Inilunsad ng Google DeepMind ang FACTS Grounding, isang bagong benchmark na idinisenyo upang subukan ang mga malalaking modelo ng wika (LLMs) sa kanilang kakayahang bumuo ng tumpak sa katotohanan, mga tugon na nakabatay sa dokumento.
Ang benchmark, na naka-host sa Kaggle, ay naglalayong harapin ang isa sa mga pinakamabibigat na hamon sa artificial intelligence: pagtiyak na ang mga output ng AI ay nakabatay sa data na ibinigay sa kanila, sa halip na umasa sa panlabas na kaalaman o pagpapakilala ng mga guni-guni—maaaring totoo ngunit hindi tamang impormasyon.
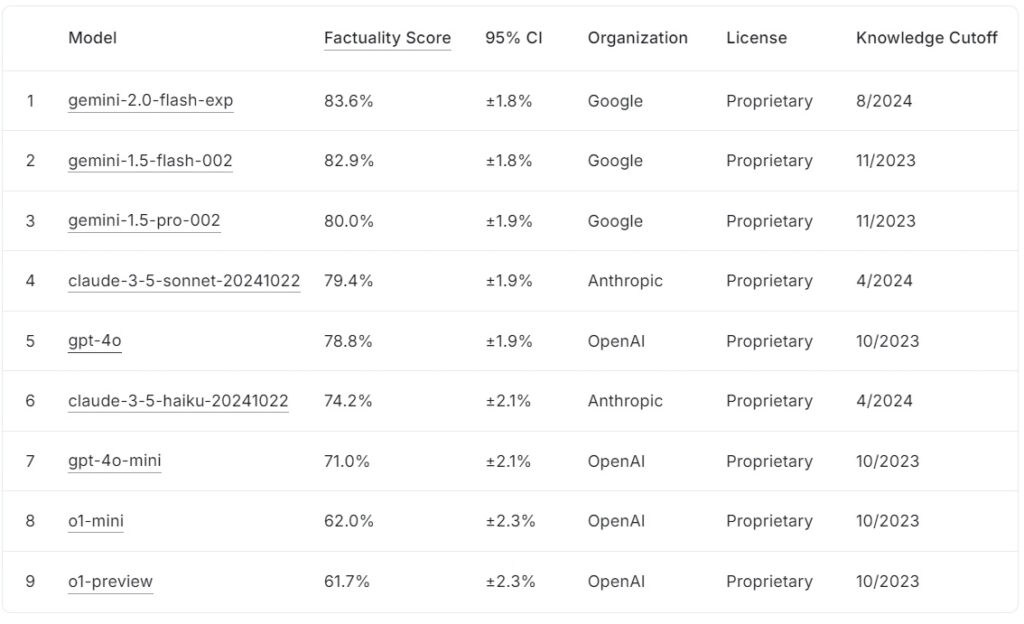
Ang kasalukuyang FACTS Grounding leaderboard ay nagra-rank ng malalaking modelo ng wika batay sa kanilang mga marka ng katotohanan, kasama ng Google gemini-2.0-flash-exp na humahantong sa 83.6% na sinundan malapit ng gemini-1.5-flash-002 sa 82.9%, at Gemini-1.5-pro-002 sa 80.0%.
Anthropic’s claude-3.5-sonnet-2024100 nasa ikaapat na ranggo na may 79.4%, habang Nakamit ng gpt-4o ng OpenAI ang 78.8%, na inilalagay ito sa ikalima. Sa ibaba sa listahan, ang claude-3.5-haiku-20241022 ng Anthropic ay nakakuha ng 74.2%, na sinusundan ng gpt-4o-mini sa 71.0%.
Maliliit na mga modelo ng OpenAI, o1-mini at o1-preview, bilugan ang leaderboard sa 62.0% at 61.7%, ayon sa pagkakabanggit.
 Pinagmulan: Kaggle
Pinagmulan: Kaggle
FACTS Grounding ay namumukod-tangi sa pamamagitan ng pag-aatas ng mga long-form na tugon na nag-synthesize ng detalyadong input mga dokumento, na ginagawa itong isa sa pinakamahigpit na benchmark para sa AI factuality hanggang sa kasalukuyan.
FACTS Grounding ay kumakatawan sa isang kritikal na pag-unlad para sa industriya ng AI, lalo na sa mga application kung saan ang tiwala at katumpakan ay mahalaga. Sa pamamagitan ng pagsusuri sa mga LLM sa mga domain gaya ng gamot, batas, pananalapi, retail, at teknolohiya, itinatakda ng benchmark ang yugto para sa pinahusay na pagiging maaasahan ng AI sa mga totoong sitwasyon.
Ayon sa research team ng DeepMind, ang “benchmark ay sumusukat sa kakayahan ng mga LLM na bumuo ng mga tugon na eksklusibong batay sa ibinigay na konteksto…kahit na ang konteksto ay sumasalungat sa kaalaman bago ang pagsasanay.”
Dataset Para sa Real-World Complexity
FACTS Grounding ay binubuo ng 1,719 na halimbawa, na na-curate ng mga tao na annotator upang tiyakin ang kaugnayan at pagkakaiba-iba ng mga halimbawang ito ay kinuha mula sa mga detalyadong dokumento na umaabot sa 32,000 token, katumbas ng humigit-kumulang 20,000 salita
Hinahamon ng bawat gawain ang mga LLM na magsagawa ng pagbubuod, pagbuo ng Q&A, o muling pagsulat ng nilalaman, na may mahigpit na mga tagubilin. upang sumangguni lamang sa ibinigay na data Ang benchmark ay umiiwas sa mga gawain na nangangailangan ng pagkamalikhain, matematika pangangatwiran, o ekspertong interpretasyon, na nakatuon sa halip sa pagsubok sa kakayahan ng isang modelo na mag-synthesize at magpahayag ng kumplikadong impormasyon.
Upang mapanatili ang transparency at maiwasan ang overfitting, hinati ng DeepMind ang dataset sa dalawang segment: 860 pampublikong mga halimbawa na available para sa panlabas na paggamit at 859 pribadong halimbawa na nakalaan para sa mga pagsusuri sa leaderboard.
Pinoprotektahan ng dalawahang istrukturang ito ang integridad ng benchmark habang hinihikayat ang pakikipagtulungan mula sa mga developer ng AI sa buong mundo.”Mahigpit naming sinusuri ang aming mga awtomatikong evaluator sa naka-hold-out na data ng pagsubok upang patunayan ang kanilang pagganap sa aming gawain,”sabi ng pangkat ng pananaliksik, na binibigyang-diin ang maingat na disenyo na sumasailalim sa FACTS Grounding.
Paghusga sa Katumpakan sa Peer Mga Modelo ng AI
Hindi tulad ng mga karaniwang benchmark, ang FACTS Grounding ay gumagamit ng proseso ng peer review na kinasasangkutan ng tatlong advanced na LLM: Gemini 1.5 Pro, GPT-4o, at Claude 3.5 Sonnet Ang mga modelong ito ay nagsisilbing mga hukom, na nagbibigay ng mga sagot batay sa dalawang kritikal na pamantayan: pagiging karapat-dapat at katumpakan ng katotohanan
Ang mga tugon ay dapat munang pumasa sa isang pagsusuri sa pagiging karapat-dapat upang kumpirmahin ang mga ito makahulugang tanong ng user ang mga kwalipikado ay tinatasa para sa kanilang batayan sa pinagmulang materyal, na may mga markang pinagsama-sama sa tatlong modelo upang mabawasan. bias.
Binibigyang-diin ng mga mananaliksik ng DeepMind ang kahalagahan ng multi-layered na pagsusuri na ito, na nagsasabi,”Ang mga sukatan na nakatuon sa pagsusuri sa katotohanan ng nabuong teksto…maaaring iwasan sa pamamagitan ng pagwawalang-bahala sa layunin sa likod ng kahilingan ng user. Sa pamamagitan ng pagbibigay ng mas maiikling tugon na umiiwas sa paghahatid ng komprehensibong impormasyon…posibleng makamit ang mataas na marka ng katotohanan habang hindi nagbibigay ng kapaki-pakinabang na tugon.”
Ang paggamit ng maraming template ng pagmamarka, kabilang ang span-level at JSON-based approach , higit pang tinitiyak ang pagkakahanay sa paghatol ng tao at kakayahang umangkop sa magkakaibang mga gawain.
Pagharap sa Hamon ng AI Hallucinations
AI hallucinations ay kabilang sa mga pinakamahahalagang hadlang sa malawakang pag-aampon ng mga LLM sa mga kritikal na larangan, kung saan ang mga modelo ay bumubuo ng mga output na mukhang makatotohanan ngunit hindi tama, ay nagdudulot ng mga seryosong panganib sa mga domain gaya ng pangangalaga sa kalusugan, legal na pagsusuri, at pag-uulat sa pananalapi
FACTS Grounding direktang tinutugunan ang isyung ito sa pamamagitan ng pagpapatupad ng mahigpit na pagsunod sa ibinigay na data ng pag-input Hindi lamang sinusuri ng diskarteng ito ang kakayahan ng isang modelo na umiwas nagpapakilala ng mga kasinungalingan ngunit tinitiyak din na ang mga output ay mananatiling nakaayon sa layunin ng user.
Kabaligtaran sa mga benchmark tulad ng OpenAI’s SimpleQA, na sumusukat sa katotohanan sa pagkuha ng data ng pagsasanay, ang FACTS Grounding ay sumusubok kung gaano kahusay ang pag-synthesize ng mga modelo ng bagong impormasyon.
Ang pananaliksik na papel ay binibigyang-diin ang pagkakaibang ito:”Ang pagtiyak sa katotohanang katumpakan habang bumubuo ng mga tugon sa LLM ay mahirap. Ang mga pangunahing hamon sa katotohanan ng LLM ay ang pagmomodelo (ibig sabihin, arkitektura, pagsasanay, at hinuha) at pagsukat (ibig sabihin, pamamaraan ng pagsusuri, data at sukatan).”
Mga Teknikal na Hamon at Disenyong Benchmark
Ang pagiging kumplikado ng mga long-form na input ay nagpapakilala ng mga natatanging teknikal na hamon, lalo na sa pagdidisenyo ng mga automated na pamamaraan ng pagsusuri na maaaring tumpak na masuri ang mga naturang tugon
FACTS Grounding ay umaasa sa computationally intensive na proseso upang patunayan ang mga tugon, na gumagamit ng mahigpit na pamantayan upang matiyak ang pagiging maaasahan Ang pagsasama ng maraming modelo ng judge ay nagpapagaan ng mga potensyal na bias at nagpapalakas sa pangkalahatang balangkas ng pagsusuri.
Ang pangkat ng pananaliksik ay nagha-highlight sa kahalagahan. ng pagdiskwalipika ng malabo o walang kaugnayang mga sagot, na binabanggit, “Ang pagdiskwalipika sa mga hindi karapat-dapat na tugon ay humahantong sa isang pagbawas…dahil ang mga tugon na ito ay itinuturing bilang hindi tumpak.”
Ang mahigpit na pagpapatupad ng kaugnayan na ito ay tumitiyak na ang mga modelo ay hindi ginagantimpalaan para sa pag-iwas sa diwa ng gawain.
Paghihikayat sa Pakikipagtulungan sa Pamamagitan ng Transparency
Ang desisyon ng DeepMind na mag-host ng FACTS Grounding on Kaggle ay sumasalamin sa pangako nito sa pagpapaunlad ng pakikipagtulungan sa buong industriya ng AI. Sa pamamagitan ng paggawa ng pampublikong segment ng dataset, iniimbitahan ng proyekto ang mga mananaliksik at developer ng AI na suriin ang kanilang mga modelo kumpara sa isang matatag na pamantayan at mag-ambag sa pagsulong ng mga benchmark ng katotohanan.
Nakaayon ang diskarteng ito sa mas malawak na layunin ng transparency at ibinahaging pag-unlad sa AI, na tinitiyak na ang mga pagpapahusay sa katumpakan at saligan ay hindi nakakulong sa iisang organisasyon.
Pagkakaiba mula sa Iba Mga Benchmark
FACTS Nakikilala ng grounding ang sarili nito mula sa iba pang mga benchmark sa pamamagitan ng pagtutok nito sa grounding sa mga bagong ipinakilalang input sa halip na pre-trained kaalaman.
Habang tinatasa ng mga benchmark tulad ng SimpleQA ng OpenAI kung gaano kahusay kumukuha at gumagamit ng impormasyon ang isang modelo mula sa training corpus nito, sinusuri ng FACTS Grounding ang mga modelo sa kanilang kakayahang mag-synthesize at magpahayag ng mga tugon batay lamang sa ibinigay na data.
Mahalaga ang pagkakaibang ito sa pagtugon sa mga hamon na dulot ng mga paniniwala ng modelo o likas na pagkiling. Sa pamamagitan ng paghihiwalay sa gawain ng pagpoproseso ng mga panlabas na input, tinitiyak ng FACTS Grounding na ang mga sukatan ng pagganap ay sumasalamin sa kakayahan ng isang modelo na gumana sa mga dynamic, real-world na mga senaryo sa halip na ibalik lamang ang pre-natutunan na impormasyon.
Tulad ng ipinaliwanag ng DeepMind sa research paper nito, ang benchmark ay idinisenyo upang suriin ang mga LLM sa kanilang kakayahan na pamahalaan ang mga kumplikado, mahabang anyo na mga query na may makatotohanang batayan, na ginagaya ang mga gawaing nauugnay sa mga real-world na application.
Mga Alternatibong Paraan para sa Grounding LLMs
Nag-aalok ang ilang mga paraan ng katulad na mga tampok sa saligan sa FACTS Grounding, bawat isa ay may mga lakas at mga kahinaan. Nilalayon ng mga pamamaraang ito na pahusayin ang mga output ng LLM sa pamamagitan ng alinman sa pagpapabuti ng kanilang access sa tumpak na impormasyon o pagpino sa kanilang mga proseso ng pagsasanay at pag-align.
Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) ang katumpakan ng mga LLM output sa pamamagitan ng dynamic na pagkuha ng nauugnay na impormasyon mula sa mga panlabas na base ng kaalaman o database at pagsasama nito sa mga tugon ng modelo. Sa halip na sanayin muli ang buong LLM, gumagana ang RAG sa pamamagitan ng pagharang sa mga prompt ng user at pagpapayaman sa kanila ng napapanahong impormasyon.
Ang mga advanced na pagpapatupad ng RAG ay kadalasang gumagamit ng entity-based retrieval, kung saan ang data na nauugnay sa mga partikular na entity ay pinagsama sa magbigay ng lubos na nauugnay na konteksto para sa mga tugon ng LLM.
Karaniwang gumagamit ang RAG ng mga diskarte sa paghahanap ng semantiko para sa pagkuha ng impormasyon. Ang mga dokumento o ang kanilang mga fragment ay ini-index batay sa kanilang mga semantic na pag-embed, na nagbibigay-daan sa system na itugma ang query ng user sa mga entry na may pinakamaraming nauugnay na konteksto. Tinitiyak ng diskarteng ito na ang mga LLM ay nakakabuo ng mga tugon na may alam sa pinakabago at pinakanauugnay na data.
Ang pagiging epektibo ng RAG ay lubos na nakadepende sa kalidad at organisasyon ng knowledge base, pati na rin sa katumpakan ng mga retrieval algorithm. Habang sinusuri ng FACTS Grounding ang kakayahan ng isang LLM na manatiling nakaangkla sa isang ibinigay na dokumento ng konteksto, pinupunan ito ng RAG sa pamamagitan ng pagbibigay-daan sa mga LLM na palawakin ang kanilang kaalaman nang pabago-bago, na kumukuha mula sa mga panlabas na mapagkukunan upang mapahusay ang pagiging totoo at kaugnayan.
Pag-distill ng Kaalaman
Kaalaman distillation ang paglilipat ng mga kakayahan ng isang malaki, kumplikadong modelo (tinukoy bilang guro) sa isang mas maliit, modelong partikular sa gawain (ang mag-aaral). Pinapabuti ng pamamaraang ito ang kahusayan habang pinapanatili ang karamihan sa katumpakan ng orihinal na modelo. Dalawang pangunahing diskarte ang ginagamit sa distillation ng kaalaman:
Distilasyon ng Kaalaman na Nakabatay sa Tugon: Nakatuon sa pagkopya ng mga output ng modelo ng guro, na tinitiyak na ang modelo ng mag-aaral ay gumagawa ng mga katulad na resulta para sa mga ibinigay na input.
Feature-Based Knowledge Distillation: Kinukuha ang mga panloob na representasyon at feature mula sa modelo ng guro, na nagbibigay-daan sa modelo ng mag-aaral na magtiklop nang mas malalim mga insight.
Sa pamamagitan ng pagpino sa mas maliliit na modelo, binibigyang-daan ng distillation ng kaalaman ang pag-deploy ng mga LLM sa mga kapaligirang pinaghihigpitan ng mapagkukunan nang walang makabuluhang pagkalugi sa pagganap. Hindi tulad ng FACTS Grounding, na sinusuri ang grounding fidelity, ang distillation ng kaalaman ay mas nababahala sa pag-scale ng mga kakayahan ng LLM at pag-optimize ng mga ito para sa mga partikular na gawain.
Fine-Tuning with Grounded Datasets
Fine-tuning ay kinabibilangan ng pag-adapt ng mga paunang sinanay na LLM sa mga partikular na domain o gawain sa pamamagitan ng pagsasanay sa mga ito sa mga na-curate na dataset kung saan kritikal ang batayan ng katotohanan. Halimbawa, ang mga dataset na binubuo ng siyentipikong literatura o mga makasaysayang talaan ay maaaring gamitin upang pahusayin ang kakayahan ng modelo na makagawa ng tumpak at mga output na partikular sa domain. Pinapahusay ng diskarteng ito ang pagganap ng LLM para sa mga espesyal na aplikasyon, gaya ng pagsusuri sa medikal o legal na dokumento.
Gayunpaman, ang pag-fine-tuning ay masinsinang mapagkukunan at nanganganib sa sakuna na pagkalimot, kung saan nawawalan ng kaalaman ang modelo na nakuha sa paunang pagsasanay nito. Ang FACTS Grounding ay nakatuon sa pagsubok ng katotohanan sa mga nakahiwalay na konteksto, samantalang ang fine-tuning ay naglalayong pahusayin ang baseline performance ng mga LLM sa mga partikular na lugar.
Reinforcement Learning with Human Feedback (RLHF)
Reinforcement Learning na may Human Feedback (RLHF) isinasama ang mga kagustuhan ng tao sa proseso ng pagsasanay ng mga LLM. Sa pamamagitan ng paulit-ulit na pagsasanay sa modelo upang iayon ang mga tugon nito sa feedback ng tao, pinipino ng RLHF ang kalidad, katotohanan, at pagiging kapaki-pakinabang ng mga output. Pinuri ng mga human evaluator ang mga output ng LLM, at ang mga markang ito ay ginagamit bilang mga senyales upang i-optimize ang modelo.
Ang RLHF ay partikular na naging matagumpay sa pagpapahusay ng kasiyahan ng user at pagtiyak na ang mga nabuong tugon ay naaayon sa mga inaasahan ng tao. Habang sinusuri ng FACTS Grounding ang makatotohanang saligan laban sa mga partikular na dokumento, binibigyang-diin ng RLHF ang pag-align ng mga output ng LLM sa mga halaga at kagustuhan ng tao.
Pag-aaral na Sumusunod sa Instruksyon at In-Context
Pagsunod sa pagtuturo at in-context na pag-aaral kasangkot ang pagpapakita ng saligan sa mga LLM sa pamamagitan ng maingat na ginawang mga halimbawa sa loob ng prompt ng user. Ang mga pamamaraang ito ay umaasa sa kakayahan ng modelo na mag-generalize mula sa ilang-shot na demonstrasyon. Bagama’t ang diskarteng ito ay maaaring magbunga ng mabilis na mga pagpapabuti, maaaring hindi nito maabot ang parehong antas ng kalidad ng saligan gaya ng mga pamamaraang nakabatay sa fine-tuning o retrieval.
Mga Panlabas na Tool at API
Maaaring isama ang mga LLM sa mga external na tool at API upang magbigay ng real-time na access sa external na data, na makabuluhang nagpapahusay sa kanilang mga kakayahan sa pag-ground. Kabilang sa mga halimbawa ang:
Kakayahang Mag-browse: Nagbibigay-daan sa mga LLM na i-access at kunin ang real-time na impormasyon mula sa web upang sagutin ang mga partikular na tanong o i-update ang kanilang kaalaman.
API Calls: Nagbibigay-daan sa mga LLM na makipag-ugnayan sa mga structured na database o serbisyo, na nagpapayaman sa mga tugon na may tumpak at napapanahon na impormasyon.
Ang mga tool na ito ay nagpapalawak ng utility ng mga LLM sa pamamagitan ng pagkonekta sa mga mapagkukunan ng kaalaman sa totoong mundo, pinapahusay ang kanilang kakayahang bumuo ng tumpak at batayan na mga output. Habang sinusuri ng FACTS Grounding ang internal grounding fidelity, ang mga external na tool ay nagbibigay ng alternatibong paraan ng pagpapalawak at pag-verify ng katotohanan.
Open-Source Model Grounding Options
Maraming open-source na pagpapatupad ang available para sa mga alternatibong pamamaraan ng grounding na tinalakay sa itaas:
Mga Implikasyon para sa High-Stakes Applications
Ang kahalagahan ng tumpak at grounded AI na mga tugon ay nagiging partikular na maliwanag sa mga high-stakes na application, gaya ng mga medikal na diagnostic, legal na pagsusuri, at pagsusuri sa pananalapi. Sa mga kontekstong ito, kahit na ang mga maliliit na kamalian ay maaaring humantong sa mga makabuluhang kahihinatnan, na ginagawa ang pagiging maaasahan ng mga output na binuo ng AI bilang isang hindi mapag-usapan na kinakailangan.
FACTS Ang pagbibigay-diin ng grounding sa katotohanan at pagsunod sa pinagmumulan ng materyal ay nagsisiguro na ang mga modelo ay nasubok sa ilalim ng mga kondisyong malapit na sumasalamin sa mga hinihingi sa totoong mundo.
Halimbawa, sa mga medikal na konteksto, isang LLM na inatasan ang pagbubuod ng mga rekord ng pasyente ay dapat na maiwasan ang pagpasok ng mga pagkakamali na maaaring maling impormasyon sa mga desisyon sa paggamot. Katulad nito, sa mga legal na setting, ang pagbuo ng mga buod o pagsusuri ng batas ng kaso ay nangangailangan ng tumpak na batayan sa mga ibinigay na dokumento.
FACTS Grounding ay hindi lamang sinusuri ang mga modelo sa kanilang kakayahan na matugunan ang mahigpit na mga kinakailangan na ito ngunit nagtatatag din ng isang benchmark para sa mga developer na layunin para sa paglikha ng mga system na angkop para sa mga naturang application.
Pagpapalawak ang FACTS Dataset at Mga Direksyon sa Hinaharap
Inilagay ng DeepMind ang FACTS Grounding bilang isang”living benchmark”, isa na uunlad kasabay ng mga pagsulong sa Ang mga pag-update sa hinaharap ay malamang na palawakin ang dataset upang maisama ang mga bagong domain at uri ng gawain, na tinitiyak ang patuloy na kaugnayan nito habang lumalaki ang mga kakayahan ng LLM
Dagdag pa rito, ang pagpapakilala ng mas magkakaibang mga template ng pagsusuri ay maaaring higit na mapahusay ang tibay ng mga ito. proseso ng pagmamarka, pagtugon sa mga edge na kaso at pagbabawas ng mga natitirang bias.
Tulad ng kinikilala ng pangkat ng pananaliksik ng DeepMind, walang benchmark ang ganap na i-encapsulate ang mga kumplikado ng mga real-world na application, gayunpaman, sa pamamagitan ng pag-ulit sa FACTS Grounding at pakikipag-ugnayan sa mas malawak na komunidad ng AI, nilalayon ng proyekto na itaas ang bar para sa katotohanan at saligan sa mga AI system.
Tulad ng sinabi ng koponan ng DeepMind,”Ang katotohanan at batayan ay kabilang sa mga pangunahing salik na humuhubog sa hinaharap na tagumpay at pagiging kapaki-pakinabang ng mga LLM at mas malawak na AI system, at nilalayon naming palaguin at ulitin ang FACTS Grounding habang umuunlad ang larangan, patuloy na nagtataas ng bar.”