Nhóm AI của Meta đang phải chịu áp lực rất lớn sau khi phát hành mẫu R1 của DeepSeek, mẫu này đã thách thức ngành AI với hiệu quả và hiệu suất chưa từng có.
Các bài đăng ẩn danh trên nền tảng mạng chuyên nghiệp Blind tiết lộ tình trạng hỗn loạn trong hàng ngũ của Meta, trong đó các kỹ sư mô tả nỗ lực điên cuồng để hiểu và tái tạo thành công của DeepSeek trong khi phải vật lộn với sự kém hiệu quả trong nội bộ và những sai lầm trong lãnh đạo.
Blind là một nền tảng mạng lưới chuyên nghiệp ẩn danh nơi nhân viên có thể chia sẻ thông tin, thảo luận các vấn đề tại nơi làm việc và kết nối với các đồng nghiệp trong ngành nghề giống nhau hoặc khác nhau. Nó có một hệ thống xác minh để đảm bảo rằng người dùng là nhân viên thực sự của công ty mà họ tuyên bố đang làm việc. Hệ thống này chủ yếu được các chuyên gia trong ngành công nghệ ưa chuộng.
Liên quan: DeepSeek R1 vượt qua như thế nào ChatGPT o1 Theo lệnh trừng phạt, Xác định lại hiệu quả của AI chỉ sử dụng 2.048 GPU
Một nhân viên Meta ẩn danh, đăng dưới tên “ngi,” tóm tắt tâm trạng trong bộ phận GenAI của Meta:
“Nó bắt đầu với DeepSeek V3 [một mô hình DeepSeek được phát hành vào tháng 12 năm 2024], khiến Llama 4 vốn đã tụt hậu về điểm chuẩn. Thêm một sự xúc phạm đến thương tích là’công ty Trung Quốc vô danh với ngân sách đào tạo 5,5 triệu USD.’mọi thứ chúng ta có thể từ nó
Tôi thậm chí không phóng đại. Ban quản lý lo lắng về việc biện minh cho chi phí khổng lồ của tổ chức GenAI. Họ sẽ đối mặt với sự lãnh đạo như thế nào khi mỗi’lãnh đạo’của tổ chức GenAI đang kiếm được nhiều tiền hơn chi phí đào tạo toàn bộ DeepSeek V3 và chúng tôi có hàng tá’lãnh đạo’như vậy. DeepSeek R1 khiến mọi thứ trở nên đáng sợ hơn. Tôi không thể tiết lộ thông tin bí mật nhưng dù sao thì nó cũng sẽ sớm được công khai.
Đáng lẽ đó phải là một tổ chức nhỏ tập trung vào kỹ thuật nhưng vì có một nhóm người muốn tham gia vào hoạt động thu hút tác động và tăng cường tuyển dụng một cách giả tạo trong org, mọi người đều thua.”
Nhận xét của nhân viên nêu bật sự không hài lòng trong nội bộ đối với cách tiếp cận phát triển AI của Meta, mà nhiều người mô tả là quá quan liêu, tốn nhiều tài nguyên và bị thúc đẩy bởi các số liệu hời hợt hơn là sự đổi mới có ý nghĩa.
Việc phát hành DeepSeek R1 đã bộc lộ những thiếu sót này và buộc một trong những công ty lớn nhất ngành AI phải tính toán.
Liên quan: LLaMA AI Under Fire – What Meta Is’t Nói với bạn về các mô hình “Nguồn mở”
DeepSeek R1 gây ra làn sóng chấn động cho ngành công nghệ Hoa Kỳ
Mô hình R1 của DeepSeek, được phát hành vào tháng 1 Ngày 10 tháng 1 năm 2025, đã nâng tầm bối cảnh AI toàn cầu bằng cách chứng minh rằng các mô hình hiệu suất cao có thể được phát triển với chi phí thấp hơn thường liên quan đến các dự án như vậy.
Sử dụng GPU Nvidia H800—chip cấp thấp hơn bị hạn chế bởi các biện pháp kiểm soát xuất khẩu của Hoa Kỳ—Các kỹ sư của DeepSeek đã đào tạo mô hình này với chi phí dưới 6 triệu USD, theo một bài báo nghiên cứu phát hành vào tháng 12 năm 2024.
Những thứ này GPU, được cố tình điều chỉnh để tuân thủ các lệnh trừng phạt của Hoa Kỳ, đã đặt ra những thách thức đặc biệt, nhưng kỹ thuật tối ưu hóa của DeepSeek đã cho phép nhóm đạt được hiệu suất tương đương với các mẫu đầu ngành.
Điểm chuẩn của R1 bao gồm điểm 97,3% trên MATH-500 và điểm 79,8% trên AIME 2024, khiến nó trở thành một trong những hệ thống AI có năng lực nhất trên thế giới.
Hiệu quả của DeepSeek R1, cũng vượt trội một phần so với mô hình o1 của OpenAI, không chỉ làm lung lay niềm tin vào những gã khổng lồ công nghệ Hoa Kỳ như Meta mà còn gây ra những phản ứng đáng kể trên thị trường.
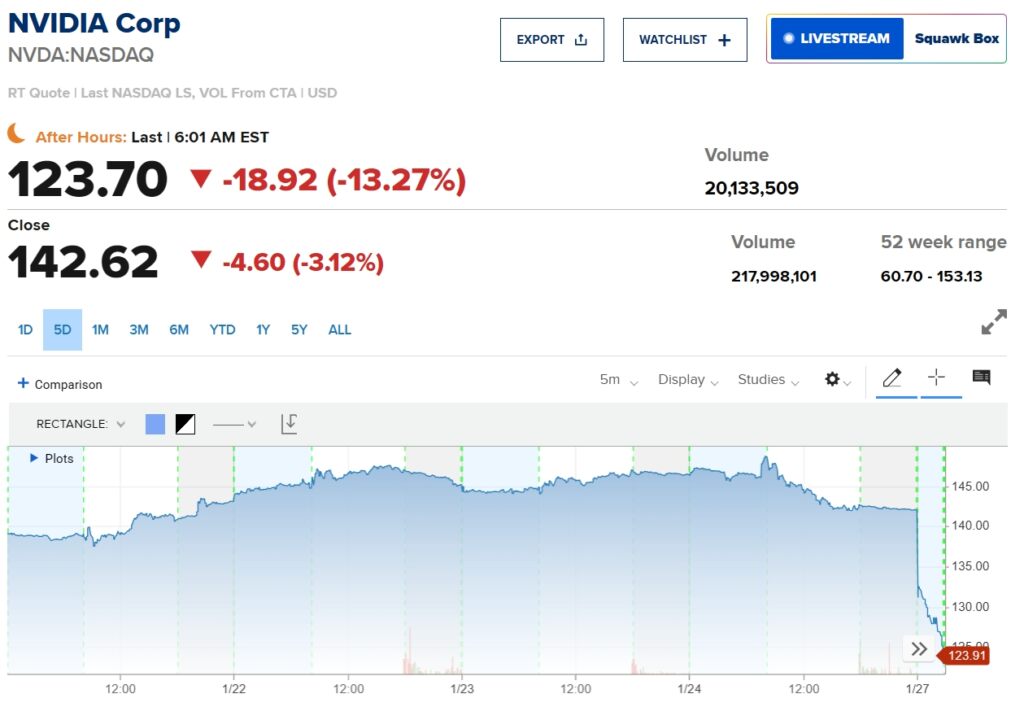
Cổ phiếu của Nvidia đã giảm hơn 13% trong giao dịch tiếp thị trước sau khi mô hình này được phát hành và chỉ số tương lai Nasdaq 100 giảm hơn 5%. Trong khi đó, DeepSeek đã leo lên vị trí hàng đầu trên App Store của Apple tại Hoa Kỳ, vượt qua ChatGPT của OpenAI về số lượt tải xuống.
Các kỹ sư Meta đặt câu hỏi về sự phụ thuộc vào việc đào tạo AI tính toán tốn kém
Trong Meta, các kỹ sư đã chỉ trích việc công ty phụ thuộc vào sức mạnh tính toán thô bạo hơn là theo đuổi sự đổi mới hướng đến hiệu quả.
Một nhân viên đã nhận xét về Blind: Rất nhiều lãnh đạo thực sự không có ý tưởng gì (thậm chí rất nhiều kỹ thuật) về công nghệ cơ bản và họ tiếp tục bán’nhiều GPU hơn=thắng’cho lãnh đạo.”Một người khác chia sẻ thất vọng với văn hóa “theo đuổi tác động”, mô tả nó như một cuộc đua thăng tiến hơn là cam kết đạt được những tiến bộ có ý nghĩa.
Các nỗ lực AI của Meta cũng phải đối mặt với sự giám sát kỹ lưỡng vì thiếu linh hoạt so với các đối thủ cạnh tranh. Mô hình R1 của DeepSeek không chỉ tiết kiệm chi phí mà còn có nguồn mở, cho phép các nhà phát triển trên toàn thế giới kiểm tra và xây dựng dựa trên kiến trúc của nó.
Các cuộc thảo luận của Blind cũng tiết lộ những mối quan tâm rộng lớn hơn trong ngành. Các nhân viên của Google thừa nhận tác động đột phá của DeepSeek, với một lưu ý: “Những gì DeepSeek đang làm thực sự là điên rồ. Không chỉ có Meta, họ cũng đang đốt lửa dưới sự hỗ trợ của OpenAI, Google và Anthropic. Đó là một điều tốt, chúng tôi đang thấy trong thời gian thực, một cuộc cạnh tranh mở có hiệu quả như thế nào đối với sự đổi mới.”
Ý kiến này phản ánh nhận thức ngày càng tăng rằng các chiến lược sử dụng nhiều tài nguyên truyền thống có thể không còn đảm bảo sự thống trị trong phát triển AI.
Sự minh bạch này đã thu hút được sự khen ngợi từ các nhà lãnh đạo trong ngành, bao gồm cả Nhà khoa học AI trưởng của Meta, Yann LeCun, người đã viết trên LinkedIn: “DeepSeek đã thu được lợi nhuận từ nghiên cứu mở và nguồn mở (ví dụ: PyTorch và Llama từ Meta). Họ đã đưa ra những ý tưởng mới và xây dựng chúng dựa trên công việc của người khác.”
Mark Zuckerberg tăng gấp đôi đầu tư vào cơ sở hạ tầng AI
Trong trái ngược hoàn toàn, Meta lại tập trung vào đầu tư cơ sở hạ tầng quy mô lớn. CEO Mark Zuckerberg gần đây đã công bố kế hoạch triển khai hơn 1,3 triệu GPU vào năm 2025 và đầu tư 60-65 tỷ USD vào phát triển AI.
“Đây là một nỗ lực to lớn và trong những năm tới, nó sẽ thúc đẩy hoạt động kinh doanh và sản phẩm cốt lõi của chúng tôi, mở ra sự đổi mới mang tính lịch sử và mở rộng vị thế dẫn đầu về công nghệ của Mỹ”, Zuckerberg cho biết trong một tuyên bố công khai vào đầu năm nay. Tuy nhiên, những kế hoạch này hiện ngày càng mâu thuẫn với cách tiếp cận tinh gọn, ưu tiên hiệu quả mà DeepSeek thể hiện.
Sự trỗi dậy của DeepSeek cũng làm dấy lên các cuộc tranh luận về các hạn chế xuất khẩu của Hoa Kỳ đối với các công nghệ liên quan đến AI sang Trung Quốc. Quản lý Biden đã thực hiện các biện pháp nhằm hạn chế khả năng tiếp cận của Trung Quốc với các chip tiên tiến, bao gồm cả GPU H100 của Nvidia
Tuy nhiên, khả năng đạt được kết quả đẳng cấp thế giới của DeepSeek với phần cứng bị hạn chế đã nhấn mạnh những hạn chế của các chính sách này. phát huy hết tác dụng và tập trung vào hiệu quả, DeepSeek đã biến những hạn chế thành lợi thế
Người sáng lập Liang Wenfeng, cựu giám đốc quỹ phòng hộ, đã mô tả chiến lược của công ty: “Chúng tôi ước tính điều đó là tốt nhất. mô hình trong và ngoài nước có thể có sự chênh lệch một lần về cơ cấu mô hình và động lực đào tạo. Vì lý do này, chúng ta cần tiêu thụ sức mạnh tính toán gấp bốn lần để đạt được hiệu quả tương tự. Điều chúng ta cần làm là liên tục thu hẹp những khoảng cách này”.
Khi ngành AI vật lộn với những tác động từ sự thành công của DeepSeek, Meta phải đối mặt với nhu cầu cấp thiết để thích nghi. Các nhân viên của công ty đã bày tỏ sự thất vọng của họ và kêu gọi sự thay đổi hướng tới các chiến lược hiệu quả hơn, dựa trên sự đổi mới. Hiện tại, mô hình R1 của DeepSeek là minh chứng mạnh mẽ cho kỹ thuật tháo vát, định hình lại động lực cạnh tranh trong quá trình phát triển AI toàn cầu.