Các nhà nghiên cứu tại Sakana AI, một công ty khởi nghiệp về AI có trụ sở tại Tokyo, đã giới thiệu một hệ thống tối ưu hóa bộ nhớ mới giúp nâng cao hiệu quả của các mô hình dựa trên Transformer, bao gồm cả các mô hình ngôn ngữ lớn (LLM).
Phương pháp được gọi là Mô hình bộ nhớ chú ý thần kinh (NAMM) có sẵn thông qua mã đào tạo đầy đủ trên GitHub, giảm mức sử dụng bộ nhớ tới 75% đồng thời cải thiện hiệu suất tổng thể. Bằng cách tập trung vào các mã thông báo thiết yếu và loại bỏ thông tin dư thừa, NAMM giải quyết một trong những thách thức tiêu tốn nhiều tài nguyên nhất trong AI hiện đại: quản lý các cửa sổ ngữ cảnh dài.
Các mô hình biến áp, xương sống của LLM, dựa vào “cửa sổ ngữ cảnh”để xử lý dữ liệu đầu vào. Các cửa sổ ngữ cảnh này lưu trữ “cặp khóa-giá trị” (bộ đệm KV) cho mọi mã thông báo trong chuỗi đầu vào.
Khi thời lượng cửa sổ tăng lên—hiện đạt tới hàng trăm nghìn mã thông báo—thì chi phí tính toán tăng vọt. Các giải pháp trước đây đã cố gắng giảm chi phí này thông qua việc cắt bớt mã thông báo thủ công hoặc các chiến lược phỏng đoán nhưng thường làm giảm hiệu suất. Tuy nhiên, NAMM sử dụng mạng thần kinh được đào tạo thông qua tối ưu hóa tiến hóa để tự động hóa và tinh chỉnh quy trình quản lý bộ nhớ.
Tối ưu hóa bộ nhớ với NAMM
NAMM phân tích các giá trị chú ý do Transformers tạo ra để xác định tầm quan trọng của mã thông báo. Họ xử lý các giá trị này thành biểu đồ phổ—biểu diễn dựa trên tần số thường được sử dụng trong xử lý âm thanh và tín hiệu—để nén và trích xuất các tính năng chính của mẫu chú ý.
Thông tin này sau đó được chuyển qua một mạng lưới thần kinh nhẹ để gán điểm cho từng mã thông báo, quyết định xem nên giữ lại hay loại bỏ nó.
Sakana AI nêu bật cách các thuật toán tiến hóa thúc đẩy NAMM’thành công. Không giống như các phương pháp dựa trên độ dốc truyền thống, không tương thích với các quyết định nhị phân như “nhớ” hoặc “quên”, tối ưu hóa tiến hóa kiểm tra lặp đi lặp lại và tinh chỉnh các chiến lược bộ nhớ để tối đa hóa hiệu suất xuôi dòng.
“Sự tiến hóa vốn đã khắc phục được tính không khác biệt các hoạt động quản lý bộ nhớ của chúng tôi, liên quan đến kết quả nhị phân’ghi nhớ’hoặc’quên'”, các nhà nghiên cứu giải thích.
Kết quả đã được chứng minh qua các điểm chuẩn
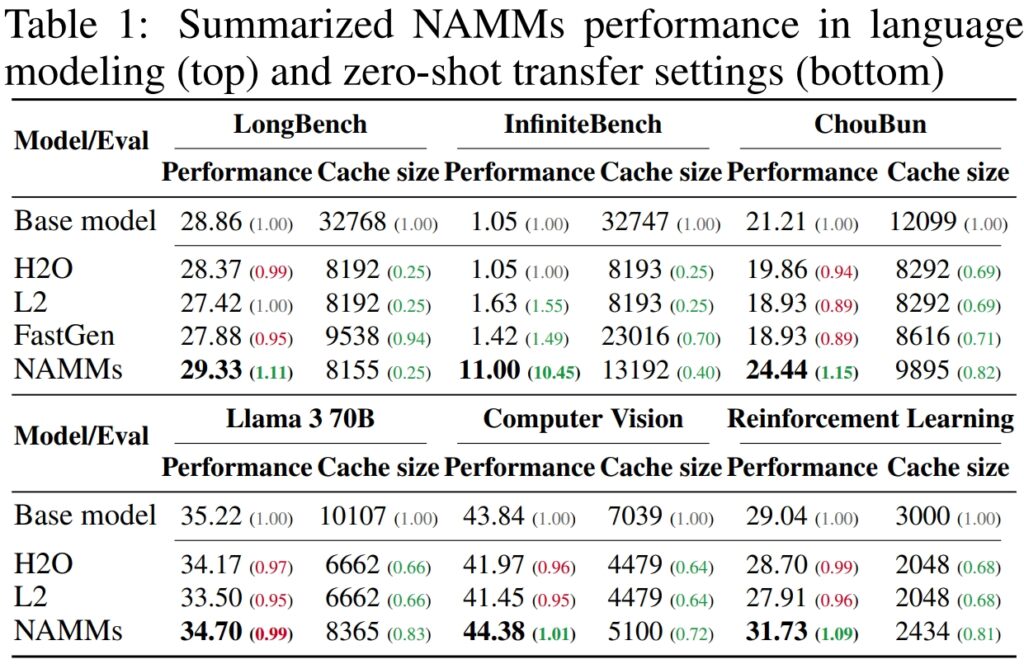
Để xác thực hiệu suất và hiệu quả của Mô hình bộ nhớ chú ý thần kinh (NAMM), Sakana AI đã tiến hành thử nghiệm rộng rãi trên nhiều điểm chuẩn hàng đầu trong ngành được thiết kế để đánh giá khả năng xử lý ngữ cảnh dài và đa tác vụ, chứng minh khả năng của NAMM trong việc cải thiện đáng kể hiệu suất đồng thời giảm yêu cầu về bộ nhớ. hiệu quả của chúng trên các khung đánh giá đa dạng.
Trên LongBench, điểm chuẩn được tạo riêng để đo lường hiệu suất của các mô hình trong bối cảnh dài nhiệm vụ, NAMM đã đạt được mức cải thiện độ chính xác 11% so với mô hình cơ sở toàn ngữ cảnh. Cải tiến này đạt được đồng thời giảm mức sử dụng bộ nhớ xuống 75%, làm nổi bật tính hiệu quả của phương pháp trong việc quản lý bộ nhớ đệm khóa-giá trị (KV).
Bằng cách cắt bớt các mã thông báo ít liên quan hơn một cách thông minh, NAMM cho phép mô hình tập trung vào bối cảnh quan trọng mà không làm mất đi kết quả, khiến mô hình trở nên lý tưởng cho các tình huống yêu cầu đầu vào mở rộng, chẳng hạn như phân tích tài liệu hoặc trả lời câu hỏi dạng dài.
Đối với InfiniteBench, một điểm chuẩn đẩy các mô hình đến giới hạn của chúng với các chuỗi cực kỳ dài— một số vượt quá 200.000 token—NAMM đã thể hiện khả năng mở rộng quy mô hiệu quả.
Trong khi các mô hình cơ sở gặp khó khăn với nhu cầu tính toán của dữ liệu đầu vào dài như vậy thì NAMM đã đạt được hiệu suất tăng đáng kể, tăng độ chính xác từ 1,05% lên 11,00%.
Kết quả này đặc biệt đáng chú ý vì nó thể hiện khả năng xử lý các ngữ cảnh siêu dài của NAMM, một khả năng ngày càng cần thiết cho các ứng dụng như xử lý tài liệu khoa học, tài liệu pháp lý hoặc kho lưu trữ mã lớn nơi kích thước đầu vào mã thông báo là rất lớn.
Trên điểm chuẩn ChouBun của Sakana AI, đánh giá lý luận theo ngữ cảnh dài cho các tác vụ tiếng Nhật, NAMM đã đưa ra một Cải thiện 15% so với mức cơ bản. ChouBun giải quyết lỗ hổng trong các tiêu chuẩn hiện có, vốn có xu hướng tập trung vào ngôn ngữ tiếng Anh và tiếng Trung, bằng cách thử nghiệm các mô hình trên đầu vào văn bản tiếng Nhật mở rộng.
Sự thành công của NAMM trên ChouBun làm nổi bật tính linh hoạt của chúng trên nhiều ngôn ngữ và chứng tỏ tính mạnh mẽ của chúng trong việc xử lý các đầu vào không phải tiếng Anh—một tính năng chính cho các ứng dụng AI toàn cầu. NAMM có thể giữ lại nội dung theo ngữ cảnh cụ thể một cách hiệu quả trong khi loại bỏ các lỗi ngữ pháp dư thừa và mã thông báo ít ý nghĩa hơn, cho phép mô hình thực hiện hiệu quả hơn các nhiệm vụ như tóm tắt dạng dài và hiểu bằng tiếng Nhật.
 Nguồn: Sakana AI
Nguồn: Sakana AI
The các kết quả chung chứng minh rằng NAMM vượt trội trong việc tối ưu hóa việc sử dụng bộ nhớ mà không ảnh hưởng đến độ chính xác. Cho dù được đánh giá dựa trên các nhiệm vụ yêu cầu trình tự cực kỳ dài hay trên các bối cảnh ngôn ngữ không phải tiếng Anh, NAMM luôn hoạt động tốt hơn các mô hình cơ sở, đạt được cả hiệu quả tính toán và kết quả được cải thiện.
Sự kết hợp giữa tiết kiệm bộ nhớ và độ chính xác này giúp NAMM trở thành một tiến bộ vượt bậc cho các hệ thống AI doanh nghiệp được giao nhiệm vụ xử lý dữ liệu đầu vào rộng lớn và phức tạp.
Kết quả đặc biệt đáng chú ý so với các phương pháp trước đây như H₂O và L2, hy sinh hiệu suất để lấy hiệu quả. Mặt khác, NAMM đạt được cả hai.
“Kết quả của chúng tôi chứng minh rằng NAMM cung cấp thành công những cải tiến nhất quán trên cả trục hiệu suất và hiệu suất so với Máy biến áp cơ bản”, các nhà nghiên cứu cho biết.
Ứng dụng đa phương thức: Ngoài ngôn ngữ
Một trong những phát hiện ấn tượng nhất là khả năng của NAMM trong việc chuyển zero-shot sang các nhiệm vụ và phương thức đầu vào khác
. Một trong những khía cạnh đáng chú ý nhất của thần kinh Mô hình bộ nhớ chú ý (NAMM) là khả năng chuyển đổi liền mạch giữa các tác vụ và phương thức đầu vào khác nhau—ngoài các ứng dụng dựa trên ngôn ngữ truyền thống
Không giống như các phương pháp tối ưu hóa bộ nhớ khác thường yêu cầu đào tạo lại hoặc tinh chỉnh cho từng miền. , NAMM duy trì các lợi ích về hiệu quả và hiệu suất mà không cần điều chỉnh thêm. Các thử nghiệm của Sakana AI đã thể hiện tính linh hoạt này trong hai lĩnh vực chính: thị giác máy tính và học tăng cường, cả hai đều đặt ra những thách thức riêng cho các mô hình dựa trên Transformer.
 NAMM được đào tạo về ngôn ngữ có thể bằng 0-bắn được chuyển đến các máy biến áp khác qua các phương thức đầu vào và miền nhiệm vụ. (Hình ảnh: Sakana AI)
NAMM được đào tạo về ngôn ngữ có thể bằng 0-bắn được chuyển đến các máy biến áp khác qua các phương thức đầu vào và miền nhiệm vụ. (Hình ảnh: Sakana AI)
Trong thị giác máy tính, NAMM được đánh giá bằng cách sử dụng mô hình Video tiếp theo của Llava, một Máy biến áp được thiết kế để xử lý các chuỗi video dài. Video vốn chứa một lượng lớn dữ liệu dư thừa, chẳng hạn như các khung hình lặp lại hoặc các biến thể nhỏ cung cấp ít thông tin bổ sung.
NAMM tự động xác định và loại bỏ các khung dư thừa này trong quá trình suy luận, nén cửa sổ ngữ cảnh một cách hiệu quả mà không ảnh hưởng đến khả năng diễn giải nội dung video của mô hình.
Ví dụ: NAMM giữ lại các khung có các chi tiết hình ảnh quan trọng—chẳng hạn như các thay đổi về hành động, tương tác đối tượng hoặc các sự kiện quan trọng—trong khi loại bỏ các khung lặp lại hoặc tĩnh. Điều này dẫn đến hiệu quả xử lý được cải thiện, cho phép mô hình tập trung vào các yếu tố trực quan phù hợp nhất, do đó duy trì độ chính xác trong khi giảm chi phí tính toán.
Trong học tăng cường, NAMM được áp dụng cho Bộ chuyển đổi quyết định, một mô hình được thiết kế để xử lý chuỗi hành động, quan sát và phần thưởng nhằm tối ưu hóa các nhiệm vụ ra quyết định. Nhiệm vụ học tăng cường thường liên quan đến chuỗi đầu vào dài với mức độ liên quan khác nhau, trong đó các hành động dưới mức tối ưu hoặc dư thừa có thể cản trở hiệu suất.
NAMM đã giải quyết thách thức này bằng cách loại bỏ có chọn lọc các mã thông báo tương ứng với các hành động kém hiệu quả và thông tin có giá trị thấp trong khi vẫn giữ lại những thông tin quan trọng để đạt được kết quả tốt hơn.
Ví dụ: trong các tác vụ như Hopper và Walker2d—liên quan đến việc kiểm soát các tác nhân ảo trong chuyển động liên tục—NAMM đã cải thiện hiệu suất hơn 9%. Bằng cách lọc ra các chuyển động dưới mức tối ưu hoặc các chi tiết không cần thiết, Công cụ chuyển đổi quyết định đã đạt được hiệu suất học tập hiệu quả hơn, tập trung sức mạnh tính toán vào các quyết định giúp tối đa hóa thành công trong nhiệm vụ.
Những kết quả này nêu bật khả năng thích ứng của NAMM trên nhiều lĩnh vực khác nhau. Cho dù xử lý khung hình video trong mô hình thị giác hay tối ưu hóa chuỗi hành động trong học tăng cường, NAMM đều thể hiện khả năng nâng cao hiệu suất, giảm mức sử dụng tài nguyên và duy trì độ chính xác của mô hình—tất cả mà không cần đào tạo lại.
NAMM học cách quên hầu hết các phần của các khung hình video dư thừa, thay vì các mã thông báo ngôn ngữ mô tả lời nhắc cuối cùng, bài viết ghi chú, nêu bật khả năng thích ứng của NAMM.
Nền tảng kỹ thuật của NAMM
Hiệu lực và hiệu quả của Mô hình bộ nhớ chú ý thần kinh (NAMM) nằm ở quy trình thực thi có hệ thống và hợp lý, cho phép cắt bớt mã thông báo chính xác mà không cần can thiệp thủ công. Quá trình này được xây dựng trên ba thành phần cốt lõi: biểu đồ phổ chú ý, tính năng nén và tính điểm tự động.
NAMM tự động điều chỉnh hành vi của chúng tùy thuộc vào yêu cầu nhiệm vụ và độ sâu của lớp Transformer. Các lớp đầu tiên ưu tiên bối cảnh “toàn cầu” như mô tả nhiệm vụ, trong khi các lớp sâu hơn giữ lại các chi tiết cụ thể về nhiệm vụ “cục bộ”. Ví dụ: trong các tác vụ mã hóa, NAMM đã loại bỏ các nhận xét và mã soạn sẵn; trong các nhiệm vụ ngôn ngữ tự nhiên, họ đã loại bỏ sự dư thừa về mặt ngữ pháp trong khi vẫn giữ lại nội dung chính.
Việc lưu giữ mã thông báo thích ứng này đảm bảo rằng các mô hình vẫn tập trung vào thông tin có liên quan trong suốt quá trình xử lý, cải thiện tốc độ và độ chính xác.
Đầu tiên bước này liên quan đến việc tạo Biểu đồ phổ chú ý. Máy biến áp tính toán “giá trị chú ý” ở mỗi lớp để xác định tầm quan trọng tương đối của từng mã thông báo trong cửa sổ ngữ cảnh. NAMM chuyển đổi các giá trị chú ý này thành biểu diễn dựa trên tần số bằng cách sử dụng Biến đổi Fourier thời gian ngắn (STFT).
STFT là một kỹ thuật xử lý tín hiệu được sử dụng rộng rãi, chia chuỗi thành các thành phần tần số cục bộ theo thời gian, cung cấp sự thể hiện ngắn gọn nhưng chi tiết về tầm quan trọng của mã thông báo. Bằng cách áp dụng STFT, NAMM chuyển đổi các chuỗi chú ý thô thành dữ liệu giống như biểu đồ phổ, cho phép thực hiện một phân tích rõ ràng hơn về những mã thông báo nào đóng góp có ý nghĩa cho đầu ra của mô hình.
Tiếp theo, Nén tính năng được áp dụng để giảm kích thước của dữ liệu phổ trong khi vẫn duy trì các đặc điểm thiết yếu của nó. một đường trung bình động hàm mũ (EMA), một phương pháp toán học nén các mẫu chú ý lịch sử thành một bản tóm tắt nhỏ gọn, có kích thước cố định. EMA đảm bảo rằng các biểu diễn vẫn nhẹ và có thể quản lý được, cho phép NAMM phân tích các chuỗi chú ý dài một cách hiệu quả đồng thời giảm thiểu chi phí tính toán.
Bước cuối cùng là Cho điểm và Cắt tỉa, trong đó NAMM sử dụng một thuật toán nhẹ bộ phân loại mạng thần kinh để đánh giá các biểu diễn mã thông báo được nén và ấn định điểm dựa trên tầm quan trọng của chúng. Các mã thông báo có điểm dưới ngưỡng xác định sẽ bị loại bỏ khỏi cửa sổ ngữ cảnh,”quên”các chi tiết không hữu ích hoặc dư thừa một cách hiệu quả. Cơ chế tính điểm này cho phép NAMM ưu tiên các mã thông báo quan trọng góp phần vào quá trình ra quyết định của mô hình trong khi loại bỏ dữ liệu ít liên quan hơn.
Điều khiến NAMM đặc biệt hiệu quả là việc chúng dựa vào tối ưu hóa tiến hóa để tinh chỉnh quy trình này như các phương pháp tối ưu hóa truyền thống như giảm độ dốc gặp khó khăn với các nhiệm vụ không thể phân biệt—chẳng hạn như quyết định xem nên giữ lại hay không một mã thông báo. bị loại bỏ
Thay vào đó, NAMM sử dụng thuật toán tiến hóa lặp đi lặp lại, lấy cảm hứng từ chọn lọc tự nhiên, để”biến đổi”và”chọn lọc”các chiến lược quản lý bộ nhớ hiệu quả nhất theo thời gian. Thông qua các thử nghiệm lặp đi lặp lại, hệ thống sẽ phát triển để ưu tiên các chiến lược thiết yếu. tự động mã thông báo, đạt được sự cân bằng giữa hiệu suất và hiệu quả bộ nhớ mà không yêu cầu tinh chỉnh thủ công.
Việc thực thi được sắp xếp hợp lý này—kết hợp phân tích mã thông báo dựa trên biểu đồ phổ, nén hiệu quả và cắt tỉa tự động—cho phép NAMM cung cấp cả bộ nhớ quan trọng tiết kiệm và hiệu suất đạt được lợi ích từ các nhiệm vụ đa dạng dựa trên Transformer. Bằng cách giảm các yêu cầu tính toán trong khi vẫn duy trì hoặc cải thiện độ chính xác, NAMM đặt ra tiêu chuẩn mới về quản lý bộ nhớ hiệu quả trong các mô hình AI hiện đại.
Điều gì sẽ xảy ra tiếp theo cho Transformers?
Sakana AI tin rằng NAMM chỉ là bước khởi đầu. Mặc dù công việc hiện tại tập trung vào việc tối ưu hóa các mô hình được đào tạo trước khi suy luận, nhưng nghiên cứu trong tương lai có thể tích hợp NAMM vào chính quy trình đào tạo. Điều này có thể cho phép các mô hình tìm hiểu các chiến lược quản lý bộ nhớ một cách tự nhiên, mở rộng hơn nữa độ dài của cửa sổ ngữ cảnh và nâng cao hiệu quả trên các miền.
“Công việc này mới chỉ bắt đầu khám phá không gian thiết kế của các mô hình bộ nhớ mà chúng tôi dự đoán có thể mang lại nhiều cơ hội mới để cải tiến các thế hệ máy biến áp trong tương lai”, nhóm kết luận.
Khả năng mở rộng hiệu suất, giảm chi phí và thích ứng giữa các phương thức đã được chứng minh của NAMM đặt ra tiêu chuẩn mới về hiệu quả của quy mô lớn Mô hình AI.