Mô hình lý luận mới của DeepSeek có tên là R1 thách thức hiệu suất của ChatGPT o1 của OpenAI—mặc dù mô hình này dựa vào GPU được điều chỉnh và ngân sách tương đối nhỏ.
Trong môi trường được định hình bởi các biện pháp kiểm soát xuất khẩu của Hoa Kỳ hạn chế chip tiên tiến, công ty khởi nghiệp trí tuệ nhân tạo Trung Quốc do nhà quản lý quỹ phòng hộ Liang Wenfeng thành lập, đã cho thấy hiệu quả và việc chia sẻ tài nguyên có thể thúc đẩy sự phát triển AI về phía trước như thế nào.
Sự trỗi dậy của công ty đã thu hút sự chú ý của giới công nghệ ở cả Trung Quốc và Hoa Kỳ.
Liên quan: Tại sao các lệnh trừng phạt của Hoa Kỳ có thể gặp khó khăn trong việc kiềm chế Sự phát triển công nghệ của Trung Quốc
Sự trỗi dậy nhanh chóng của DeepSeek
Hành trình của DeepSeek bắt đầu vào năm 2021, khi Liang, nổi tiếng với quỹ giao dịch định lượng High-Flyer, đã bắt đầu mua hàng nghìn GPU Nvidia.
Vào thời điểm đó, động thái này có vẻ bất thường. Là một trong những đối tác kinh doanh của Liang đã nói với Thời báo Tài chính: “Khi chúng tôi gặp anh ấy lần đầu tiên, anh ta là một anh chàng rất ngốc nghếch với kiểu tóc khủng khiếp đang nói về việc xây dựng một cụm 10.000 con chip để đào tạo các mô hình của riêng mình. Chúng tôi đã không coi trọng anh ấy.”
Theo cùng một nguồn tin, “Anh ấy không thể nói rõ tầm nhìn của mình ngoài việc nói: Tôi muốn xây dựng cái này và nó sẽ là một sự thay đổi trong trò chơi. Chúng tôi nghĩ điều này chỉ có thể thực hiện được từ những gã khổng lồ như ByteDance và Alibaba.”
Bất chấp những hoài nghi ban đầu, Liang vẫn tập trung vào việc chuẩn bị cho các biện pháp kiểm soát xuất khẩu tiềm năng của Hoa Kỳ. Tầm nhìn xa này đã cho phép DeepSeek đảm bảo nguồn cung cấp lớn phần cứng Nvidia, bao gồm GPU A100 và H800, trước khi các hạn chế sâu rộng có hiệu lực.
Liên quan: Dòng ngôn ngữ tầm nhìn VL2 của DeepSeek AI mã nguồn mở Các mô hình
DeepSeek đã gây chú ý khi tiết lộ rằng họ đã đào tạo mô hình R1 với 671 tỷ thông số chỉ với 5,6 triệu USD bằng cách sử dụng 2.048 Nvidia GPU H800.
Mặc dù hiệu suất của H800 được cố tình giới hạn cho thị trường Trung Quốc nhưng các kỹ sư của DeepSeek đã tối ưu hóa quy trình đào tạo để đạt được kết quả cấp cao với mức chi phí thấp hơn thường liên quan đến các mô hình ngôn ngữ quy mô lớn.
Trong cuộc phỏng vấn được xuất bản bởi MIT Technology Review, Zihan Wang, cựu nhà nghiên cứu DeepSeek, mô tả cách nhóm quản lý để giảm mức sử dụng bộ nhớ và chi phí tính toán trong khi vẫn duy trì độ chính xác.
Ông nói rằng những hạn chế về mặt kỹ thuật đã thúc đẩy họ khám phá các chiến lược kỹ thuật mới, cuối cùng giúp họ duy trì khả năng cạnh tranh với các phòng thí nghiệm công nghệ được tài trợ tốt hơn của Hoa Kỳ.
Liên quan: Trung Quốc Mô hình lý luận DeepSeek R1 và đối thủ OpenAI o1 bị kiểm duyệt gắt gao
Kết quả vượt trội về điểm chuẩn toán học và mã hóa
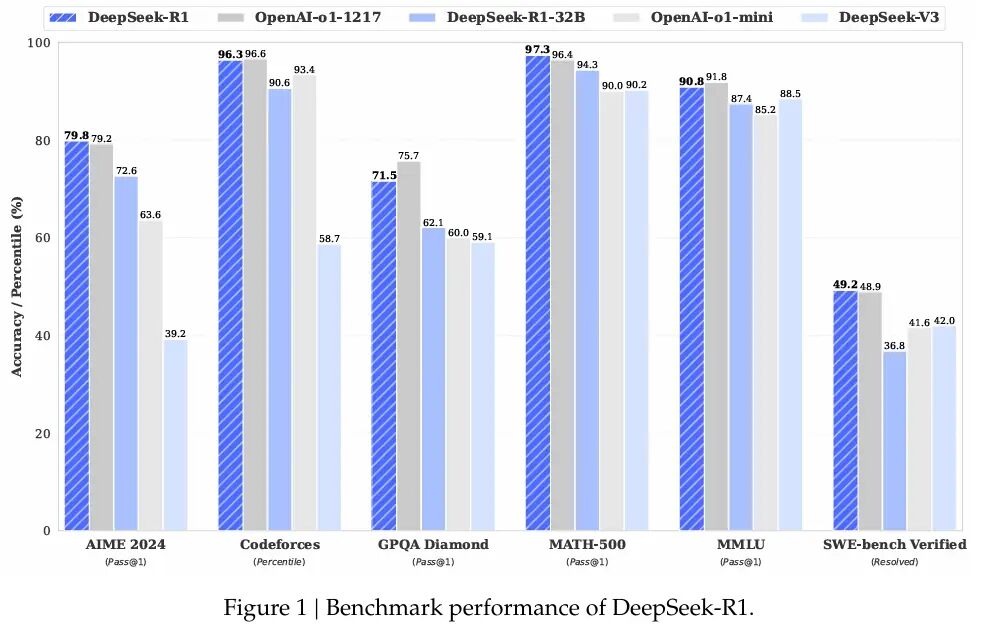
R1 thể hiện khả năng xuất sắc trên nhiều lĩnh vực điểm chuẩn toán học và mã hóa. DeepSeek tiết lộ rằng R1 đạt 97,3% (Pass@1) trên MATH-500 và 79,8% trên AIME 2024.
Những con số này sánh ngang với chuỗi o1 của OpenAI, cho thấy cách tối ưu hóa có chủ ý có thể thách thức các mô hình được đào tạo trên chip mạnh hơn.
Dimitris Papailiopoulos, nhà nghiên cứu chính tại phòng thí nghiệm AI Frontiers của Microsoft, nói với MIT Technology Review: “DeepSeek nhắm đến các câu trả lời chính xác thay vì nêu chi tiết từng bước hợp lý, giúp giảm đáng kể thời gian tính toán trong khi vẫn duy trì mức độ hiệu quả cao.”
Ngoài mô hình chính, DeepSeek đã phát hành các phiên bản R1 nhỏ hơn có thể chạy trên phần cứng cấp độ người tiêu dùng Aravind Srinivas, Giám đốc điều hành của Perplexity, đã tweet khi đề cập đến các biến thể nhỏ gọn, “DeepSeek đã sao chép phần lớn o1-mini và đã mở. đã lấy nguồn của nó.”
DeepSeek đã sao chép phần lớn o1-mini và đã lấy nguồn mở của nó. pic.twitter.com/2TbQ5p5l2c
— Aravind Srinivas (@AravSrinivas) Tháng Giêng Ngày 20 tháng 1 năm 2025
Lý luận theo chuỗi tư duy và R1-Zero
Ngoài việc đào tạo tiêu chuẩn của R1, DeepSeek còn mạo hiểm vào lĩnh vực củng cố thuần túy học với một biến thể có tên R1-Zero. Cách tiếp cận này, được trình bày chi tiết trong tài liệu nghiên cứu của công ty, loại bỏ việc tinh chỉnh có giám sát theo hướng Tối ưu hóa chính sách tương đối của nhóm (GRPO).
Bằng cách loại bỏ một mô hình phê bình riêng biệt và dựa vào điểm cơ bản được nhóm lại, R1-Zero thể hiện các hành vi tự suy nghĩ và suy nghĩ theo chuỗi suy nghĩ. Tuy nhiên, nhóm thừa nhận rằng R1-Zero tạo ra các kết quả đầu ra có ngôn ngữ lặp lại hoặc hỗn hợp, cho thấy cần có sự giám sát một phần trước khi có thể sử dụng nó trong các ứng dụng hàng ngày.
Đặc tính nguồn mở đằng sau DeepSeek khiến nó khác biệt với nhiều phòng thí nghiệm độc quyền. Trong khi các công ty Hoa Kỳ như OpenAI, Meta và Google DeepMind thường giấu phương pháp đào tạo của họ thì DeepSeek lại công khai mã, trọng lượng mô hình và công thức đào tạo.
Liên quan: Mistral AI ra mắt Pixtral 12B để xử lý văn bản và hình ảnh
Theo Liang, cách tiếp cận này xuất phát từ mong muốn xây dựng một nền văn hóa nghiên cứu ủng hộ minh bạch và tiến bộ tập thể. Trong cuộc phỏng vấn với cơ quan truyền thông Trung Quốc 36Kr, ông giải thích rằng nhiều dự án AI của Trung Quốc gặp khó khăn về hiệu quả so với các công ty cùng ngành phương Tây, và việc thu hẹp khoảng cách đó đòi hỏi sự hợp tác trên cả chiến lược phần cứng và đào tạo.
Quan điểm của anh ấy phù hợp với quan điểm của những người khác trong bối cảnh AI của Trung Quốc, nơi các phiên bản nguồn mở đang gia tăng. Alibaba Cloud đã giới thiệu hơn 100 mô hình nguồn mở và 01.AI, do Kai-Fu Lee thành lập, gần đây đã hợp tác với Alibaba Cloud để thành lập một phòng thí nghiệm AI công nghiệp.
Cộng đồng công nghệ toàn cầu đã phản hồi bằng một phản hồi sự pha trộn giữa sợ hãi và thận trọng. Trên X, Marc Andreessen, người đồng phát minh trình duyệt web Khảm và hiện là nhà đầu tư hàng đầu tại Andreessen Horowitz, đã viết, “Deepseek R1 là một trong những đột phá tuyệt vời và ấn tượng nhất mà tôi từng thấy — và là nguồn mở, một bước đột phá sâu sắc. món quà cho thế giới.”
Deepseek R1 là một trong những bước đột phá tuyệt vời và ấn tượng nhất mà tôi từng thấy — và là nguồn mở, một món quà sâu sắc cho thế giới. 🤖🫡
— Marc Andreessen 🇺🇸 (@pmarca) Ngày 24 tháng 1 năm 2025
Yann LeCun, Nhà khoa học trưởng về AI tại Meta, lưu ý trên LinkedIn rằng mặc dù thành tích của DeepSeek có vẻ cho thấy Trung Quốc vượt qua Hoa Kỳ, nhưng sẽ chính xác hơn khi nói rằng các mô hình nguồn mở nói chung đang bắt kịp các giải pháp thay thế độc quyền.
“DeepSeek đã thu được lợi nhuận từ nghiên cứu mở và nguồn mở (ví dụ: PyTorch và Llama từ Meta),” ông giải thích. “Họ nảy ra những ý tưởng mới và xây dựng chúng dựa trên thành quả của người khác. Bởi vì tác phẩm của họ được xuất bản và là nguồn mở nên mọi người đều có thể thu lợi từ nó. Đó là sức mạnh của nghiên cứu mở và nguồn mở.”
Xem trên Chủ đề
Ngay cả Mark Zuckerberg, người sáng lập và Giám đốc điều hành của Meta, cũng đã gợi ý về một con đường khác bằng cách công bố các khoản đầu tư lớn vào trung tâm dữ liệu và cơ sở hạ tầng GPU
Nhận xét của Zuckerberg cho thấy các chiến lược sử dụng nhiều tài nguyên vẫn là động lực chính trong việc định hình lĩnh vực AI.
Liên quan: LLaMA AI Under Fire – Meta không nói gì với bạn về các mô hình “Nguồn mở”
Tác động mở rộng và triển vọng trong tương lai
Đối với DeepSeek, sự kết hợp giữa tài năng địa phương, sớm Dự trữ GPU và sự nhấn mạnh vào các phương pháp nguồn mở đã đưa nó trở thành tâm điểm chú ý thường dành cho những gã khổng lồ công nghệ lớn. Vào tháng 7 năm 2024, Liang tuyên bố rằng nhóm của ông nhằm mục đích giải quyết cái mà ông gọi là khoảng cách về hiệu quả trong AI Trung Quốc.
Ông mô tả rằng nhiều công ty AI địa phương cần gấp đôi sức mạnh tính toán để phù hợp với kết quả ở nước ngoài, điều đó càng trở nên phức tạp hơn khi tính đến việc sử dụng dữ liệu. Lợi nhuận của quỹ phòng hộ từ High-Flyer mang lại cho DeepSeek một tấm đệm chống lại áp lực thương mại ngay lập tức, cho phép Liang và các kỹ sư của ông tập trung vào các ưu tiên nghiên cứu. Liang cho biết:
“Chúng tôi ước tính rằng các mô hình trong và ngoài nước tốt nhất có thể có khoảng cách gấp một lần về cơ cấu mô hình và động lực đào tạo. Chỉ vì lý do này mà chúng ta cần tiêu thụ sức mạnh tính toán gấp đôi để đạt được hiệu quả tương tự.
Ngoài ra, cũng có thể có khoảng cách gấp một lần về hiệu quả dữ liệu, tức là chúng ta cần tiêu thụ gấp đôi lượng dữ liệu đào tạo và sức mạnh tính toán để đạt được hiệu quả tương tự. Cùng nhau, chúng ta cần tiêu thụ sức mạnh tính toán gấp bốn lần. Điều chúng ta cần làm là liên tục thu hẹp những khoảng cách này.”
Danh tiếng của DeepSeek ở Trung Quốc cũng được nâng cao khi Liang trở thành nhà lãnh đạo AI duy nhất được mời tham dự cuộc họp cấp cao với Li Qiang, nhà lãnh đạo AI thứ hai của đất nước. quan chức quyền lực nhất, nơi ông được khuyến khích tập trung vào xây dựng các công nghệ cốt lõi
Các nhà phân tích coi đây là một tín hiệu nữa cho thấy Bắc Kinh đang đặt cược nhiều vào các nhà đổi mới cây nhà lá vườn nhỏ hơn để đẩy các ranh giới AI dưới những hạn chế về phần cứng.
Trong khi tương lai vẫn chưa chắc chắn—đặc biệt là khi các hạn chế của Hoa Kỳ có thể được thắt chặt hơn nữa—DeepSeek nổi bật trong việc giải quyết các thách thức theo cách biến những hạn chế thành con đường giải quyết vấn đề nhanh chóng
Bằng cách công khai những đột phá của mình và cung cấp các kỹ thuật đào tạo quy mô nhỏ hơn. công ty khởi nghiệp này đã thúc đẩy các cuộc thảo luận rộng rãi hơn về việc liệu hiệu quả tài nguyên có thể sánh ngang với các cụm siêu máy tính khổng lồ hay không
Khi DeepSeek tiếp tục hoàn thiện R1, các kỹ sư và nhà hoạch định chính sách ở cả hai bờ Thái Bình Dương đang theo dõi chặt chẽ để xem liệu thành tựu của mô hình này có thể đạt được hay không. mở đường bền vững cho sự phát triển của AI trong thời đại ngày càng có nhiều hạn chế.