Ang mga mananaliksik sa Sakana AI, isang startup ng AI na nakabase sa Tokyo, ay nagpakilala ng isang bagong memory optimization system na nagpapahusay sa kahusayan ng mga modelong nakabatay sa Transformer, kabilang ang malalaking modelo ng wika (LLMs).
Ang pamamaraan, tinatawag na Neural Attention Memory Models (NAMMs) na available sa pamamagitan ng buong code ng pagsasanay sa GitHub, binabawasan ang paggamit ng memory ng hanggang 75% habang pinapabuti ang pangkalahatang pagganap. Sa pamamagitan ng pagtutok sa mahahalagang token at pag-aalis ng kalabisan na impormasyon, tinutugunan ng mga NAMM ang isa sa mga hamon na may pinakamaraming mapagkukunan sa modernong AI: pamamahala ng mahabang mga window ng konteksto.
Ang mga modelo ng transformer, ang gulugod ng mga LLM, ay umaasa sa”mga window ng konteksto”upang iproseso ang data ng input na ito ay nag-iimbak ng”mga key-value pairs”(KV cache) para sa bawat token sa input sequence.
Habang lumalaki ang haba ng window—ngayon ay umaabot na sa daan-daang libong mga token—ang Ang pagkalkula ng gastos ay tumataas. Sinubukan ng mga naunang solusyon na bawasan ang gastos na ito sa pamamagitan ng manu-manong token pruning o mga diskarte sa heuristic ngunit kadalasan ay nagpapababa sa pagganap. Ang mga NAMM, gayunpaman, ay gumagamit ng mga neural network na sinanay sa pamamagitan ng evolutionary optimization upang i-automate at pinuhin ang proseso ng pamamahala ng memory.
Memory Optimization na may mga NAMM
Sinasuri ng mga NAMM ang mga halaga ng atensyon binuo ng mga Transformers upang matukoy ang kahalagahan ng token. Pinoproseso nila ang mga halagang ito sa mga spectrogram—mga representasyong nakabatay sa dalas na karaniwang ginagamit sa pagproseso ng audio at signal—upang i-compress at kunin ang mga pangunahing tampok ng mga pattern ng atensyon.
Ang impormasyong ito ay ipinapasa sa isang magaan na neural network na nagtatalaga ng marka sa bawat token, na nagpapasya kung ito ay dapat panatilihin o itapon.
Ang Sakana AI ay nagha-highlight kung paano hinihimok ng mga evolutionary algorithm ang mga NAMM’tagumpay. Hindi tulad ng tradisyonal na gradient-based na mga pamamaraan, na hindi tugma sa binary na mga desisyon tulad ng”tandaan”o”kalimutin,”paulit-ulit na sinusubok at pinipino ng evolutionary optimization ang mga diskarte sa memorya para ma-maximize ang downstream na performance.
“Likas na nadadaig ng ebolusyon ang hindi pagkakaiba-iba. ng aming mga pagpapatakbo sa pamamahala ng memorya, na kinabibilangan ng binary na’tandaan’o’kalimutan’na mga resulta,”paliwanag ng mga mananaliksik.
Mga Napatunayang Resulta sa Mga Benchmark
Upang mapatunayan ang pagganap at kahusayan ng Neural Attention Memory Models (NAMMs), nagsagawa ang Sakana AI ng malawak na pagsubok sa maraming benchmark na nangunguna sa industriya na idinisenyo upang masuri ang pangmatagalan. pagpoproseso ng konteksto at mga kakayahan sa maraming gawain. Binibigyang-diin ng mga resulta ang kakayahan ng mga NAMM na makabuluhang mapabuti ang pagganap habang binabawasan ang mga kinakailangan sa memorya, na nagpapatunay ng kanilang pagiging epektibo sa iba’t ibang balangkas ng pagsusuri.
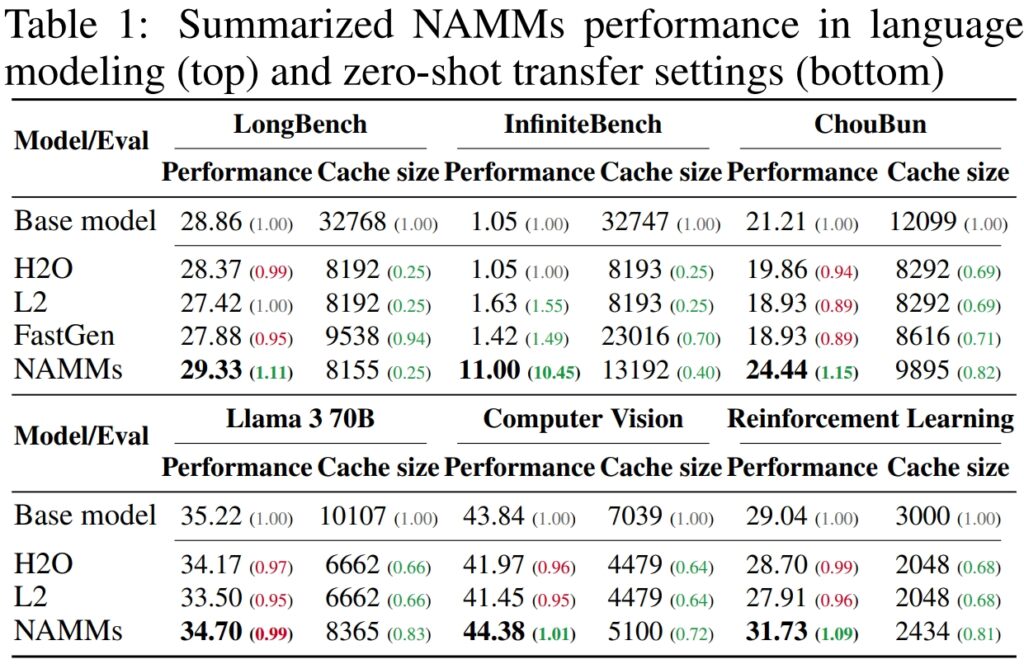
Sa LongBench, isang benchmark na partikular na ginawa upang sukatin ang pagganap ng mga modelo sa mga gawaing may mahabang konteksto, nakamit ng mga NAMM ang 11% pagpapabuti sa katumpakan kumpara sa full-context na baseline na modelo. Nakamit ang pagpapahusay na ito habang binabawasan ang paggamit ng memory ng 75%, na itinatampok ang kahusayan ng pamamaraan sa pamamahala ng key-value (KV) cache.
Sa pamamagitan ng matalinong pagpuputol ng mga hindi gaanong nauugnay na token, pinahintulutan ng mga NAMM ang modelo na tumuon sa kritikal na konteksto nang hindi isinasakripisyo ang mga resulta, na ginagawa itong perpekto para sa mga sitwasyong nangangailangan ng mga pinahabang input, gaya ng pagsusuri sa dokumento o mahabang pagsagot sa tanong.
p>
Para sa InfiniteBench, isang benchmark na itinutulak ang mga modelo sa kanilang mga limitasyon na may napakahabang sequence—ang ilan ay lampas sa 200,000 token—ipinakita ng mga NAMM ang kanilang kakayahang sumukat nang epektibo.
Habang ang mga baseline na modelo ay nahihirapan sa computational na hinihingi ng mga ganoong katagal na input, nakamit ng mga NAMM ang isang dramatikong pagpapalakas ng performance, na nagdaragdag ng katumpakan mula 1.05% hanggang 11.00%.
Partikular na kapansin-pansin ang resultang ito dahil ipinapakita nito ang kapasidad ng mga NAMM na pangasiwaan ang napakahabang konteksto, isang kakayahan na lalong mahalaga para sa mga application tulad ng pagproseso ng siyentipikong literatura, legal na dokumento, o malalaking code repository kung saan ang laki ng input ng token ay napakalaki.
Sa sariling ChouBun benchmark ng Sakana AI, na sinusuri mahabang kontekstong pangangatwiran para sa mga gawain sa wikang Japanese, naghatid ang mga NAMM ng 15% na pagpapabuti sa baseline. Tinutugunan ng ChouBun ang isang puwang sa mga kasalukuyang benchmark, na may posibilidad na tumuon sa mga wikang English at Chinese, sa pamamagitan ng pagsubok ng mga modelo sa pinahabang Japanese na mga text input.
Ang tagumpay ng mga NAMM sa ChouBun ay nagha-highlight sa kanilang versatility sa mga wika at nagpapatunay ng kanilang katatagan sa paghawak ng mga hindi English na input—isang pangunahing tampok para sa mga global AI application. Nagagawa ng mga NAMM na mahusay na mapanatili ang content na partikular sa konteksto habang itinatapon ang mga grammatical redundancies at hindi gaanong makabuluhang mga token, na nagbibigay-daan sa modelo na gumanap nang mas epektibo sa mga gawain tulad ng long-form summarization at comprehension sa Japanese.
 Pinagmulan: Sakana AI
Pinagmulan: Sakana AI
Ang sama-samang ipinapakita ng mga resulta na ang mga NAMM ay mahusay sa pag-optimize ng paggamit ng memory nang hindi nakompromiso ang katumpakan. Sinuri man sa mga gawaing nangangailangan ng napakahabang pagkakasunud-sunod o sa mga konteksto ng hindi Ingles na wika, ang mga NAMM ay patuloy na nangunguna sa mga baseline na modelo, na nakakamit ng parehong kahusayan sa pagkalkula at pinahusay na mga resulta.
Ang kumbinasyong ito ng pagtitipid at katumpakan ng memorya ay nakakakuha ng mga posisyon sa NAMM bilang isang mahusay na pag-unlad para sa mga enterprise AI system na inatasan sa paghawak ng malalawak at kumplikadong mga input.
Ang mga resulta ay partikular na kapansin-pansin kumpara sa mga naunang pamamaraan tulad ng H₂O at L2, na nagsakripisyo ng performance para sa kahusayan. Ang mga NAMM, sa kabilang banda, ay nakakamit pareho.
“Ang aming mga resulta ay nagpapakita na ang mga NAMM ay matagumpay na nagbibigay ng pare-parehong mga pagpapabuti sa parehong pagganap at kahusayan na may kaugnayan sa baseline Transformers,”sabi ng mga mananaliksik.
Cross-Modal Applications: Beyond Language
Isa sa mga pinakakahanga-hangang natuklasan ay ang kakayahan ng mga NAMM na ilipat ang zero-shot sa iba pang mga gawain at input modalities.
Isa sa mga pinaka-kapansin-pansing aspeto ng Neural Attention Memory Models (NAMMs) ay ang kanilang kakayahang maglipat ng walang putol sa iba’t ibang gawain at input modalities—higit pa sa tradisyonal na mga application na nakabatay sa wika
Hindi tulad ng iba mga paraan ng pag-optimize ng memorya, na kadalasang nangangailangan ng muling pagsasanay o pag-fine-tuning para sa bawat domain, pinapanatili ng mga NAMM ang kanilang kahusayan at mga benepisyo sa pagganap nang walang karagdagang mga pagsasaayos na ipinakita ito ng mga eksperimento ng Sakana AI versatility sa dalawang pangunahing domain: computer vision at reinforcement learning, na parehong nagpapakita ng mga natatanging hamon para sa Transformer-based na mga modelo.
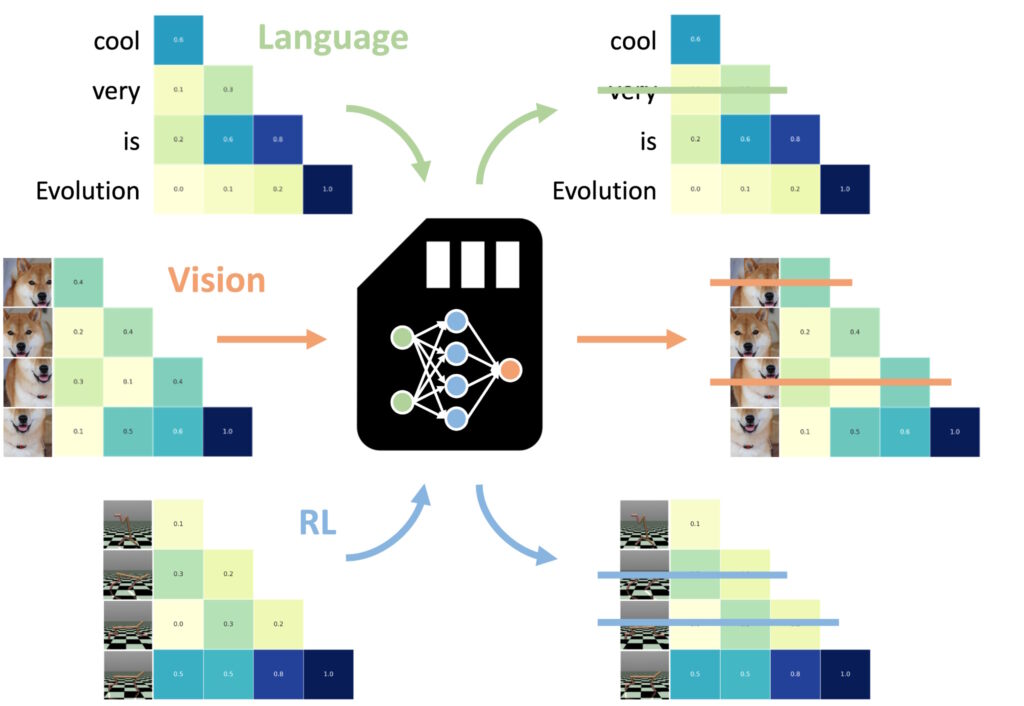 Mga NAMM na sinanay sa ang wika ay maaaring zero-shot na ilipat sa iba pang mga transformer sa lahat ng input modalities at mga domain ng gawain. (Larawan: Sakana AI)
Mga NAMM na sinanay sa ang wika ay maaaring zero-shot na ilipat sa iba pang mga transformer sa lahat ng input modalities at mga domain ng gawain. (Larawan: Sakana AI)
Sa computer vision, nasuri ang mga NAMM gamit ang Llava Next Video model, isang Idinisenyo ang transpormer para sa pagproseso ng mahabang pagkakasunud-sunod ng video. Ang mga video ay likas na naglalaman ng napakaraming redundant na data, tulad ng mga paulit-ulit na frame o menor de edad na variation na nagbibigay ng kaunting karagdagang impormasyon.
Awtomatikong natukoy at itinapon ng mga NAMM ang mga kalabisan na frame na ito sa panahon ng hinuha, na epektibong na-compress ang window ng konteksto nang hindi nakompromiso ang kakayahan ng modelo na bigyang-kahulugan ang nilalamang video.
Halimbawa, nagpapanatili ang mga NAMM ng mga frame na may mahahalagang visual na detalye—tulad ng mga pagbabago sa pagkilos, pakikipag-ugnayan sa bagay, o kritikal na kaganapan—habang inaalis ang mga paulit-ulit o static na frame. Nagresulta ito sa pinahusay na kahusayan sa pagpoproseso, na nagpapahintulot sa modelo na tumuon sa mga pinakanauugnay na visual na elemento, sa gayon ay nagpapanatili ng katumpakan habang binabawasan ang mga gastos sa computational.
Sa reinforcement learning, inilapat ang mga NAMM sa Decision Transformer, isang modelo na idinisenyo upang iproseso ang mga pagkakasunud-sunod ng mga aksyon, mga obserbasyon, at mga gantimpala upang ma-optimize ang mga gawain sa paggawa ng desisyon. Ang mga gawain sa pag-aaral ng reinforcement ay kadalasang nagsasangkot ng mahabang pagkakasunud-sunod ng mga input na may iba’t ibang antas ng kaugnayan, kung saan ang mga suboptimal o kalabisan na pagkilos ay maaaring makahadlang sa pagganap.
Tumugon ang mga NAMM sa hamong ito sa pamamagitan ng piling pag-alis ng mga token na tumutugma sa mga hindi mahusay na pagkilos at impormasyong mababa ang halaga habang pinapanatili ang mga kritikal sa pagkamit ng mas mahusay na mga resulta.
Halimbawa, sa mga gawain tulad ng Hopper at Walker2d—na kinasasangkutan ng pagkontrol sa mga virtual na ahente sa tuluy-tuloy na paggalaw—pinahusay ng mga NAMM ang pagganap nang higit sa 9%. Sa pamamagitan ng pag-filter ng mga suboptimal na paggalaw o hindi kinakailangang mga detalye, nakamit ng Decision Transformer ang mas mahusay at epektibong pag-aaral, na nakatuon ang kapangyarihan nito sa pag-compute sa mga desisyon na nag-maximize ng tagumpay sa gawain.
Hina-highlight ng mga resultang ito ang kakayahang umangkop ng mga NAMM sa iba’t ibang domain. Nagpoproseso man ng mga video frame sa mga modelo ng vision o nag-o-optimize ng mga pagkakasunud-sunod ng pagkilos sa reinforcement learning, ipinakita ng mga NAMM ang kanilang kakayahan na pahusayin ang performance, bawasan ang paggamit ng resource, at panatilihin ang katumpakan ng modelo—lahat nang walang retraining.
Natututo ang mga NAMM na kalimutan ang halos eksklusibong mga bahagi ng mga kalabisan na video frame, sa halip na ang mga token ng wika na naglalarawan sa huling prompt, ang mga tala sa papel, na nagha-highlight sa kakayahang umangkop ng mga NAMM.
Mga Teknikal na Salungguhit ng mga NAMM
Ang kahusayan at pagiging epektibo ng Neural Attention Memory Models (NAMMs) ay nakasalalay sa kanilang streamlined at sistematikong proseso ng pagpapatupad, na nagbibigay-daan sa tumpak na pag-pruning ng token nang walang manu-manong interbensyon. Ang prosesong ito ay binuo sa tatlong pangunahing bahagi: attention spectrograms, feature compression, at automated scoring.
Dinamic na inaayos ng mga NAMM ang kanilang gawi depende sa mga kinakailangan sa gawain at lalim ng layer ng Transformer. Ang mga unang layer ay inuuna ang”global”na konteksto tulad ng mga paglalarawan ng gawain, habang ang mga mas malalalim na layer ay nagpapanatili ng”lokal”na mga detalyeng partikular sa gawain. Sa mga gawain sa coding, halimbawa, itinapon ng mga NAMM ang mga komento at boilerplate code; sa mga gawain sa natural na wika, inalis nila ang mga redundancy ng gramatika habang pinapanatili ang pangunahing nilalaman.
Ang adaptive na pagpapanatili ng token na ito ay tumitiyak na ang mga modelo ay mananatiling nakatuon sa nauugnay na impormasyon sa buong pagproseso, pagpapabuti ng bilis at katumpakan.
Ang una Ang hakbang ay kinabibilangan ng pagbuo ng Attention Spectrograms. Kinakalkula ng mga transformer ang”mga halaga ng pansin”sa bawat layer upang matukoy ang kaugnay na kahalagahan ng bawat token sa loob ng window ng konteksto. Binabago ng mga NAMM ang mga halaga ng atensyon na ito sa mga representasyong nakabatay sa dalas gamit ang Short-Time Fourier Transform (STFT).
Ang STFT ay isang malawakang ginagamit na diskarte sa pagpoproseso ng signal na naghahati-hati sa isang sequence sa mga localized na bahagi ng frequency sa paglipas ng panahon, na nagbibigay ng isang compact ngunit detalyadong representasyon ng kahalagahan ng token i-convert ang raw attention sequence sa spectrogram-like data, na nagbibigay-daan sa isang mas malinaw na pagsusuri kung aling mga token ang nag-aambag nang makabuluhan sa output ng modelo.
Susunod, Feature Ang compressionay inilapat upang bawasan ang dimensionality ng spectrogram data habang pinapanatili ang mga mahahalagang katangian nito. Ito ay nakakamit gamit ang isang exponential moving average (EMA), isang mathematical na pamamaraan na nag-compress sa mga pattern ng pansin sa kasaysayan sa isang compact, fixed-size na buod. Tinitiyak ng EMA na ang mga representasyon ay mananatiling magaan at mapapamahalaan, na nagbibigay-daan sa mga NAMM na suriin ang mahabang pagkakasunud-sunod ng atensyon nang mahusay habang pinapaliit ang computational overhead.
Ang huling hakbang ay Pagmamarka at Pruning, kung saan ang mga NAMM ay gumagamit ng magaan na timbang. neural network classifier upang suriin ang mga naka-compress na representasyon ng token at magtalaga ng mga marka batay sa kanilang kahalagahan. Ang mga token na may mga markang mas mababa sa tinukoy na threshold ay pinuputol mula sa window ng konteksto, na epektibong”nakakalimutan”ang mga hindi nakakatulong o kalabisan na mga detalye. Ang mekanismo ng pagmamarka na ito ay nagbibigay-daan sa mga NAMM na unahin ang mga kritikal na token na nag-aambag sa proseso ng paggawa ng desisyon ng modelo habang itinatapon ang hindi gaanong nauugnay na data.
Ang partikular na ginagawang epektibo sa mga NAMM ay ang kanilang pag-asa sa evolutionary optimization upang pinuhin ang prosesong ito mga pamamaraan tulad ng gradient descent na pakikibaka sa mga hindi nakikilalang gawain—gaya ng pagpapasya kung ang isang token ay dapat panatilihin o itapon
Sa halip, ang mga NAMM ay gumagamit ng umuulit na evolutionary algorithm, na inspirasyon ng natural na seleksyon, upang”mag-mutate”at”. piliin ang”pinakamahusay na mga diskarte sa pamamahala ng memorya sa paglipas ng panahon. Sa pamamagitan ng paulit-ulit na pagsubok, nagbabago ang system upang awtomatikong bigyang-priyoridad ang mga mahahalagang token, na nakakamit ng balanse sa pagitan ng pagganap at memory efficiency nang hindi nangangailangan ng manu-manong fine-tuning.
Itong streamlined na pagpapatupad—pagsasama-sama ng spectrogram-based token analysis, mahusay na compression, at automated pruning—ay nagbibigay-daan sa mga NAMM na maghatid ng parehong makabuluhang memory savings at performance gains sa iba’t ibang Transformer-based mga gawain. Sa pamamagitan ng pagbabawas ng mga kinakailangan sa pag-compute habang pinapanatili o pinapabuti ang katumpakan, nagtakda ang mga NAMM ng bagong benchmark para sa mahusay na pamamahala ng memory sa mga modernong modelo ng AI.
Ano ang Susunod para sa Mga Transformer?
Naniniwala si Sakana AI na ang mga NAMM ay simula lamang. Habang ang kasalukuyang gawain ay nakatuon sa pag-optimize ng mga pre-trained na modelo sa hinuha, maaaring isama ng pananaliksik sa hinaharap ang mga NAMM sa mismong proseso ng pagsasanay. Maaari nitong bigyang-daan ang mga modelo na matuto ng mga diskarte sa pamamahala ng memorya nang katutubong, higit pang pagpapalawak ng haba ng mga window ng konteksto at pagpapalakas ng kahusayan sa mga domain.
“Nagsisimula pa lamang ang gawaing ito upang galugarin ang espasyo sa disenyo ng aming mga modelo ng memorya, na inaasahan naming maaaring mag-alok ng maraming bagong pagkakataon para isulong ang mga susunod na henerasyon ng mga transformer,”pagtatapos ng koponan.
Ang napatunayang kakayahan ng mga NAMM na sukatin ang pagganap, bawasan ang mga gastos, at iangkop sa mga modalidad ay nagtatakda ng bagong pamantayan para sa kahusayan ng malalaking modelo ng AI.