Phòng thí nghiệm trí tuệ nhân tạo Trung Quốc DeepSeek đã giới thiệu DeepSeek V3, mô hình ngôn ngữ nguồn mở tiếp theo của nó. Với 671 tỷ tham số, mô hình này sử dụng kiến trúc được gọi là Hỗn hợp các chuyên gia (MoE) để kết hợp hiệu quả tính toán với hiệu suất cao.
Những tiến bộ kỹ thuật của DeepSeek V3 khiến nó trở thành một trong những hệ thống AI mạnh mẽ nhất, cạnh tranh với cả các đối thủ cạnh tranh nguồn mở như Llama 3.1 của Meta và các mô hình độc quyền như GPT-4o của OpenAI.
Bản phát hành nêu bật một thời điểm quan trọng trong AI, chứng minh rằng các hệ thống nguồn mở có thể cạnh tranh—và trong một số trường hợp tốt hơn—tốn kém hơn, các lựa chọn thay thế khép kín.
Liên quan:
Mô hình xem trước DeepSeek R1-Lite-Lite của Trung Quốc nhắm đến vị trí dẫn đầu của OpenAI trong khả năng suy luận tự động
Alibaba Qwen phát hành Mô hình AI suy luận đa phương thức QVQ-72B-Preview
Kiến trúc hiệu quả và sáng tạo
Kiến trúc của DeepSeek V3 kết hợp hai khái niệm nâng cao để đạt được hiệu quả và hiệu suất vượt trội: Sự chú ý tiềm ẩn nhiều đầu (MLA) và Hỗn hợp các chuyên gia (MoE).
MLA nâng cao khả năng của mô hình trong việc xử lý các thông tin đầu vào phức tạp bằng cách sử dụng nhiều đầu chú ý để tập trung vào các khía cạnh khác nhau của dữ liệu, trích xuất thông tin theo ngữ cảnh phong phú và đa dạng.
Mặt khác, MoE chỉ kích hoạt một tập hợp con trong tổng số 671 tỷ tham số của mô hình—khoảng 37 tỷ cho mỗi nhiệm vụ—đảm bảo rằng các tài nguyên tính toán được sử dụng hiệu quả mà không cần làm tổn hại đến độ chính xác. Cùng với nhau, các cơ chế này cho phép DeepSeek V3 mang lại kết quả đầu ra chất lượng cao đồng thời giảm nhu cầu về cơ sở hạ tầng.
Giải quyết những thách thức chung trong hệ thống MoE, chẳng hạn như phân bổ khối lượng công việc không đồng đều giữa các chuyên gia, DeepSeek đã giới thiệu một giải pháp tải phụ trợ không mất mát-chiến lược cân bằng. Phương pháp động này phân bổ nhiệm vụ trên mạng lưới các chuyên gia, duy trì tính nhất quán và tối đa hóa độ chính xác của nhiệm vụ.
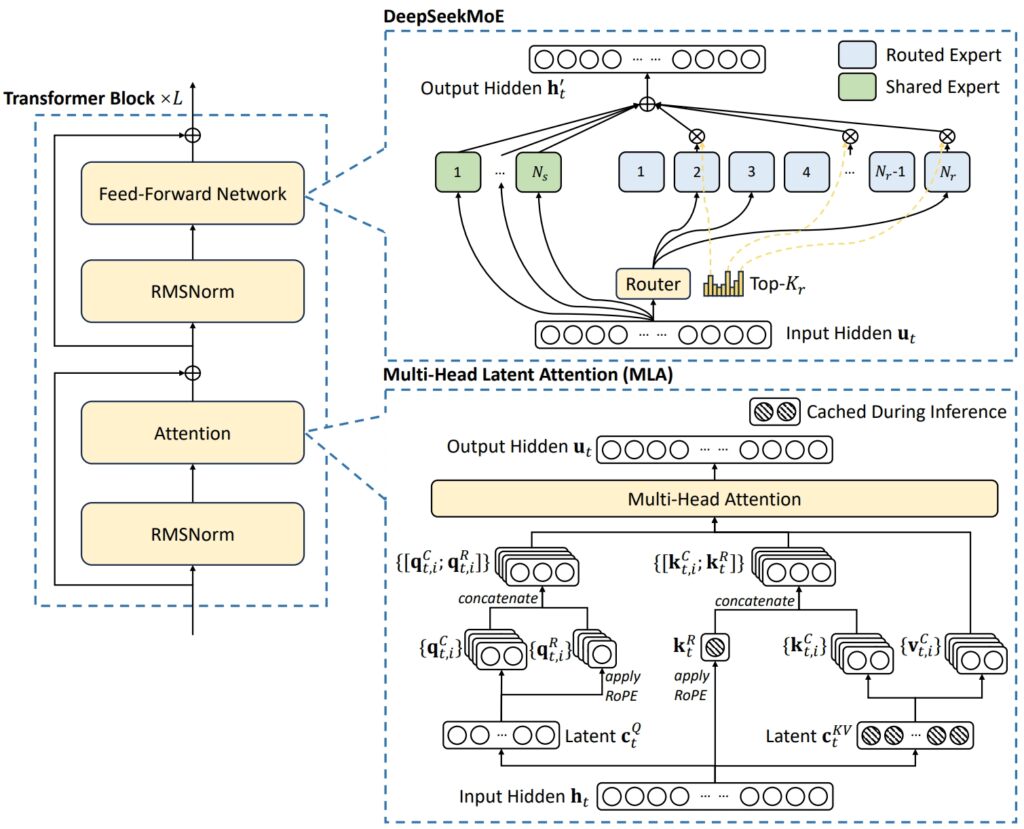 Minh họa kiến trúc cơ bản của DeepSeek-V3 (Ảnh: DeepSeek)
Minh họa kiến trúc cơ bản của DeepSeek-V3 (Ảnh: DeepSeek)
Để nâng cao hơn nữa hiệu quả, DeepSeek V3 sử dụng Dự đoán nhiều mã thông báo (MTP), một tính năng cho phép mô hình tạo nhiều mã thông báo đồng thời, tăng tốc đáng kể việc tạo văn bản.
Tính năng này không chỉ cải thiện hiệu quả đào tạo mà còn định vị mô hình cho các ứng dụng trong thế giới thực nhanh hơn, củng cố vị thế của nó với tư cách là người đi đầu trong đổi mới AI nguồn mở.
Hiệu suất điểm chuẩn: Người dẫn đầu về Toán học và Mã hóa
Kết quả điểm chuẩn của DeepSeek V3 cho thấy khả năng vượt trội của nó trên một phạm vi rộng các nhiệm vụ, củng cố vị thế của mình như dẫn đầu trong số các mô hình AI nguồn mở.
Tận dụng kiến trúc tiên tiến và tập dữ liệu đào tạo mở rộng, mô hình này đã đạt được hiệu suất hàng đầu về các tiêu chuẩn toán học, mã hóa và đa ngôn ngữ, đồng thời mang lại kết quả cạnh tranh trong các lĩnh vực mà các mô hình nguồn đóng thường thống trị như GPT của OpenAI-4o và Sonnet Claude 3.5 của Anthropic.
🚀 Giới thiệu DeepSeek-V3!
Bước nhảy vọt lớn nhất từ trước đến nay:
⚡ 60 token/giây (nhanh gấp 3 lần so với V2!)
💪 Khả năng nâng cao
🛠 Khả năng tương thích API còn nguyên vẹn
🌍 Các mô hình và giấy tờ nguồn mở hoàn toàn🐋 1/n pic.twitter.com/p1dV9gJ2Sd
— DeepSeek (@deepseek_ai) Ngày 26 tháng 12 năm 2024
Lý luận toán học
Về Bài kiểm tra Math-500, một chuẩn mực được thiết kế để đánh giá kỹ năng giải quyết vấn đề toán học, DeepSeek V3 đạt được số điểm ấn tượng là 90,2. Điểm số này giúp nó vượt lên trên tất cả các đối thủ cạnh tranh nguồn mở, với Qwen 2.5 đạt 80 điểm và Llama 3.1 xếp sau ở mức 73,8. Ngay cả GPT-4o, một mẫu mã nguồn đóng nổi tiếng với các khả năng chung, cũng đạt điểm thấp hơn một chút ở mức 74,6. Hiệu suất này nhấn mạnh khả năng suy luận nâng cao của DeepSeek V3, đặc biệt là trong các nhiệm vụ tính toán chuyên sâu trong đó độ chính xác và logic là rất quan trọng.
Ngoài ra, DeepSeek V3 còn xuất sắc trong các bài kiểm tra toán học cụ thể khác, chẳng hạn như:
MGSM (Toán học cấp lớp Toán): Đạt 79,8, vượt qua Llama 3,1 (69,9) và Qwen 2,5 (76,2). CMath (Toán Trung Quốc): Đạt 90,7 điểm, vượt trội so với cả Llama 3.1 (77,3) và GPT-4o (84,5).
Những kết quả này không chỉ nêu bật sức mạnh của nó trong lý luận toán học dựa trên tiếng Anh mà còn trong các nhiệm vụ yêu cầu giải quyết vấn đề bằng số theo ngôn ngữ cụ thể.
Có liên quan: Chuỗi mô hình ngôn ngữ tầm nhìn VL2 mã nguồn mở DeepSeek AI
Lập trình và mã hóa
DeepSeek V3 đã thể hiện sự vượt trội năng lực trong việc viết mã và các tiêu chuẩn giải quyết vấn đề. Trên Codeforces, một nền tảng lập trình cạnh tranh, mô hình này đã đạt được xếp hạng phần trăm 51,6, phản ánh khả năng xử lý các tác vụ thuật toán phức tạp. Hiệu suất này vượt xa đáng kể các đối thủ nguồn mở như Llama 3.1, chỉ đạt 25,3, và thậm chí thách thức Claude 3.5 Sonnet, có tỷ lệ phần trăm thấp hơn. Thành công của mô hình này còn được xác nhận rõ hơn nhờ điểm số cao trong các tiêu chuẩn dành riêng cho mã hóa:
HumanEval-Mul: Đạt 82,6 điểm, vượt trội so với Qwen 2,5 (77,3) và sánh ngang với GPT-4o (80,5). LiveCodeBench (Pass@1): Đạt 37,6 điểm, trước Llama 3.1 (30,1) và Claude 3,5 Sonnet (32,8). CRUXEval-I: Đạt 67,3 điểm, tốt hơn đáng kể so với cả Qwen 2.5 (59,1) và Llama 3.1 (58,5).
Những kết quả này nêu bật tính phù hợp của mô hình đối với các ứng dụng trong phát triển phần mềm và môi trường mã hóa trong thế giới thực, trong đó việc giải quyết vấn đề và tạo mã hiệu quả là điều tối quan trọng.
Nhiệm vụ đa ngôn ngữ và không phải tiếng Anh
strong>
DeepSeek V3 còn nổi bật ở các bài benchmark đa ngôn ngữ, thể hiện khả năng xử lý và hiểu nhiều loại ngôn ngữ. Trong bài kiểm tra CMMLU (Hiểu ngôn ngữ đa ngôn ngữ tiếng Trung), mô hình này đã đạt được số điểm đặc biệt là 88,8, vượt qua Qwen 2,5 (89,5) và thống trị Llama 3.1 tụt lại phía sau ở mức 73,7. Tương tự, trên C-Eval, điểm chuẩn đánh giá của Trung Quốc, DeepSeek V3 đạt 90,1 điểm, vượt xa Llama 3.1 (72,5).
Trong các nhiệm vụ đa ngôn ngữ không phải tiếng Anh:
Điểm chuẩn dành riêng cho tiếng Anh
Trong khi DeepSeek V3 vượt trội về toán, mã hóa và hiệu suất đa ngôn ngữ, kết quả của nó trong một số tiêu chuẩn cụ thể bằng tiếng Anh phản ánh chỗ cần cải thiện. Ví dụ: trên điểm chuẩn SimpleQA, đánh giá khả năng của mô hình trong việc trả lời các câu hỏi thực tế đơn giản bằng tiếng Anh, DeepSeek V3 đạt 24,9 điểm , tụt lại phía sau GPT-4o, đạt 38,2. Tương tự, trên FRAMES, một điểm chuẩn để hiểu các cấu trúc tường thuật phức tạp, GPT-4o đạt 80,5 điểm, so với 73,3 của DeepSeek.
Bất chấp những khoảng trống này, hiệu suất của mô hình vẫn có tính cạnh tranh cao, đặc biệt nhờ tính chất nguồn mở và hiệu quả chi phí. Sự kém hiệu quả nhẹ trong các nhiệm vụ dành riêng cho tiếng Anh được bù đắp bằng sự thống trị của nó trong các điểm chuẩn toán và đa ngôn ngữ, những lĩnh vực mà nó luôn thách thức và thường vượt qua các đối thủ nguồn đóng.
Kết quả điểm chuẩn của DeepSeek V3 không chỉ thể hiện sự tinh tế về mặt kỹ thuật mà còn cũng định vị nó là một mẫu máy linh hoạt, có hiệu suất cao cho nhiều nhiệm vụ. Sự vượt trội của nó về các điểm chuẩn toán, mã hóa và đa ngôn ngữ làm nổi bật điểm mạnh của nó, trong khi kết quả cạnh tranh trong các nhiệm vụ tiếng Anh cho thấy khả năng cạnh tranh với các công ty dẫn đầu ngành như GPT-4o và Claude 3.5 Sonnet.
Bằng cách cung cấp những kết quả này với chi phí thấp hơn so với các hệ thống độc quyền, DeepSeek V3 minh họa tiềm năng của AI nguồn mở để cạnh tranh—và trong một số trường hợp còn vượt trội hơn—các lựa chọn thay thế nguồn đóng.
Có liên quan: Apple lên kế hoạch triển khai AI tại Trung Quốc thông qua Tencent và ByteDance
Đào tạo hiệu quả về chi phí trên quy mô lớn
One những thành tựu nổi bật của DeepSeek V3 là quy trình đào tạo tiết kiệm chi phí. Mô hình này được đào tạo trên tập dữ liệu gồm 14,8 nghìn tỷ mã thông báo sử dụng GPU Nvidia H800, với tổng thời gian đào tạo là 2,788 triệu giờ GPU. Tổng chi phí lên tới 5,576 triệu USD, một phần nhỏ trong số 500 triệu USD ước tính cần thiết để đào tạo Llama 3.1 của Meta.
GPU NVIDIA H800 là phiên bản sửa đổi của GPU H100 được thiết kế cho thị trường Trung Quốc để tuân thủ tiêu chuẩn xuất khẩu quy định. Cả hai GPU đều dựa trên kiến trúc Hopper của NVIDIA và chủ yếu được sử dụng cho AI và các ứng dụng điện toán hiệu năng cao. Tốc độ truyền dữ liệu từ chip này sang chip khác của H800 giảm xuống còn khoảng một nửa so với H100
Quá trình đào tạo sử dụng các phương pháp tiên tiến, bao gồm cả đào tạo chính xác hỗn hợp FP8. Cách tiếp cận này làm giảm mức sử dụng bộ nhớ bằng cách mã hóa dữ liệu ở định dạng dấu phẩy động 8 bit mà không làm giảm độ chính xác. Ngoài ra, thuật toán DualPipe đã tối ưu hóa tính song song của đường dẫn, đảm bảo sự phối hợp trơn tru giữa các cụm GPU.
DeepSeek cho biết rằng DeepSeek-V3 đào tạo trước chỉ cần 180.000 giờ GPU H800 trên mỗi nghìn tỷ mã thông báo, sử dụng cụm 2.048 GPU.
Khả năng truy cập và triển khai
DeepSeek đã cung cấp V3 theo giấy phép của MIT, cung cấp cho các nhà phát triển quyền truy cập vào mô hình cho cả ứng dụng nghiên cứu và thương mại. Các doanh nghiệp có thể tích hợp mô hình này thông qua nền tảng hoặc API DeepSeek Chat, với mức giá cạnh tranh là 0,27 USD trên một triệu mã thông báo đầu vào và 1,10 USD trên một triệu mã thông báo đầu ra.
Tính linh hoạt của mô hình còn mở rộng đến khả năng tương thích với nhiều nền tảng phần cứng khác nhau, bao gồm cả GPU AMD và NPU Huawei Ascend. Điều này đảm bảo khả năng tiếp cận rộng rãi cho các nhà nghiên cứu và tổ chức có nhu cầu cơ sở hạ tầng đa dạng.
DeepSeek nhấn mạnh sự tập trung vào độ tin cậy và hiệu suất, cho biết: “Để đảm bảo tuân thủ SLO và thông lượng cao, chúng tôi sử dụng chiến lược dự phòng năng động cho các chuyên gia trong giai đoạn điền trước, trong đó các chuyên gia có tải trọng cao được sao chép và sắp xếp lại định kỳ để có hiệu suất tối ưu.”
Ý nghĩa rộng hơn đối với Hệ sinh thái AI
Việc phát hành DeepSeek V3 nhấn mạnh xu hướng rộng lớn hơn hướng tới dân chủ hóa AI. Bằng cách cung cấp mô hình hiệu suất cao với chi phí thấp hơn so với các hệ thống độc quyền, DeepSeek đang thách thức sự thống trị của những công ty nguồn đóng như OpenAI và Anthropic. Sự sẵn có của các công cụ tiên tiến như vậy cho phép thử nghiệm và đổi mới rộng rãi hơn trong nhiều ngành.
Quy trình của DeepSeek kết hợp các mẫu xác minh và phản ánh từ mô hình R1 của nó vào DeepSeek-V3, cải thiện khả năng suy luận trong khi vẫn duy trì quyền kiểm soát kiểu và độ dài đầu ra.
Sự thành công của DeepSeek V3 đặt ra câu hỏi về tương lai THĂNG BẰNG quyền lực trong ngành công nghiệp AI. Khi các mô hình nguồn mở tiếp tục thu hẹp khoảng cách với các hệ thống độc quyền, chúng cung cấp cho các tổ chức các giải pháp thay thế cạnh tranh ưu tiên khả năng tiếp cận và hiệu quả chi phí.