Ang AI team ng Meta ay nasa ilalim ng matinding pressure kasunod ng paglabas ng DeepSeek’s R1 model, na hinamon ang industriya ng AI sa hindi pa nagagawang kahusayan at performance nito.
Ang mga anonymous na post sa propesyonal na platform ng networking na Blind ay nagpapakita ng kaguluhan sa hanay ng Meta, kung saan ang mga inhinyero ay naglalarawan ng isang galit na galit na pagsisikap na maunawaan at gayahin ang tagumpay ng DeepSeek habang nakikipagbuno sa mga panloob na inefficiencies at mga maling hakbang sa pamumuno.
Blind ay isang anonymous na propesyonal na platform ng networking kung saan ang mga empleyado ay maaaring magbahagi ng impormasyon, talakayin ang mga isyu sa lugar ng trabaho, at makipag-ugnayan sa mga kapantay sa pareho o magkakaibang industriya. Mayroon itong sistema ng pag-verify para matiyak na ang mga user ay aktwal na empleyado ng mga kumpanyang inaangkin nilang pinagtatrabahuhan, at pangunahing sikat sa mga propesyonal sa industriya ng tech.
Nauugnay: Paano Nalalampasan ng DeepSeek R1 ang ChatGPT o1 Sa ilalim ng Mga Sanction, Muling Pagtukoy sa AI Efficiency Gamit ang 2,048 GPU Lamang
Isang hindi kilalang empleyado ng Meta, pag-post sa ilalim ng pangalan”ngi,”ang buod ng mood sa loob ng GenAI division ng Meta:
“Nagsimula ito sa DeepSeek V3 [isang DeepSeek model na inilabas noong Disyembre 2024], na naging dahilan upang ang Llama 4 ay nasa likod na sa mga benchmark. Nagdaragdag ng insulto sa pinsala. ay ang’hindi kilalang kumpanyang Tsino na may 5..5 milyon na badyet sa pagsasanay.’Ang mga inhinyero ay gumagalaw nang galit na galit upang hatiin ang DeepSeek at kopyahin ang anumang bagay at lahat ng magagawa namin mula dito.
Hindi ako nagpapalaki. Ang pamamahala ay nag-aalala tungkol sa pagbibigay-katwiran sa napakalaking halaga ng GenAI org. Paano nila haharapin ang pamumuno kung ang bawat solong’lider’ng GenAI org ay gumagawa ng higit pa sa halaga para sanayin ang DeepSeek V3 nang buo, at mayroon kaming dose-dosenang mga ganoong’lider.’Ang DeepSeek R1 ay gumawa ng mga bagay na mas nakakatakot. Hindi ko maihayag ang kumpidensyal na impormasyon ngunit malapit na rin itong maging pampubliko.
Ito dapat ay isang maliit na organisasyong nakatuon sa engineering ngunit dahil maraming tao ang gustong sumali sa impact grab at artipisyal na pagpapalaki ng pag-hire sa org, lahat ay natatalo.”
Ang mga komento ng empleyado ay nagbibigay-diin sa panloob na kawalang-kasiyahan sa diskarte ng Meta sa pagbuo ng AI, na inilalarawan ng marami bilang sobrang burukrasya, masinsinang mapagkukunan, at hinimok ng mababaw na sukatan sa halip na makabuluhang pagbabago
Ang paglabas ng DeepSeek R1 ay naglantad sa mga pagkukulang na ito at pinilit ang pagtutuos para sa isa sa mga pinakamalaking manlalaro ng industriya ng AI.
Kaugnay: LLaMA AI Under Fire – Ano ang Hindi Sinasabi sa Iyo ng Meta Tungkol sa Mga Modelong “Open Source”
DeepSeek R1 Sends Shockwaves Though US Tech Sector
Ang modelong R1 ng DeepSeek, na inilabas noong Enero 10, 2025, ay nagpabago sa pandaigdigang AI landscape sa pamamagitan ng pagpapakita na ang mga modelong may mataas na pagganap ay maaaring mabuo sa maliit na bahagi ng karaniwang gastos nauugnay sa mga naturang proyekto.
Paggamit ng mga Nvidia H800 GPU—mga lower-grade chip na pinaghihigpitan ng mga kontrol sa pag-export ng U.S.—Sinanay ng mga DeepSeek engineer ang modelo sa halagang wala pang $6 milyon, ayon sa isang research paper na inilabas noong Disyembre 2024.
Ang mga ito Ang mga GPU, na sadyang pinigilan upang sumunod sa mga parusa ng U.S., ay nagpakita ng mga natatanging hamon, ngunit ang mga diskarte sa pag-optimize ng DeepSeek ay nagbigay-daan sa koponan na makamit ang maihahambing na pagganap sa mga modelong nangunguna sa industriya.
Kabilang sa mga benchmark ng R1 ang 97.3% na marka sa MATH-500 at 79.8% na marka sa AIME 2024, na naglalagay nito sa mga pinaka may kakayahang AI system sa mundo.
Ang kahusayan ng DeepSeek Ang R1, na bahagyang lumalampas sa modelo ng OpenAI’s o1, ay hindi lamang nayanig ang kumpiyansa sa U.S. tech giants tulad ng Meta ngunit nag-trigger din makabuluhang reaksyon sa merkado.
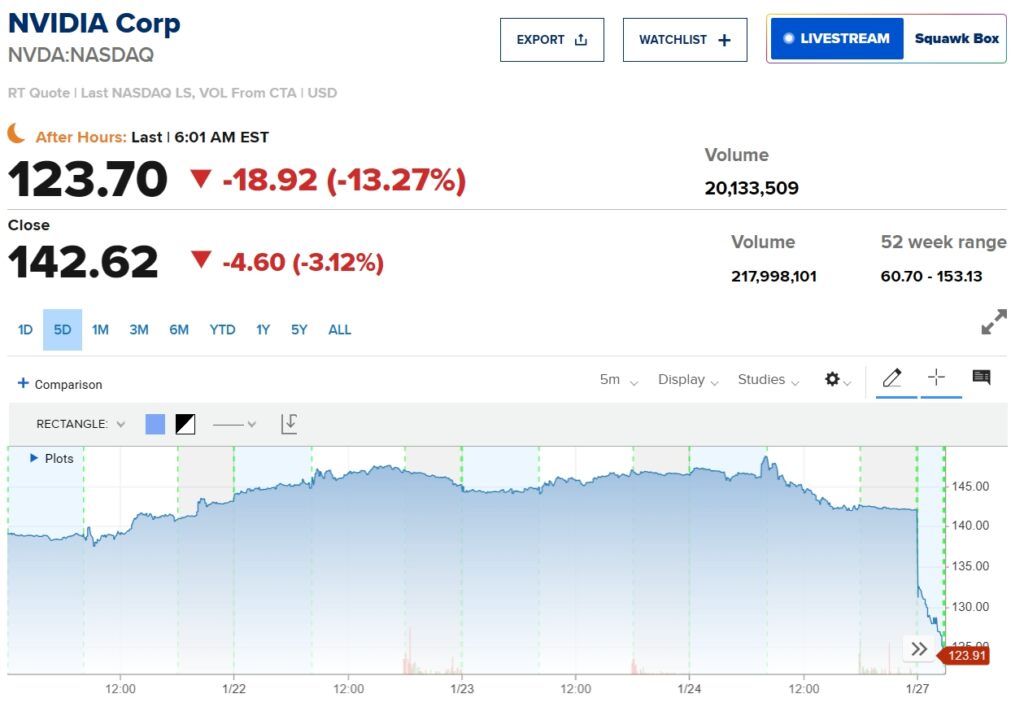
Bumaba ng mahigit 13% ang stock ng Nvidia sa premarket trading kasunod ng paglabas ng modelo, at ang Nasdaq 100 futures ay bumagsak ng higit sa 5%. Samantala, ang DeepSeek ay umakyat sa nangungunang puwesto sa U.S. App Store ng Apple, na nalampasan ang ChatGPT ng OpenAI sa mga pag-download.
Pag-uusad ng Meta Engineers sa Mamahaling Computational AI Training
Sa loob ng Meta, pinuna ng mga inhinyero ang pag-asa ng kumpanya sa malupit na computational kapangyarihan sa halip na ituloy ang inobasyon na hinimok ng kahusayan.
Isang empleyado ang nagsabi sa Blind: Marami sa pamunuan ang literal na walang ideya (kahit na maraming engineering) tungkol sa pinagbabatayan na teknolohiya at patuloy silang nagbebenta ng’mas maraming GPU=panalo’sa pamunuan.”pagkadismaya sa kultura ng”paghabol sa epekto,”na naglalarawan dito bilang isang karera para sa mga promosyon sa halip na isang pangako sa makabuluhang pagsulong.
Nakaharap din ang mga pagsisikap ng AI ng Meta sa pagsisiyasat para sa kanilang kakulangan ng liksi kumpara sa mga katunggali. Ang modelo ng R1 ng DeepSeek ay hindi lamang cost-effective ngunit open-source din, na nagpapahintulot sa mga developer sa buong mundo na suriin at buuin ang arkitektura nito.
Ang mga talakayan ng Blind ay nagpapakita rin ng mas malawak na mga alalahanin sa industriya. Kinikilala ng mga empleyado ng Google ang nakakagambalang epekto ng DeepSeek, na may isang pagpuna:”Nakakabaliw talaga ang ginagawa ng DeepSeek. Hindi lang Meta, nagsisindi sila ng apoy sa ilalim ng OpenAI, Google at pati na rin sa puwit ni Anthropic. Alin ang isang magandang bagay, nakikita natin nang real-time kung gaano kabisa ang isang bukas na kumpetisyon para sa pagbabago.”
Ang sentiment na ito ay sumasalamin sa lumalaking pagkilala na ang mga tradisyonal na diskarte na mabibigat sa mapagkukunan ay maaaring hindi na magagarantiya ng pangingibabaw sa pagbuo ng AI.
Ang transparency na ito ay umani ng papuri mula sa mga pinuno ng industriya, kabilang ang sariling Chief AI Scientist ng Meta, si Yann LeCun, na sumulat sa LinkedIn: “Nakinabang ang DeepSeek mula sa open research at open source (hal., PyTorch at Llama mula sa Meta ay gumawa sila ng mga bagong ideya at binuo ang mga ito sa ibabaw ng trabaho ng ibang tao.”
Mark Zuckerberg Doubles Down sa AI Infrastructure Investments
Sa kabaligtaran, ang Meta ay nakatuon sa malakihang pamumuhunan sa imprastraktura. Kamakailan ay inanunsyo ng CEO na si Mark Zuckerberg ang mga planong mag-deploy ng mahigit 1.3 milyong GPU sa 2025 at mamuhunan ng $60-65 bilyon sa pagpapaunlad ng AI.
“Ito ay isang napakalaking pagsisikap, at sa mga darating na taon, ito ay magtutulak sa aming mga pangunahing produkto at negosyo, magbubukas ng makasaysayang pagbabago, at magpapalawak ng pamumuno sa teknolohiya ng Amerika,”sabi ni Zuckerberg sa isang pampublikong pahayag sa unang bahagi ng taong ito. Gayunpaman, ang mga planong ito ngayon ay lalong lumalabas na salungat sa payat, kahusayan-unang diskarte na ipinakita ng DeepSeek.
Ang pag-angat ng DeepSeek ay muling nagpasimula ng mga debate sa mga paghihigpit sa pag-export ng U.S. Mga teknolohiyang nauugnay sa AI sa China Mula noong 2021, ang administrasyong Biden ay nagpatupad ng mga hakbang upang limitahan ang pag-access ng China sa mga advanced na chip, kabilang ang mga H100 GPU ng Nvidia
Gayunpaman, ang kakayahan ng DeepSeek na makamit ang mga resulta ng world-class na may pinaghihigpitang hardware. ang mga limitasyon ng mga patakarang ito Sa pamamagitan ng pag-iimbak ng mga H800 GPU bago nagkaroon ng ganap na epekto ang mga parusa at tumuon sa kahusayan, binago ng DeepSeek ang mga hadlang.
Inilarawan ni Founder Liang Wenfeng, isang dating hedge fund manager, ang diskarte ng kumpanya: “Tinatantya namin na ang pinakamahusay na domestic at foreign model ay maaaring magkaroon ng isang puwang sa istruktura ng modelo at dynamics ng pagsasanay. Para sa kadahilanang ito, kailangan nating gumamit ng apat na beses na mas maraming kapangyarihan sa pag-compute upang makamit ang parehong epekto. Ang kailangan nating gawin ay patuloy na paliitin ang mga puwang na ito.”
Habang nakikipagbuno ang industriya ng AI sa mga implikasyon ng tagumpay ng DeepSeek, nahaharap ang Meta sa isang kagyat na pangangailangang umangkop. Nilinaw ng mga empleyado ng kumpanya ang kanilang mga pagkabigo, na nanawagan para sa isang pagbabago tungo sa mas mahusay, innovation-driven na mga diskarte Sa ngayon, ang DeepSeek’s R1 model ay naninindigan bilang isang malakas na pagpapakita ng resourceful engineering, na muling hinuhubog ang competitive. dynamics ng global AI development.