Inilunsad ng OpenAI ang deliberative alignment, isang pamamaraan na naglalayong i-embed ang pangangatwiran sa kaligtasan sa mismong pagpapatakbo ng mga artificial intelligence system. Idinisenyo upang tugunan ang mga patuloy na hamon sa kaligtasan ng AI, ang deliberative alignment ay nagbibigay-daan sa mga modelo ng AI na tahasang sumangguni at mangatuwiran tungkol sa mga patakaran sa kaligtasan na tinukoy ng tao sa panahon ng mga real-time na pakikipag-ugnayan.
Ayon sa OpenAI, ang diskarte ay kumakatawan sa isang malaking ebolusyon sa pagsasanay sa kaligtasan ng AI, na lumalampas sa pag-asa sa mga naka-pre-encode na dataset sa mga system na dynamic na nag-a-assess at tumutugon sa mga senyas na may mga desisyon ayon sa konteksto.
Sa mga tradisyunal na AI system, ipinapatupad ang mga mekanismo sa kaligtasan sa panahon ng mga yugto ng pre-training at post-training, kadalasang umaasa sa mga dataset na naka-annotate ng tao upang magpahiwatig ng mga perpektong gawi.
Nauugnay: Nagpakita ang OpenAI ng Bagong O3 Modelo Gamit Lubos na Pinahusay na Mga Kasanayan sa Pangangatuwiran
Ang mga pamamaraang ito, bagama’t batayan, ay maaari mag-iwan ng mga puwang kapag ang mga modelo ay nakatagpo ng mga nobela o kumplikadong mga senaryo na wala sa kanilang data ng pagsasanay. Nag-aalok ang deliberative alignment ng OpenAI ng solusyon sa pamamagitan ng pagbibigay ng mga AI system para aktibong makisali sa mga detalye ng kaligtasan, na tinitiyak na ang mga tugon ay na-calibrate sa etikal, legal, at praktikal na mga hinihingi ng kanilang kapaligiran.
Ayon sa mga mananaliksik ng OpenAI, “[Deliberative alignment] ay ang unang diskarte upang direktang ituro sa isang modelo ang teksto ng mga detalye ng kaligtasan nito at sanayin ang modelo na pag-isipan ang mga detalyeng ito sa hinuha. oras.”
Pagtuturo sa AI Systems na Mag-isip Tungkol sa Kaligtasan
Ang deliberative alignment methodology ay nagsasangkot ng dalawang yugto ng proseso ng pagsasanay na pinagsasama ang pinamamahalaang fine-tuning (SFT) at reinforcement learning (RL), na sinusuportahan ng sintetikong pagbuo ng data na ito ay hindi lamang nagtuturo modelo ang nilalaman ng mga patakaran sa kaligtasan ngunit sinasanay din sila na dynamic na ilapat ang mga alituntuning ito sa panahon ng kanilang operasyon.
Sa supervised fine-tuning phase (SFT), ang mga modelo ng AI ay nakalantad sa isang na-curate na dataset ng mga senyas na ipinares sa mga detalyadong tugon na tahasang tumutukoy sa panloob na mga detalye ng kaligtasan ng OpenAI.
Ang mga ito chain-of-thought (CoT) na mga halimbawa ay naglalarawan kung paano dapat lumapit ang mga modelo sa iba’t ibang mga senaryo, hinahati-hati ang mga kumplikadong prompt sa mas maliit, mapapamahalaan na mga hakbang habang cross-reference ang kaligtasan mga alituntunin. Ang mga output ay sinusuri ng isang panloob na sistema ng AI, na kadalasang tinutukoy bilang”hukom,”na tinatasa ang kanilang pagsunod sa mga pamantayan ng patakaran.
Nauugnay: Ang CEO ng OpenAI na si Sam Altman ay Pag-aari at Nabenta Dati Hindi Kilalang OpenAI Stake
Ang reinforcement learning phase ay higit na nagpapahusay sa mga kakayahan ng modelo sa pamamagitan ng pagpino sa proseso ng pangangatwiran nito Gamit ang feedback mula sa judge model, ang sistema nang paulit-ulit pinapabuti nito ang kakayahang mangatwiran sa pamamagitan ng nuanced o hindi maliwanag na mga senyas, na mas malapit sa etikal at operational na mga priyoridad ng OpenAI.
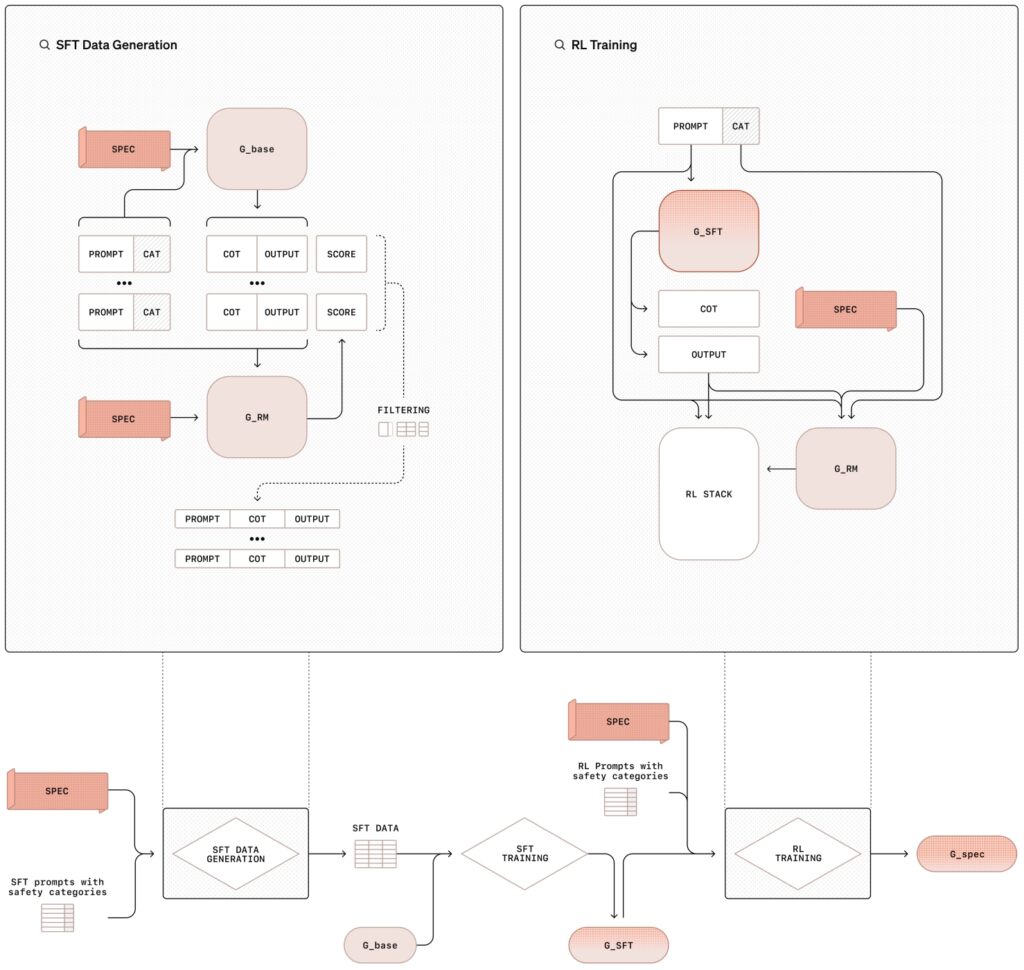 Ilustrasyon ng sinadyang pamamaraan ng pag-align na may pinangangasiwaang fine-tuning (SFT) at reinforcement learning (RL) (Larawan: OpenAI)
Ilustrasyon ng sinadyang pamamaraan ng pag-align na may pinangangasiwaang fine-tuning (SFT) at reinforcement learning (RL) (Larawan: OpenAI)
Isang pangunahing pagbabago dito Ang pamamaraan ay ang paggamit ng sintetikong data—mga halimbawang nabuo ng iba pang mga modelo ng AI—na pumapalit sa pangangailangan para sa mga dataset na may label na tao. Hindi lamang nito sinusukat ang proseso ng pagsasanay ngunit tinitiyak din nito ang mataas na antas ng katumpakan sa pag-align ng mga gawi ng modelo sa mga kinakailangan sa kaligtasan.
Tulad ng sinabi ng mga mananaliksik ng OpenAI, “Nakakamit ng pamamaraang ito ang lubos na tumpak na pagsunod sa detalye, umaasa lamang sa data na binuo ng modelo. Kinakatawan nito ang isang scalable na diskarte sa pag-align.”
Pagharap sa Mga Jailbreak at Overrefusals
Dalawa sa mga pinaka-paulit-ulit na isyu sa kaligtasan ng AI ay ang kahinaan ng modelo sa mga pagtatangka sa jailbreak at ang tendensya nito na labis na tumanggi sa mga benign na senyas ay nagsasangkot ng mga adversarial na senyas na idinisenyo upang i-bypass ang mga pananggalang, na kadalasang nakatago o naka-encode sa mga paraan na. gawing hindi kaagad malinaw ang kanilang layunin. Naidokumento kamakailan ng mga mananaliksik kung paano kahit na ang mga maliliit na pag-tweak ng mga character na ginamit para sa isang prompt ay maaaring mag-jailbreak ng mga kasalukuyang modelo ng hangganan.
Ang mga labis na pagtanggi, sa kabilang banda, ay nangyayari kapag ang mga masyadong maingat na modelo ay humaharang sa hindi nakakapinsalang mga query. ng kasaganaan ng pag-iingat, nakakadismaya sa mga user at nililimitahan ang utility ng system.
Ang deliberative alignment ay partikular na idinisenyo upang matugunan ang mga hamong ito ni nilagyan ang mga modelo ng kakayahang mangatwiran sa pamamagitan ng layunin at konteksto ng mga senyas, pinahuhusay ng pamamaraan ang kanilang kakayahang labanan ang mga pag-atake ng kalaban habang pinapanatili ang pagtugon sa mga lehitimong query.
Nauugnay: AI Safety Index 2024 Resulta: OpenAI, Google, Meta, xAI Fall Short; Anthropic on Top
Halimbawa, kapag ipinakita ang isang disguised na kahilingan na gumawa ng mapaminsalang content, ang isang modelong sinanay na may deliberative alignment ay maaaring mag-decode ng input, mga patakaran sa kaligtasan ng pagsangguni, at magbigay ng makatuwirang pagtanggi.
Katulad nito, kapag tinanong ang isang hindi magandang tanong tungkol sa mga kontrobersyal na paksa, tulad ng kasaysayan ng pagbuo ng armas nukleyar, ang modelo ay maaaring magbigay ng tumpak na impormasyon nang hindi lumalabag sa mga alituntunin sa kaligtasan.
Sa kanilang mga natuklasan sa pananaliksik, Binigyang-diin ng OpenAI na ang mga modelong sinanay na may deliberative alignment ay may kakayahang tukuyin ang layunin sa likod ng naka-encode o disguised prompt, na nangangatuwiran sa pamamagitan ng kanilang mga patakaran sa kaligtasan upang matiyak ang pagsunod.
Mga Halimbawa ng Real-World ng Deliberative Alignment in Action
Inilalarawan ng OpenAI ang mga praktikal na implikasyon ng deliberative alignment sa pamamagitan ng real-world na mga kaso ng paggamit. Sa isang ibinigay na halimbawa, ang isang user ay nag-prompt ng isang AI system para sa mga detalyadong tagubilin sa pagpeke ng isang parking placard.
Kinikilala ng modelo ang layunin ng kahilingan bilang mapanlinlang, tinutukoy ang patakaran ng OpenAI laban sa pagpapagana ng ilegal na aktibidad, at tumatangging sumunod. Hindi lang pinipigilan ng tugon na ito ang maling paggamit ngunit ipinapakita rin ang kakayahan ng system na magkonteksto at mangatuwiran tungkol sa mga patakaran sa kaligtasan nang dynamic.
Sa isa pang sitwasyon, nahaharap ang modelo sa isang naka-encode na prompt na humihiling ng bawal na payo. Gamit ang mga kakayahan nito sa pangangatwiran, ang system ay nagde-decode ng input, nag-cross-reference sa mga detalye ng kaligtasan nito, at tinutukoy na ang query ay lumalabag sa mga etikal na alituntunin ng OpenAI. Pagkatapos ay nagbibigay ang modelo ng paliwanag sa pagtanggi nito, na nagpapatibay ng transparency sa proseso ng paggawa ng desisyon nito.
Ang mga halimbawa ay nagha-highlight sa kakayahan ng deliberative alignment na magbigay ng mga AI system ng mga tool na kailangan para mag-navigate sa mga kumplikado at etikal na sensitibong sitwasyon, tinitiyak ang parehong pagsunod sa mga patakaran at transparency ng user.
Kaugnay: Hinihimok ng Meta ang Legal na Pag-block sa Transition ng OpenAI sa For-Profit Entity
Pagpapalawak sa Saklaw ng Deliberative Alignment
Nagagawa ng Deliberative alignment ang higit pa sa pagpapagaan ng mga panganib; nagbubukas din ito ng pinto para sa mga AI system na gumana nang may higit na transparency at pananagutan. Sa pamamagitan ng pagpapagana sa mga modelo na tahasang ipahayag ang kanilang pangangatwiran, ipinakilala ng OpenAI ang isang framework kung saan mas mauunawaan ng mga user ang lohika sa likod ng mga tugon ng AI.
Ang transparency na ito ay partikular na mahalaga sa mga application na may mataas na stake kung saan ang mga etikal o legal na pagsasaalang-alang ay pinakamahalaga, tulad ng pangangalaga sa kalusugan, pananalapi, at pagpapatupad ng batas.
Halimbawa, kapag ang mga user ay nakikipag-ugnayan sa mga modelo sinanay sa ilalim ng deliberative alignment, ang chain-of-thought reasoning ay hindi lamang panloob ngunit maaaring ibahagi bilang bahagi ng output ng modelo.
Ang isang user na naghahanap ng paglilinaw kung bakit tumanggi ang isang modelo sa isang kahilingan ay maaaring makatanggap ng paliwanag na tumutukoy sa mga partikular na patakaran sa kaligtasan, kasama ang sunud-sunod na breakdown kung paano nakarating ang system sa pagtatapos nito. Ang antas ng detalyeng ito ay hindi lamang bumubuo ng tiwala ngunit hinihikayat din ang responsableng paggamit ng mga teknolohiya ng AI.
Idiniin ng OpenAI na ang transparency sa paggawa ng desisyon ng AI ay mahalaga para sa pagbuo ng tiwala at pagtiyak ng etikal na paggamit, na may deliberative alignment na nagbibigay-daan sa mga system na magpaliwanag malinaw ang kanilang pag-uugali.
Kaugnay: Deep Dive: Paano Nilinlang ng Bagong Modelo ng OpenAI ang mga Tao
Synthetic Data: The Backbone of Scalable AI Safety
Ang isang mahalagang bahagi ng deliberative alignment ay ang paggamit ng sintetikong data, na pumapalit sa tradisyonal na mga dataset na may label na tao. Ang pagbuo ng data ng pagsasanay mula sa mga system ng AI sa halip na umasa sa mga anotasyon ng tao ay nag-aalok ng ilang mga pakinabang, kabilang ang scalability, kahusayan sa gastos, at katumpakan.
Maaaring iayon ang sintetikong data upang matugunan ang mga partikular na hamon sa kaligtasan, na nagpapahintulot sa OpenAI na lumikha ng mga dataset na malapit na umaayon sa mga priyoridad sa pagpapatakbo nito.
Ang synthetic data pipeline ng OpenAI ay nagsasangkot ng pagbuo ng mga halimbawa ng mga senyas at kaukulang chain-of-thought na mga tugon gamit ang base AI model. Ang mga halimbawang ito ay susuriin at sinasala ng modelong”hukom”upang matiyak na natutugunan ng mga ito ang ninanais na kalidad at pamantayan sa pagkakahanay.
Kapag naaprubahan, ang data ay gagamitin sa pinangangasiwaang fine-tuning at reinforcement na mga yugto ng pag-aaral, kung saan sinasanay nito ang target na modelo na tahasang mangatuwiran tungkol sa mga patakaran sa kaligtasan.
“Ang synthetic data generation ay nagbibigay-daan sa amin na sukatin ang pagsasanay sa kaligtasan ng AI nang hindi nakompromiso ang kalidad o katumpakan ng pagkakahanay,”binigyang-diin ng mga mananaliksik ng OpenAI.”Ang diskarteng ito ay tumutugon sa isa sa mga pangunahing bottleneck sa mga tradisyunal na pamamaraan ng kaligtasan, na kadalasang umaasa nang husto sa paggawa ng tao para sa data annotation.”
Ang pag-asa sa synthetic na data ay nagsisiguro rin ng pare-pareho sa pagsasanay. Ang mga annotator ng tao ay maaaring magpakilala ng pagkakaiba-iba dahil sa mga pagkakaiba sa interpretasyon, ngunit ang mga halimbawang binuo ng AI ay nagbibigay ng standardized na baseline sa nuanced ethical dilemmas.
Related: OpenAI and Anduril Forge Partnership for U.S. Military Drone Defense
Outperforming Competitors in Key Metrics
Sinubukan ng OpenAI ang deliberative alignment laban sa mga nangungunang benchmark sa kaligtasan higit na mahusay ang mga kakumpitensya, na nakakakuha ng matataas na marka sa parehong katatagan at kakayahang tumugon.
Ang o1 at mga kaugnay na modelo ay mahigpit na nasubok laban sa mga sistemang mapagkumpitensya, kabilang ang GPT-4o, Gemini 1.5 Pro, at Claude 3.5 Sonnet, sa iba’t ibang uri ng mga sukatan ng kaligtasan. Sa StrongREJECT, na sumusukat sa paglaban ng isang modelo sa mga adversarial jailbreak, ang mga modelo ng OpenAI na o1 ay patuloy na nakakuha ng mas mataas na marka, na nagpapakita ng kanilang advanced na kakayahang tumukoy at mag-block ng mga nakakapinsalang prompt.
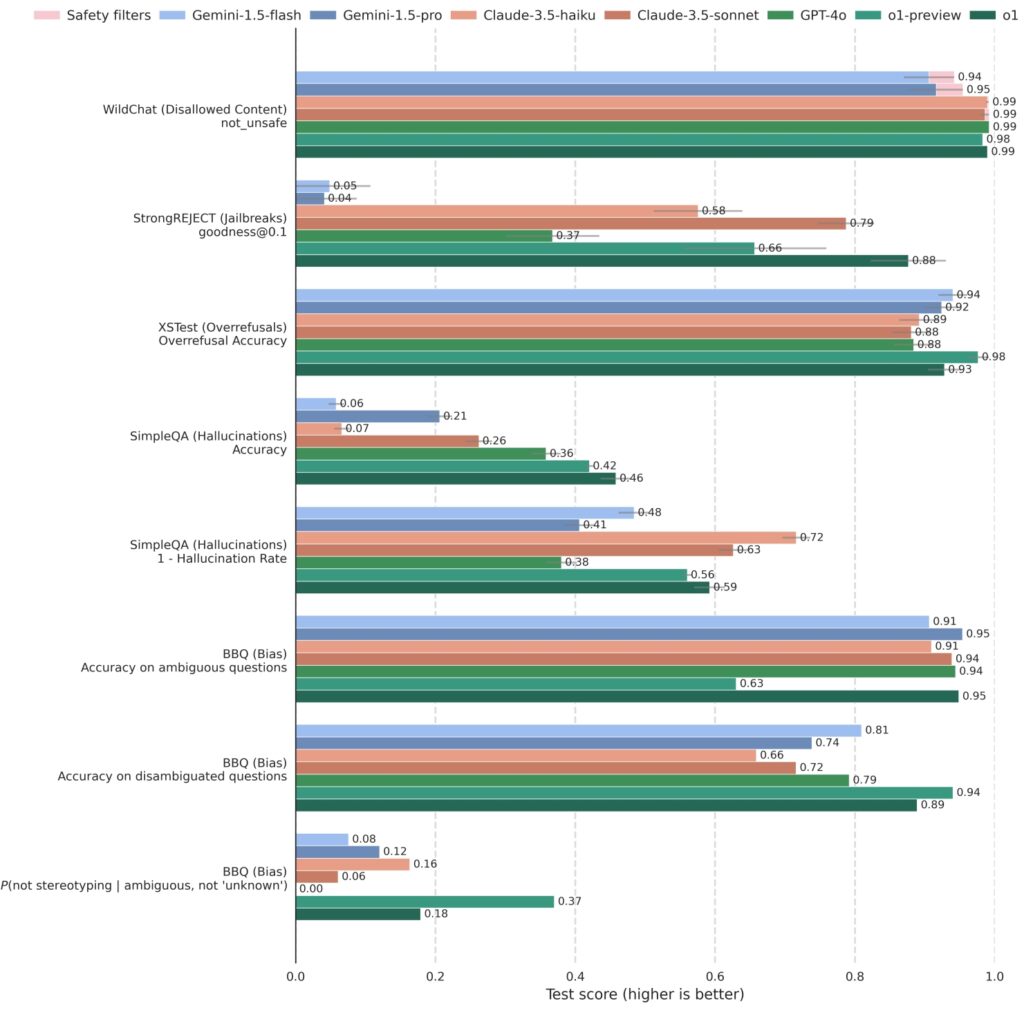 o1 ay mapagkumpitensya kumpara sa iba pang nangungunang mga modelo sa mga benchmark na nagtatasa ng hindi pinapayagang nilalaman (WildChat), mga jailbreak (StrongREJECT), labis na pagtanggi (XSTest), guni-guni (SimpleQA), at bias (BBQ). Ang ilang kahilingan sa API ay
o1 ay mapagkumpitensya kumpara sa iba pang nangungunang mga modelo sa mga benchmark na nagtatasa ng hindi pinapayagang nilalaman (WildChat), mga jailbreak (StrongREJECT), labis na pagtanggi (XSTest), guni-guni (SimpleQA), at bias (BBQ). Ang ilang kahilingan sa API ay
na-block dahil sa sensitibong katangian ng nilalaman. Ang mga kasong ito ay naitala bilang”Na-block ng mga filter ng kaligtasan”
sa WildChat at hindi kasama sa iba pang mga benchmark. Tinatantya ang mga error bar gamit ang bootstrap resampling sa
sa 0.95 na antas. (Pinagmulan: OpenAI)
Higit pa rito, ang mga modelo ng o1 ay mahusay sa pagbabalanse ng kaligtasan sa pagiging tumutugon Sa XSTest, na sinusuri ang mga labis na pagtanggi, ang mga modelo ay nagpakita ng isang pinababang tendensya na tanggihan ang mga benign prompt habang pinapanatili ang mahigpit na pagsunod sa mga alituntunin sa kaligtasan mananatiling kapaki-pakinabang at naa-access nang hindi nakompromiso ang mga pamantayang etikal.
Sinasabi ng OpenAI na ang deliberative alignment ay nagpapabuti sa AI kaligtasan sa pamamagitan ng pagbabawas ng mga mapaminsalang output habang pinapataas ang katumpakan sa pagtugon sa mga benign na pakikipag-ugnayan.
Nauugnay: Paano Maaaring Neutralisahin ng Pagpindot sa”Stop”sa ChatGPT ang Mga Safeguard nito
Mas malawak na Implikasyon para sa Pag-unlad ng AI
Ang pagpapakilala ng deliberative alignment ay nagmamarka ng punto ng pagbabago sa kung paano sinasanay at itinatakda ang mga AI system sa OpenAI at marahil din ng iba sa hinaharap.
Sa pamamagitan ng pag-embed ng tahasang pangangatwiran sa kaligtasan sa pangunahing functionality ng mga modelo nito, ang OpenAI ay lumikha ng isang balangkas na hindi lamang tumutugon sa mga kasalukuyang hamon ngunit inaasahan din ang mga panganib sa hinaharap. Habang nagiging mas may kakayahan ang mga AI system, tumataas ang potensyal para sa maling paggamit o hindi sinasadyang mga kahihinatnan, na ginagawang mas kritikal kaysa dati ang mga matatag na hakbang sa kaligtasan.
Nagsisilbi rin ang deliberative alignment bilang isang modelo para sa mas malawak na komunidad ng AI. Ang pag-asa nito sa mga scalable na diskarte tulad ng synthetic na data at ang pagbibigay-diin nito sa transparency ay nagbibigay ng blueprint para sa iba pang organisasyong naglalayong ihanay ang kanilang mga AI system sa mga etikal at societal na halaga.