Ipinakilala ng Microsoft ang rStar-Math, isang pagpapatuloy at pagpipino ng dati nitong rStar framework, upang itulak ang mga hangganan ng mga small language models (SLMs) sa mathematical reasoning.
Idinisenyo upang makipagkumpitensya sa mas malalaking sistema tulad ng o1-preview ng OpenAI, ang rStar-Math ay nakakamit ng mga kahanga-hangang benchmark sa paglutas ng problema habang ipinapakita kung paano gumaganap ang mga compact na modelo sa mga antas ng kompetisyon. Ang pag-unlad na ito ay nagpapakita ng pagbabago sa mga priyoridad ng AI, na lumilipat mula sa pag-scale pataas hanggang sa pag-optimize ng pagganap para sa mga partikular na gawain.
Pagsulong mula sa rStar patungo sa rStar-Math
Ang rStar balangkas mula noong nakaraang tag-araw ay naglatag ng batayan para sa pagpapahusay ng pangangatwiran ng SLM sa pamamagitan ng Monte Carlo Tree Search (MCTS), isang algorithm na pinipino ang mga solusyon sa pamamagitan ng pagtulad at pag-validate ng maraming path.
RStar ay nagpakita na ang mas maliliit na modelo ay maaaring humawak ng mga kumplikadong gawain, ngunit ang aplikasyon nito ay nanatiling pangkalahatan. Itinayo ng rStar-Math ang pundasyong ito na may mga naka-target na inobasyon na iniakma para sa pangangatwiran sa matematika.
Ang sentro ng tagumpay ng rStar-Math ay ang code-augmented chain-of-thought (CoT) na pamamaraan nito, kung saan ang modelo ay gumagawa ng mga solusyon sa parehong natural na wika at executable Python code.
Ang dual-output na istrukturang ito ay tumitiyak na ang mga intermediate na hakbang sa pangangatwiran ay mabe-verify, binabawasan ang mga error at pinapanatili ang lohikal na pagkakapare-pareho. Binigyang-diin ng mga mananaliksik ang kahalagahan ng diskarteng ito, na nagsasabi,”Ang pagkakapare-pareho ng isa’t isa ay sumasalamin sa karaniwang gawain ng tao sa kawalan ng pangangasiwa, kung saan ang pagkakasundo ng mga kasamahan sa mga nakuhang sagot ay nagmumungkahi ng mas mataas na posibilidad na maging tama.”
Kaugnay: Tina-target ng Chinese DeepSeek R1-Lite-Preview Model ang Lead ng OpenAI sa Automated Reasoning
Bukod pa sa CoT, rStar-Math nagpapakilala ng Process Preference Model (PPM), na nagsusuri at nagra-rank ng mga intermediate na hakbang batay sa kalidad Hindi tulad ng mga tradisyunal na sistema ng reward na kadalasang umaasa sa maingay na data, inuuna ng PPM ang lohikal na pagkakaugnay-ugnay at katumpakan, na higit na nagpapahusay sa pagiging maaasahan ng modelo. p>
“Ang PPM ay gumagamit ng katotohanan na, bagama’t ang mga Q-value ay hindi pa rin sapat na tumpak para mamarkahan ang bawat hakbang sa pangangatwiran sa kabila ng paggamit ng malawak na MCTS rollouts, maaasahang matukoy ng mga Q-value ang mga positibong (tama) na hakbang mula sa mga negatibong (hindi nauugnay/mali). pagkawala upang ma-optimize ang hula ng marka ng PPM para sa bawat hakbang sa pangangatwiran, na nakakamit ng maaasahang pag-label. Iniiwasan ng diskarteng ito ang mga nakasanayang pamamaraan na direktang gumagamit ng mga Q-value bilang mga label ng gantimpala, na likas na maingay at hindi tumpak sa sunud-sunod na pagtatalaga ng gantimpala.”
Sa wakas, isang four-round na self-evolution recipe na unti-unting bumubuo ng isang hangganan. modelo ng patakaran at PPM mula sa simula.
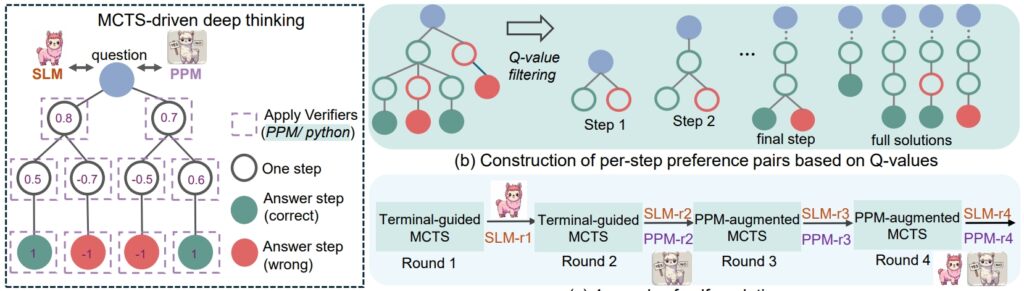 rSTar-Math na pamamaraan ng pangangatwiran (Source: research paper)
rSTar-Math na pamamaraan ng pangangatwiran (Source: research paper)
Pagganap na Hinahamon ang Mas Malalaking Modelo
Nagtatakda ang rStar-Math ng mga bagong pamantayan sa matematika mga benchmark sa pangangatwiran, pagkamit ng mga resulta na katunggali, at sa ilang mga kaso ay lumalampas, sa mga mas malalaking AI system
Sa GSM8K. dataset, isang pagsubok para sa pangangatwiran sa matematika, ang katumpakan ng isang 7-bilyong parameter na modelo ay bumuti mula 12.51% hanggang 63.91% pagkatapos pagsasama ng rStar-Math Sa American Invitational Mathematics Examination (AIME), nalutas ng modelo ang 53.3% ng mga problema, inilalagay ito sa gitna ang nangungunang 20% ng mga kalahok sa high school.
Ang mga resulta ng dataset ng MATH ay pare-parehong kahanga-hanga, na may rStar-Math na nakakamit ng 90% na rate ng katumpakan, na higit sa pagganap sa o1-preview ng OpenAI.
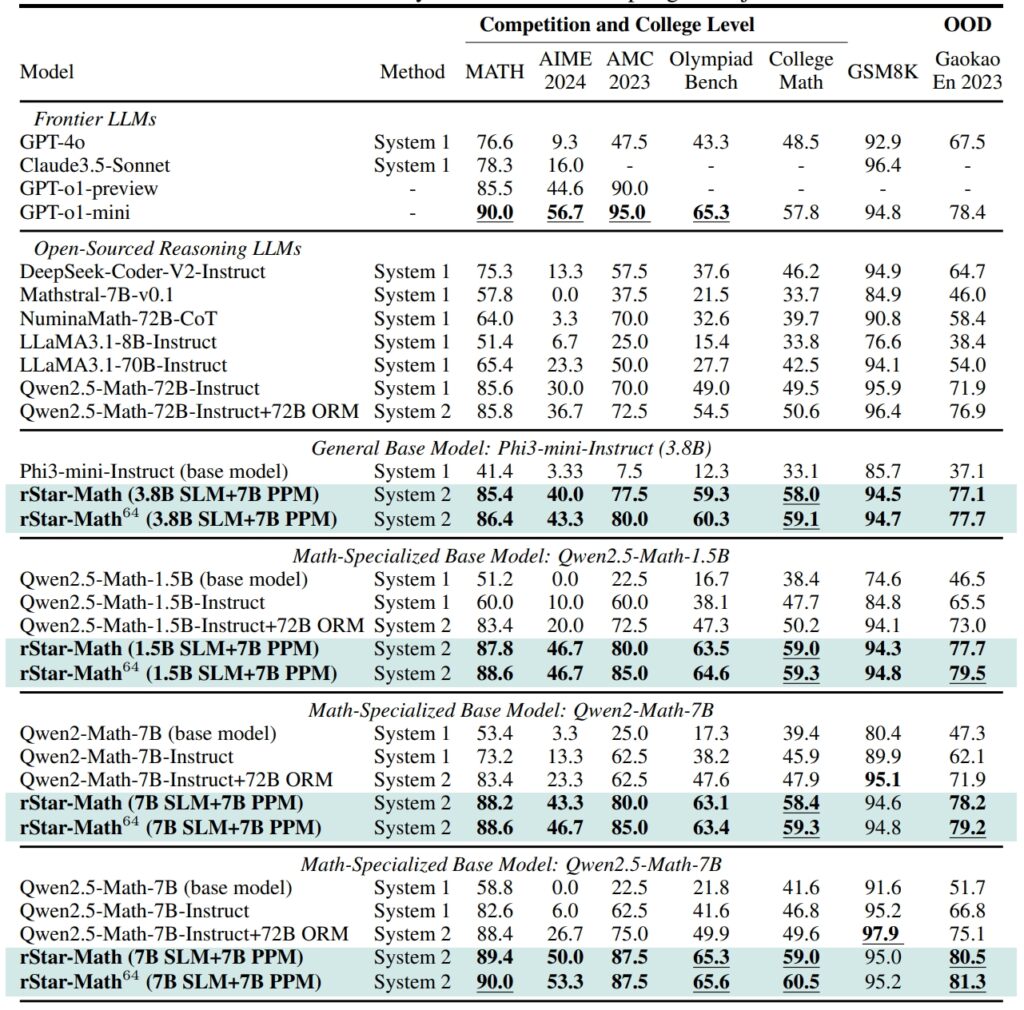 Pagganap ng rStar-Math at iba pang mga frontier na LLM sa pinakamapanghamong math benchmarks (Source: research papel)
Pagganap ng rStar-Math at iba pang mga frontier na LLM sa pinakamapanghamong math benchmarks (Source: research papel)
Ang mga nakamit na ito ay nagha-highlight sa kakayahan ng framework na paganahin ang mga SLM na pangasiwaan ang mga gawain na dati nang pinangungunahan ng mga malalaking modelo ng mapagkukunan-intensive. Sa pamamagitan ng pagbibigay-diin sa lohikal na pagkakapare-pareho at nabe-verify na mga intermediate na hakbang, tinutugunan ng rStar-Math ang isa sa mga pinaka-paulit-ulit na hamon ng AI: pagtiyak ng maaasahang pangangatwiran sa mga kumplikadong espasyo ng problema.
Mga Teknikal na Inobasyon sa Pagmamaneho ng rStar-Math
Ang ebolusyon mula sa rStar hanggang sa rStar-Math ay nagpapakilala ng ilang mahahalagang pagsulong. Ang pagsasama-sama ng MCTS ay nananatiling sentro sa balangkas, na nagbibigay-daan sa modelo na galugarin ang magkakaibang mga landas sa pangangatwiran at bigyang-priyoridad ang mga pinakapangako.
Ang pagdaragdag ng pangangatwiran ng CoT, kasama ang pagtutok nito sa pag-verify ng code, ay tumitiyak na ang mga output ay parehong nabibigyang-kahulugan at tumpak.
Kaugnay: QwQ-32B ng Alibaba-Preview Sumali sa AI Model Reasoning Battle Sa OpenAI
Marahil ang pinaka-transformative ay ang self-evolutionary na proseso ng pagsasanay ng rStar-Math. Sa paglipas ng apat na umuulit na pag-ikot, pinipino ng framework ang modelo ng patakaran nito at PPM, na nagsasama ng mas mataas na kalidad na data ng pangangatwiran sa bawat hakbang.
Ang umuulit na diskarte na ito ay nagbibigay-daan sa modelo na patuloy na mapabuti ang pagganap nito, na nakakamit ng mga makabagong resulta nang hindi umaasa sa distillation mula sa mas malalaking modelo.
Paghahambing ng rStar-Math sa OpenAI’s o1
Habang nakatutok ang Microsoft sa pag-optimize ng mas maliliit na modelo, patuloy na inuuna ng OpenAI ang pag-scale ng mga system nito.
o1 Pro Mode, na ipinakilala noong Disyembre 2024 bilang bahagi ng ChatGPT Pro Plan, ay nag-aalok ng mga advanced na kakayahan sa pangangatwiran na iniakma para sa mga high-stakes na application tulad ng coding at siyentipikong pananaliksik. Iniulat ng OpenAI na ang o1 Pro Mode ay nakakuha ng 86% na rate ng katumpakan sa AIME at isang 90% na rate ng tagumpay sa mga benchmark ng coding tulad ng Codeforces.
RStar-Math ay kumakatawan sa pagbabago sa AI innovation, na hinahamon ang pagtuon ng industriya sa mas malalaking modelo. bilang pangunahing paraan ng pagkamit ng advanced na pangangatwiran. Sa pamamagitan ng pagpapahusay sa mga SLM na may mga pag-optimize na partikular sa domain, nag-aalok ang Microsoft ng isang napapanatiling alternatibo na nagpapababa ng mga gastos sa computational at epekto sa kapaligiran.
Kaugnay: Deliberative Alignment: Ang Diskarte sa Kaligtasan ng OpenAI para sa O1 at o3 na Mga Modelo ng Pag-iisip Nito
Ang tagumpay ng framework sa mathematical na pangangatwiran ay nagbubukas ng mga pinto sa mas malawak na aplikasyon, mula sa edukasyon sa siyentipikong pananaliksik.
Plano ng mga mananaliksik na ilabas ang code at data ng rStar-Math sa GitHub, na nagbibigay daan para sa karagdagang pakikipagtulungan at pag-unlad. Ang transparency na ito ay sumasalamin sa diskarte ng Microsoft sa paggawa ng mga high-performance AI tool na naa-access sa mas malawak na audience, kabilang ang mga institusyong pang-akademiko at mga mid-sized na organisasyon.
Kaugnay: SemiAnalysis: Hindi, AI Scaling Isn’t Slowing Down
Habang tumitindi ang kumpetisyon sa pagitan ng Microsoft at OpenAI, ang mga pagsulong na ipinakilala ng rStar-Math ay nagtatampok sa potensyal ng mas maliliit na modelo upang hamunin ang pangingibabaw ng mas malalaking sistema. Sa pamamagitan ng pagbibigay-priyoridad sa kahusayan at katumpakan, nagtatakda ang rStar-Math ng bagong benchmark para sa kung ano ang maaaring makamit ng mga compact AI system.