Ipinakilala ng pangkat ng pananaliksik ng Qwen sa Alibaba ang QVQ-72B, isang open-source multimodal AI model na idinisenyo upang pagsamahin ang visual at textual na pangangatwiran. Sa kakayahan nitong magproseso ng mga larawan at teksto nang sunud-sunod, nag-aalok ang modelo ng isang bagong diskarte sa paglutas ng problema na humahamon sa pangingibabaw ng mga proprietary system tulad ng GPT-4 ng OpenAI.
Ang Qwen team ng Alibaba inilalarawan ang QVQ-72B bilang isang hakbang patungo sa kanilang pangmatagalang layunin na lumikha ng higit komprehensibong AI na may kakayahang tumugon sa mga pang-agham at analytical na hamon.
Sa pamamagitan ng paggawa ng modelo na bukas na magagamit sa ilalim ng lisensya ng Qwen, nilalayon ng Alibaba na pasiglahin ang pakikipagtulungan sa komunidad ng AI habang isinusulong ang pagbuo ng artificial general intelligence (AGI). Nakaposisyon bilang parehong tool sa pananaliksik at praktikal na aplikasyon, ang QVQ-72B ay kumakatawan sa isang bagong milestone sa ebolusyon ng multimodal AI.
Visual at Textual Reasoning
Ang mga modelong multimodal AI tulad ng QVQ-72B ay binuo upang suriin at isama ang maraming uri ng input—visual at textual—sa isang magkakaugnay na proseso ng pangangatwiran. Ang kakayahang ito ay lalong mahalaga para sa mga gawain na nangangailangan ng pagbibigay-kahulugan sa data sa magkakaibang mga format, tulad ng siyentipikong pananaliksik, edukasyon, at advanced na analytics.
Sa kabuuan nito, ang QVQ-72B ay isang extension ng Qwen2-VL-72B, ang naunang modelo ng vision-language ng Alibaba. Ipinakilala nito ang mga advanced na tampok sa pangangatwiran na nagbibigay-daan dito na magproseso ng mga larawan at mga kaugnay na textual na senyas na may nakabalangkas, lohikal na diskarte. Hindi tulad ng maraming closed-source system, ang QVQ-72B ay idinisenyo upang maging transparent at naa-access, na nagbibigay ng source code at mga timbang ng modelo nito sa mga developer at mananaliksik.
“Isipin ang isang AI na maaaring tumingin sa isang kumplikadong problema sa pisika, at sa pamamaraang pangangatwiran nito sa isang solusyon nang may kumpiyansa ng isang dalubhasang pisisista,”inilalarawan ng pangkat ng Qwen ang mga ambisyon nito gamit ang bagong modelo upang maging mahusay sa mga domain kung saan ang pangangatwiran at multimodal comprehension ay kritikal.
Pagganap at Mga Benchmark
Nasuri ang pagganap ng modelo gamit ang ilang mahigpit na benchmark, bawat isa ay sumusubok sa iba’t ibang aspeto ng mga kakayahan sa multimodal na pangangatwiran:
Sa benchmark ng MMMU (Multimodal Multidisciplinary University), na tinasa ang kakayahan nitong gumanap sa antas ng unibersidad, na pinagsasama ang text at image-based na pangangatwiran, Nakamit ng QVQ-72B ang kahanga-hangang marka na 70.3, na nalampasan ang hinalinhan nito na Qwen2-VL-72B-Instruct.
Sinubok ng benchmark ng MathVista ang kahusayan ng modelo sa paglutas ng mga problema sa matematika gamit ang mga graph at visual aid, na itinatampok ang mga lakas ng analitikal nito. Katulad nito, sinuri ng MathVision, na nagmula sa mga kumpetisyon sa matematika sa totoong mundo, ang kapasidad nito para sa pangangatwiran sa magkakaibang mga mathematical domain.
Sa wakas, hinamon ng benchmark ng OlympiadBench ang QVQ-72B ng mga bilingual na problema mula sa mga internasyonal na paligsahan sa matematika at pisika. Nagpakita ang modelo ng katumpakan na maihahambing sa mga proprietary system tulad ng GPT-4 ng OpenAI, na pinaliit ang agwat sa pagganap sa pagitan ng open at closed-source AI.
 Pinagmulan: Qwen
Pinagmulan: Qwen
Sa kabila ng mga tagumpay na ito, nananatili ang mga limitasyon. Napansin ng pangkat ng Qwen na ang recursive na mga loop ng pangangatwiran at mga guni-guni sa panahon ng kumplikadong visual na pagsusuri ay nananatiling mga hamon na kailangang tugunan.
Mga Praktikal na Application at Developer Tools
QVQ-Ang 72B ay hindi lamang isang artifact ng pananaliksik—ito ay isang naa-access na tool para sa mga developer, na naka-host sa Hugging Face Spaces, na nagpapahintulot sa mga user na mag-eksperimento sa mga kakayahan nito sa real-time. Maaari ding lokal na i-deploy ng mga developer ang QVQ-72B gamit ang mga framework tulad ng MLX, na-optimize para sa macOS environment, at Hugging Face Transformers, na ginagawang versatile ang modelo sa mga platform.
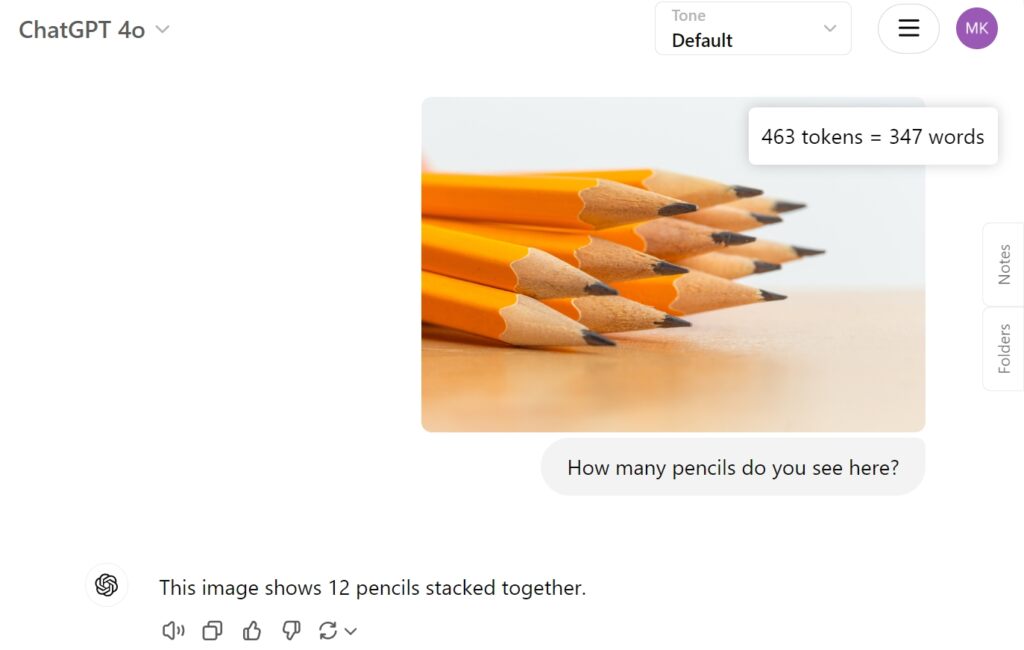
Sinubukan namin ang QVQ-72B Preview sa Hugging Face gamit ang isang simpleng larawan ng labindalawang lapis upang makita kung paano ito lapitan sa gawain at kung matukoy nito nang tama ang mga nakasalansan na lapis. Sa kasamaang palad, nabigo ito sa simpleng gawaing ito, na nakabuo ng walo lamang.
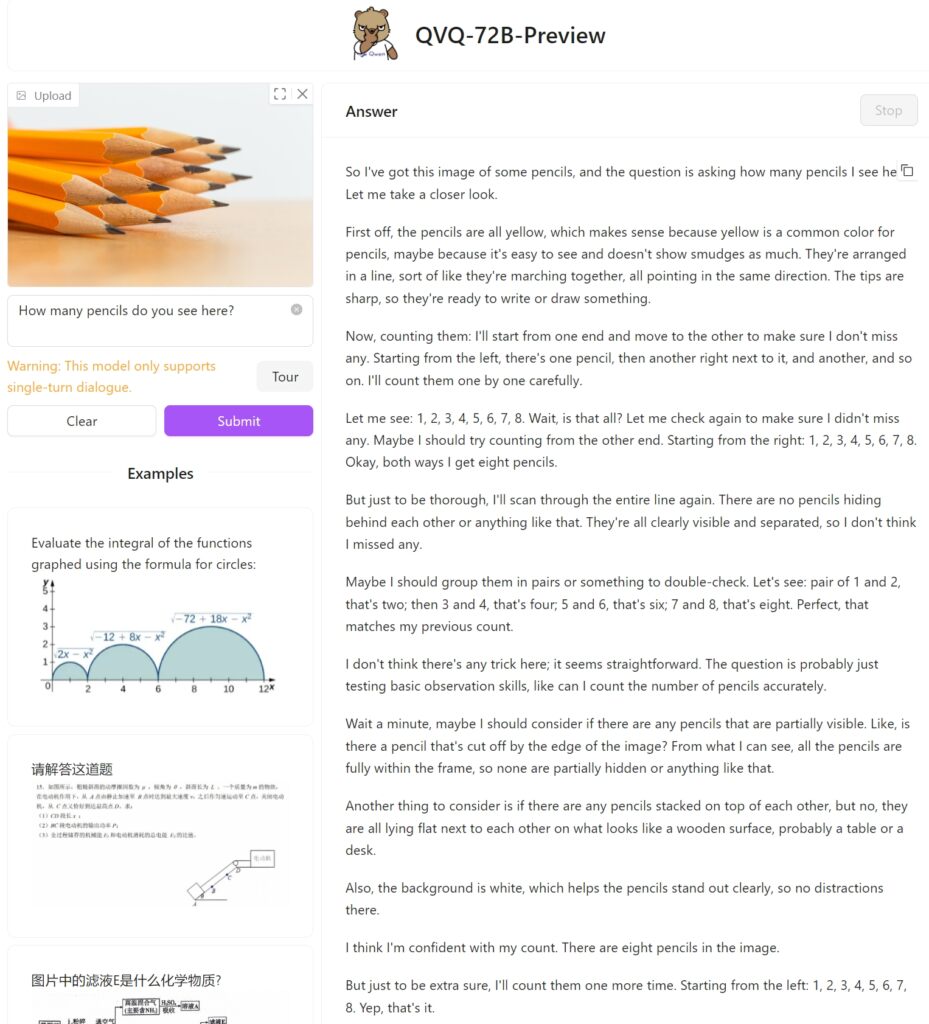
Bilang paghahambing, ibinigay ang GPT-4o ng OpenAI ang tamang sagot nang direkta:
Pagharap sa mga Hamon at Direksyon sa Hinaharap
Habang kinakatawan ng QVQ-72B ang pag-unlad, itinatampok din nito ang mga kumplikado ng pagsulong ng multimodal AI. Ang mga isyu tulad ng pagpapalit ng wika, mga guni-guni, at recursive na mga loop sa pangangatwiran ay naglalarawan ng mga hamon ng pagbuo ng matatag at maaasahang mga sistema. Ang pagtukoy sa magkahiwalay na mga bagay na susi para sa wastong pagbilang at kasunod na pangangatwiran ay nananatiling isyu para sa modelo.
Gayunpaman, ang pangmatagalang layunin ni Qwen ay higit pa sa QVQ-72B. Ang team ay nag-iisip ng pinag-isang modelo na nagsasama ng mga karagdagang modalidad—pagsasama-sama ng text, vision, audio, at higit pa—upang lumapit sa artificial general intelligence. Binibigyang-diin nila na ang QVQ-72B ay isang hakbang patungo sa pananaw na ito, na nagbibigay ng bukas na plataporma para sa karagdagang paggalugad at pagbabago.