơn hoặc nén dữ liệu đó sang trạng thái có độ chính xác thấp để nhường chỗ cho dữ liệu đầu vào mới, mô-đun bộ nhớ MLP tổng hợp ngữ cảnh, đảm bảo rằng các chi tiết quan trọng và mối quan hệ ngữ nghĩa được giữ nguyên ngay cả khi cửa sổ ngữ cảnh mở rộng thành hàng triệu mã thông báo.
Ngoài độ chính xác truy xuất, Titans còn cho thấy hứa hẹn về hiệu quả mô hình hóa ngôn ngữ nói chung. Ở quy mô 340 triệu tham số, varianbencht Titans MAC đạt được độ phức tạp 25,43 trên tập dữ liệu WikiText. Hiệu suất như vậy vượt qua cả đường cơ sở Transformer++ (31,52) và kiến trúc Mamba ban đầu (30,83).
Điều này cho thấy rằng các bản cập nhật bộ nhớ hoạt động cung cấp sự thể hiện tốt hơn về phân bố xác suất ngôn ngữ so với chỉ riêng trọng số tĩnh. Ali Behrouz, nhà nghiên cứu chính của dự án, nhấn mạnh ý nghĩa lý thuyết của thiết kế này, nói rằng “Titan có khả năng giải quyết các vấn đề ngoài TC0, nghĩa là về mặt lý thuyết, Titan có tính biểu cảm cao hơn Transformers và hầu hết các mô hình hồi quy tuyến tính hiện đại nhất trong các nhiệm vụ theo dõi trạng thái.”
Tính biểu cảm như vậy cho phép Titan xử lý các nhiệm vụ theo dõi trạng thái, chẳng hạn như theo dõi các biến thay đổi trong một tệp mã dài hoặc theo dõi các điểm cốt truyện của một cuốn tiểu thuyết, thường gây nhầm lẫn cho các mô hình lặp lại đơn giản hơn.
Hiệu quả: MIRAS so với Thị trường
Để chính thức hóa những đổi mới kiến trúc này, Google đã giới thiệu khung MIRAS. Thống nhất các phương pháp lập mô hình trình tự khác nhau, bao gồm Transformers, RNN và Titans, mô hình này hoạt động dưới sự bảo trợ của “bộ nhớ liên kết”.
Theo Google, khung MIRAS chia mô hình trình tự thành bốn lựa chọn thiết kế cơ bản. Đầu tiên là Kiến trúc bộ nhớ, quy định dạng cấu trúc được sử dụng để lưu trữ thông tin, từ các vectơ và ma trận đơn giản đến các tri giác nhiều lớp sâu được tìm thấy trong Titans. Điều này được kết hợp với Xu hướng chú ý, một mục tiêu học tập nội bộ chi phối cách mô hình ưu tiên dữ liệu đến, quyết định một cách hiệu quả những gì đủ quan trọng để ghi nhớ.
Để quản lý năng lực, khung này sử dụng Cổng lưu giữ. MIRAS diễn giải lại “cơ chế quên” truyền thống như các hình thức chính quy hóa cụ thể, đảm bảo sự cân bằng ổn định giữa việc học các khái niệm mới và lưu giữ bối cảnh lịch sử. Cuối cùng, Thuật toán bộ nhớ xác định các quy tắc tối ưu hóa cụ thể dùng để cập nhật trạng thái bộ nhớ, hoàn thành chu trình học tập tích cực.
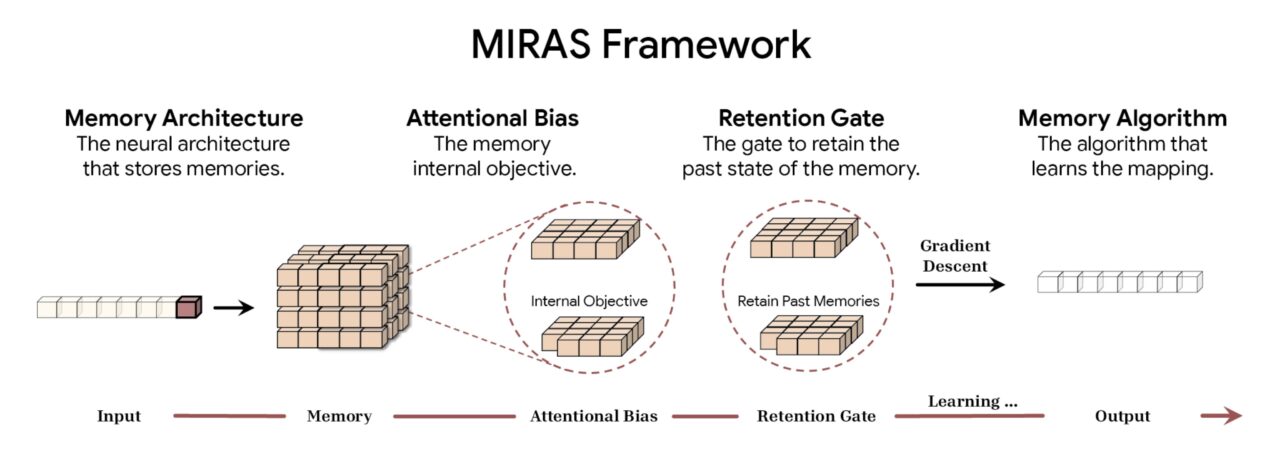 Tổng quan về khung MIRAS (Nguồn: Google)
Tổng quan về khung MIRAS (Nguồn: Google)
Bằng cách chia mô hình trình tự thành bốn thành phần này, MIRAS làm sáng tỏ “sự kỳ diệu” của cơ chế chú ý. Nó phân loại lại chúng thành một loại bộ nhớ liên kết với các cài đặt độ lệch và lưu giữ cụ thể. Do đó, các nhà nghiên cứu có thể trộn và kết hợp các thành phần, có khả năng dẫn đến các kiến trúc lai kết hợp độ chính xác của sự chú ý với hiệu quả tái diễn.
Sự thay đổi mô hình kiến trúc: Khung MIRAS
Bộ nhớ động, dung lượng cao trái ngược hoàn toàn với xu hướng phổ biến trong Edge AI, trong đó mục tiêu thường là thu nhỏ các mô hình tĩnh để triển khai cục bộ. Ví dụ: sự ra mắt Granite 4.0 Nano của IBM đã giới thiệu các mô hình nhỏ tới 350 triệu tham số được thiết kế để chạy trên máy tính xách tay.
Trong khi chiến lược của IBM tập trung vào việc làm cho trí thông minh tĩnh trở nên phổ biến và rẻ tiền, thì phương pháp Titans của Google lại nhằm mục đích làm cho mô hình này trở nên thông minh hơn và dễ thích ứng hơn. Điều này áp dụng ngay cả khi nó yêu cầu chi phí tính toán để cập nhật trọng số trong quá trình suy luận.
Chi phí tính toán hay “Khoảng cách bối cảnh”vẫn là trở ngại chính đối với Titan. Việc cập nhật các tham số bộ nhớ trong thời gian thực tốn kém hơn về mặt tính toán so với suy luận tĩnh được các mô hình như Granite hoặc Llama sử dụng. Tuy nhiên, đối với các ứng dụng đòi hỏi sự hiểu biết sâu sắc về các tập dữ liệu quy mô lớn, chẳng hạn như khám phá pháp lý, phân tích gen hoặc tái cấu trúc cơ sở mã, khả năng “tìm hiểu” tài liệu có thể tỏ ra có giá trị hơn tốc độ suy luận thô.
Là triển khai đầu tiên của tầm nhìn tự sửa đổi này, kiến trúc “Hope” đã được giới thiệu như một bằng chứng khái niệm trong Bài viết về Học tập lồng nhau. Khi ngành tiếp tục thúc đẩy các bối cảnh dài hơn và lý luận sâu hơn, các kiến trúc như Titans làm mờ ranh giới giữa đào tạo và suy luận có thể xác định thế hệ mô hình nền tảng tiếp theo.