Inilabas ng DeepSeek AI ang DeepSeek-VL2, isang pamilya ng Vision-Language Models (VLM) na available na ngayon sa ilalim ng mga open-source na lisensya. Ipinakilala ng serye ang tatlong variant—Maliit, Maliit, at ang karaniwang VL2—na nagtatampok ng mga naka-activate na laki ng parameter na 1.0 bilyon, 2.8 bilyon, at 4.5 bilyon, ayon sa pagkakabanggit.
Naa-access ang mga modelo sa pamamagitan ng GitHub at Yakap Mukha. Nangangako silang isulong ang mga pangunahing aplikasyon ng AI, kabilang ang visual question answering (VQA), optical character recognition (OCR), at high-resolution na dokumento at pagtatasa ng tsart.
Ayon sa opisyal na dokumentasyon ng GitHub, “Ang DeepSeek-VL2 ay nagpapakita ng mga mahusay na kakayahan sa iba’t ibang gawain, kabilang ngunit hindi limitado sa visual na pagsagot sa tanong, pag-unawa sa dokumento/talahanayan/chart, at visual na saligan.”
Ang timing ng release na ito ay naglalagay ng DeepSeek AI sa direktang pakikipagkumpitensya sa mga pangunahing manlalaro tulad ng OpenAI at Google, na parehong nangingibabaw sa vision-language AI domain na may proprietary mga modelo tulad ng GPT-4V at Gemini-Exp
Ang pagbibigay-diin ng DeepSeek sa open-source na pakikipagtulungan, kasama ang mga advanced na teknikal na feature ng pamilyang VL2, ay naglalagay nito bilang isang libreng opsyon para sa mga mananaliksik.
Dynamic Tiling: Pagsulong ng High-Resolution Image Processing
Ang isa sa mga pinakakilalang pagsulong sa DeepSeek-VL2 ay ang dynamic na tiling vision encoding na diskarte nito, na binabago ng mga modelo kung paano pinoproseso ng mga modelo ang mataas na resolution na visual na data.
Hindi tulad ng tradisyonal na fixed-resolution na diskarte, hinahati ng dynamic na pag-tile ang mga larawan sa mas maliliit, flexible na tile na umaangkop sa iba’t ibang aspect ratio. Tinitiyak ng pamamaraang ito ang detalyadong pagkuha ng tampok habang pinapanatili ang kahusayan sa pag-compute.
Sa GitHub repository nito, inilalarawan ito ng DeepSeek bilang isang paraan para “mahusay na magproseso ng mga high-resolution na larawan na may iba’t ibang aspect ratio, na iniiwasan ang computational scaling na karaniwang nauugnay sa pagtaas ng mga resolution ng larawan.”
Ang kakayahang ito ay nagbibigay-daan sa DeepSeek-VL2 na maging mahusay sa mga application tulad ng visual grounding, kung saan ang mataas na katumpakan ay mahalaga para sa pagtukoy ng mga bagay sa mga kumplikadong larawan, at siksik na OCR mga gawain, na nangangailangan ng pagpoproseso ng teksto sa mga detalyadong dokumento o chart
Sa pamamagitan ng dynamic na pagsasaayos sa iba’t ibang mga resolution ng imahe at mga aspect ratio, nalalampasan ng mga modelo ang mga limitasyon ng mga static na pamamaraan ng pag-encode, na ginagawang angkop ang mga ito para sa mga use case na nangangailangan ng parehong flexibility. at katumpakan.
Mixture-of-Experts and Multi-Head Latent Attention for Efficiency
Ang mga nadagdag sa performance ng DeepSeek-VL2 ay higit pang sinusuportahan ng pagsasama nito ng balangkas ng Mixture-of-Experts (MoE) at mekanismo ng Multi-head Latent Attention (MLA)
Pili na ina-activate ng arkitektura ng MoE ang mga partikular na subset , o”mga eksperto,”sa loob ng modelo upang pangasiwaan ang mga gawain nang mas mahusay. Binabawasan ng disenyong ito ang computational overhead sa pamamagitan ng paggamit lamang ng mga kinakailangang parameter para sa bawat operasyon, isang feature na partikular na kapaki-pakinabang sa mga environment na pinaghihigpitan ng mapagkukunan.
Ang mekanismo ng MLA ay umaakma sa MoE framework sa pamamagitan ng pag-compress sa Key-Value cache sa latent. mga vector sa panahon ng hinuha. Pinaliit ng optimization na ito ang paggamit ng memory at pinapataas ang bilis ng pagproseso nang hindi sinasakripisyo ang katumpakan ng modelo.
Ayon sa teknikal na dokumentasyon, “Ang arkitektura ng MoE, na sinamahan ng MLA, ay nagbibigay-daan sa DeepSeek-VL2 na makamit ang mapagkumpitensya o mas mahusay na pagganap kaysa sa mga siksik na modelo na may mas kaunting mga naka-activate na parameter.”
Three-Stage Training Pipeline
Ang pagbuo ng DeepSeek-VL2 ay nagsasangkot ng isang mahigpit na tatlong yugto ng pipeline ng pagsasanay na idinisenyo upang i-optimize ang multimodal na kakayahan ng modelo Ang unang yugto ay nakatuon sa vision-language alignment, kung saan ang mga modelo ay sinanay upang isama ang mga visual na feature sa textual na impormasyon
Nakamit ito gamit ang mga dataset tulad ng ShareGPT4V, na nagbibigay ng mga nakapares na mga halimbawa ng teksto ng imahe. paunang pag-align Ang ikalawang yugto ay nagsasangkot ng vision-language pretraining, na nagsama ng magkakaibang hanay ng mga dataset, kabilang ang WIT, WikiHow, at multilinggwal na data ng OCR, upang mapahusay ang mga kakayahan sa pag-generalize ng modelo sa maraming domain
Sa wakas, ang ikatlong yugto ay binubuo ng pinangangasiwaang fine-tuning (SFT), kung saan ginamit ang mga dataset na partikular sa gawain upang pinuhin ang pagganap ng modelo sa. mga lugar tulad ng visual grounding, graphical user interface (GUI) comprehension, at dense captioning.
Ang mga yugto ng pagsasanay na ito ay nagbigay-daan sa DeepSeek-VL2 na bumuo ng solidong pundasyon para sa multimodal na pag-unawa habang pinapagana ang mga modelo na umangkop sa mga espesyal na gawain. Ang pagsasama ng mga multilinggwal na dataset ay higit na nagpahusay sa pagiging angkop ng mga modelo sa pandaigdigang pagsasaliksik at mga setting ng industriya.
Nauugnay: Tina-target ng Chinese DeepSeek R1-Lite-Preview Model ang Lead ng OpenAI sa Automated Reasoning
Mga Resulta sa Pag-benchmark
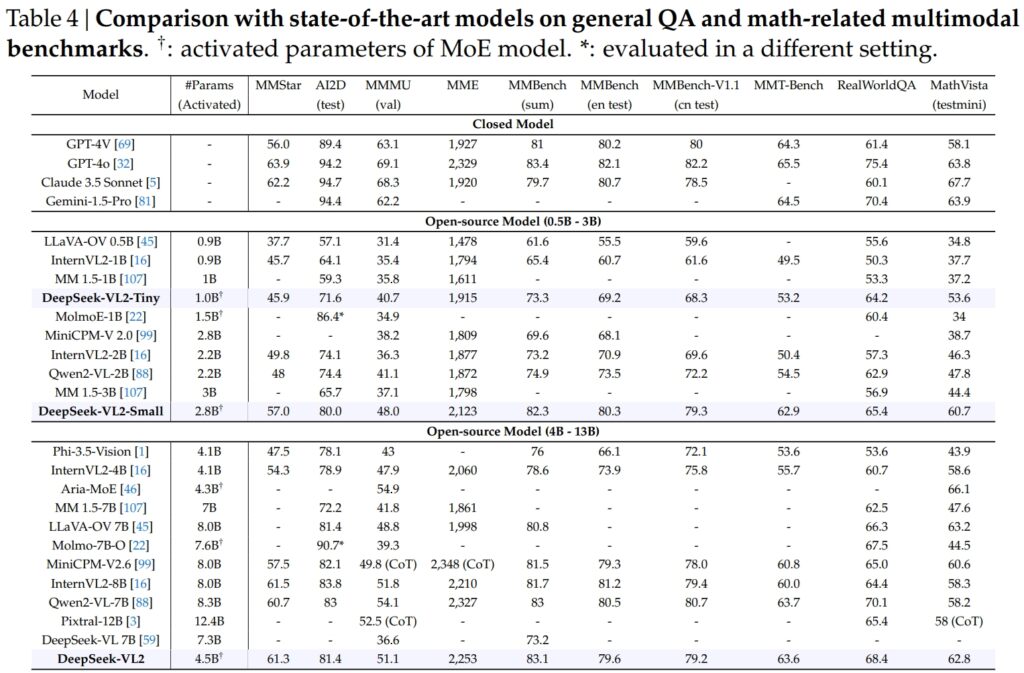
DeepSeek-VL2 na mga modelo, kabilang ang Tiny, Small, at standard na variant, mahusay sa mga kritikal na benchmark para sa pangkalahatang pagsagot sa tanong (QA) at mga gawaing multimodal na nauugnay sa matematika.
Ang DeepSeek-VL2-Small, kasama ang 2.8 bilyong na-activate na mga parameter nito, ay nakakuha ng MMStar score na 57.0 at nalampasan ang mga katulad na laki ng mga modelo tulad ng InternVL2-2B (49.8) at Qwen2-VL-2B (48.0). Malapit din nitong kalabanin ang mas malalaking modelo, gaya ng 4.1B InternVL2-4B (54.3) at ang 8.3B Qwen2-VL-7B (60.7), na nagpapakita ng kahusayan nito sa pakikipagkumpitensya.
Sa AI2D test para sa visual pangangatwiran, nakamit ng DeepSeek-VL2-Small ang markang 80.0, na nalampasan ang InternVL2-2B (74.1) at MM 1.5-3B (hindi iniulat). Kahit na laban sa mas malalaking kakumpitensya tulad ng InternVL2-4B (78.9) at MiniCPM-V2.6 (82.1), nagpakita ang DeepSeek-VL2 ng malalakas na resulta na may mas kaunting mga naka-activate na parameter.
 Pinagmulan: DeepSeek
Pinagmulan: DeepSeek
Ang punong barko Ang modelo ng DeepSeek-VL2 (4.5 bilyong naka-activate na mga parameter) ay naghatid ng mga pambihirang resulta, na nakakuha ng 61.3 sa MMStar at 81.4 sa AI2D. Nahigitan nito ang mga katunggali gaya ng Molmo-7B-O (7.6B activated parameters, 39.3) at MiniCPM-V2.6 (8.0B, 57.5), na higit pang nagpapatunay sa teknikal na kahusayan nito.
Excellence sa OCR-Mga Kaugnay na Benchmark
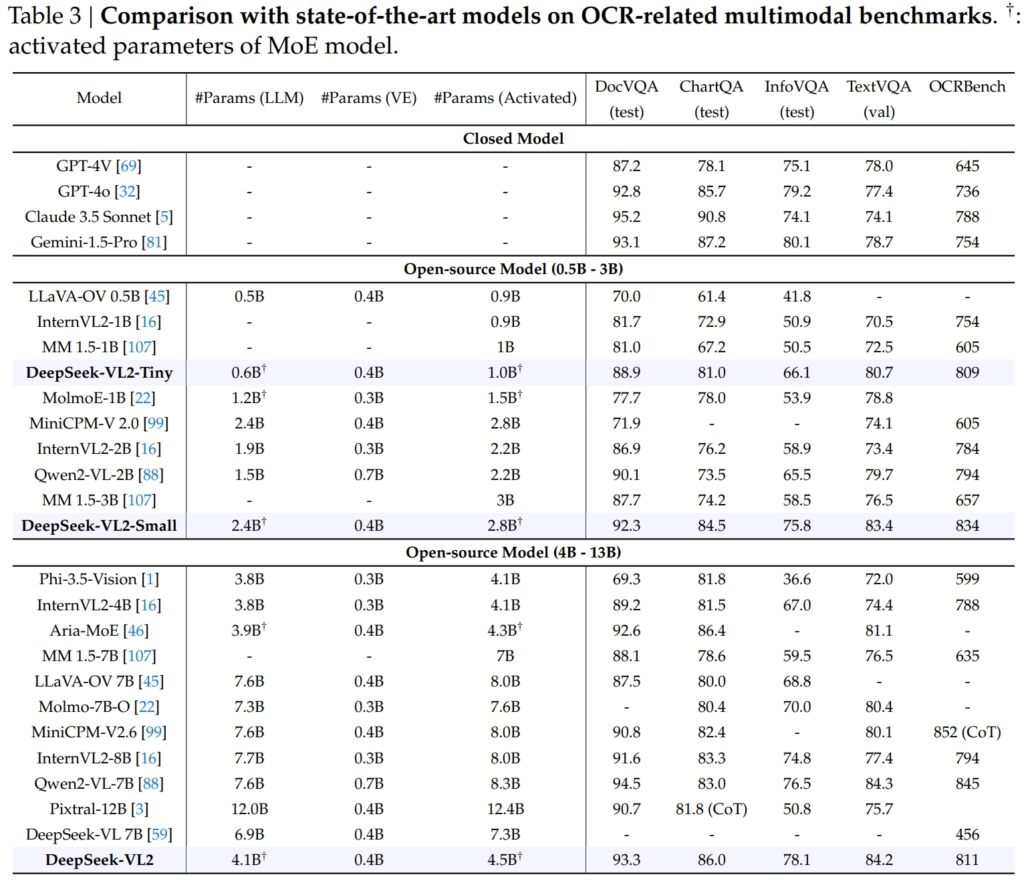
Ang mga kakayahan ng DeepSeek-VL2 ay kitang-kitang umaabot sa Mga gawaing nauugnay sa OCR (optical character recognition), isang mahalagang bahagi para sa pag-unawa sa dokumento at pagkuha ng teksto sa AI. Sa pagsusulit ng DocVQA, nakamit ng DeepSeek-VL2-Small ang isang kahanga-hangang 92.3% na katumpakan, na higit sa lahat ng iba pang open-source na modelo ng katulad na sukat, kabilang ang InternVL2-4B (89.2%) at MiniCPM-V2.6 (90.8%). Ang katumpakan nito ay nasa likod lamang ng mga saradong modelo tulad ng GPT-4o (92.8) at Claude 3.5 Sonnet (95.2).
Nanguna rin ang modelo ng DeepSeek-VL2 sa ChartQA test na may markang 86.0, na higit sa InternVL2-4B (81.5) at MiniCPM-V2.6 (82.4). Sinasalamin ng resultang ito ang advanced na kakayahan ng DeepSeek-VL2 na magproseso ng mga chart at kumuha ng mga insight mula sa kumplikadong visual na data.
 Pinagmulan: DeepSeek
Pinagmulan: DeepSeek
Sa OCRBench, isang lubos na mapagkumpitensya sukatan para sa fine-grained text recognition, DeepSeek-VL2 nakamit ang 811, outclassing ang 7.6B Qwen2-VL-7B (845) at MiniCPM-V2.6 (852 na may CoT), at itinatampok ang lakas nito sa mga siksik na gawain sa OCR.
Paghahambing Laban sa Mga Nangungunang Vision-Language Models
strong>
Kapag inilagay sa tabi ng mga lider ng industriya tulad ng GPT-4V ng OpenAI at Gemini-1.5-Pro ng Google, Ang mga modelo ng DeepSeek-VL2 ay nag-aalok ng nakakahimok na balanse ng pagganap at kahusayan. Halimbawa, nakakuha ng 87.2 ang GPT-4V sa DocVQA, na nauuna lamang nang bahagya sa DeepSeek-VL2 (93.3), sa kabila ng pagpapatakbo ng huli sa ilalim ng open-source na framework na may mas kaunting mga naka-activate na parameter.
Sa TextVQA, DeepSeek-VL2-Small na nakamit ang 83.4, na higit na nakahihigit sa mga katulad na open-source na modelo tulad ng InternVL2-2B (73.4) at MiniCPM-V2.0 (74.1). Kahit na ang mas malaking MiniCPM-V2.6 (8.0B) ay umabot lamang sa 80.4, higit na binibigyang-diin ang scalability at kahusayan ng arkitektura ng DeepSeek-VL2.
Para sa ChartQA, ang marka ng DeepSeek-VL2 na 86.0 ay lumampas sa Pixtral-12B (81.8) at InternVL2-8B (83.3), na nagpapakita ng kakayahang maging mahusay sa mga espesyal na gawain na nangangailangan ng tumpak na visual-textual na pag-unawa.
Kaugnay: Mistral AI Debuts Pixtral 12B para sa Pagproseso ng Teksto at Imahe
Pagpapalawak ng Mga Application: Mula sa Grounded Mga Pag-uusap sa Visual Storytelling
Isang kapansin-pansing tampok ng mga modelo ng DeepSeek-VL2 ay ang kanilang kakayahang magsagawa ng mga grounded na pag-uusap, kung saan ang maaaring matukoy ng modelo ang mga bagay sa mga imahe at isama ang mga ito sa mga talakayan sa konteksto.
Halimbawa, sa pamamagitan ng paggamit ng espesyal na token, maaaring magbigay ang modelo ng mga detalyeng partikular sa bagay, gaya ng lokasyon at paglalarawan, upang sagutin ang mga query tungkol sa mga larawan. Nagbubukas ito ng mga posibilidad para sa mga aplikasyon sa robotics, augmented reality, at digital assistant, kung saan kinakailangan ang tumpak na visual na pangangatwiran.
Ang isa pang bahagi ng aplikasyon ay visual storytelling. Ang DeepSeek-VL2 ay maaaring makabuo ng magkakaugnay na mga salaysay batay sa pagkakasunud-sunod ng mga larawan, na pinagsasama ang advanced na visual recognition at mga kakayahan sa wika.
Mahalaga ito lalo na sa mga domain tulad ng edukasyon, media, at entertainment, kung saan priyoridad ang paggawa ng dynamic na content. Ang mga modelo ay gumagamit ng malakas na multimodal na pag-unawa upang gumawa ng mga detalyado at naaangkop sa konteksto na mga kuwento, na isinasama ang mga visual na elemento tulad ng mga landmark at text sa salaysay nang walang putol.
Ang kakayahan ng mga modelo sa visual na saligan ay pare-parehong malakas. Sa mga pagsubok na kinasasangkutan ng mga kumplikadong larawan, ipinakita ng DeepSeek-VL2 ang kakayahang tumpak na mahanap at ilarawan ang mga bagay batay sa mga mapaglarawang senyas.
Halimbawa, kapag hiniling na tukuyin ang isang”kotse na nakaparada sa kaliwang bahagi ng kalye,”matutukoy ng modelo ang eksaktong bagay sa larawan at makabuo ng mga coordinate ng bounding box upang ilarawan ang tugon nito. lubos itong naaangkop para sa mga autonomous na system at pagsubaybay, kung saan kritikal ang detalyadong visual na pagsusuri.
Open-Source Accessibility at Scalability
DeepSeek AI’s Ang desisyon na ilabas ang DeepSeek-VL2 bilang isang open-source ay lubos na naiiba sa likas na katangian ng mga kakumpitensya tulad ng OpenAI’s GPT-4V at Google’s Gemini-Exp, na mga closed system na idinisenyo para sa limitadong pampublikong pag-access.
Ayon sa teknikal na dokumentasyon, “Sa pamamagitan ng paggawa ng aming mga pre-trained na modelo at code na magagamit sa publiko, nilalayon naming pabilisin ang pag-unlad sa vision-language modelling at i-promote ang collaborative pagbabago sa buong komunidad ng pananaliksik.”
Ang scalability ng DeepSeek-VL2 ay higit na nagpapahusay sa kanilang apela. Ang mga modelo ay na-optimize para sa pag-deploy sa malawak na hanay ng mga configuration ng hardware, mula sa mga iisang GPU na may 10GB memory hanggang sa mga multi-GPU setup na may kakayahang pangasiwaan ang malakihang workload.
Ang flexibility na ito ay tumitiyak na ang DeepSeek-VL2 ay magagamit ng mga organisasyon sa lahat ng laki, mula sa mga startup hanggang sa malalaking negosyo, nang hindi nangangailangan ng espesyal na imprastraktura.
Mga Inobasyon sa Data at Pagsasanay
Ang isang pangunahing salik sa likod ng tagumpay ng DeepSeek-VL2 ay ang malawak at magkakaibang data ng pagsasanay nito. Ang yugto ng pretraining ay nagsama ng mga dataset gaya ng WIT, WikiHow, at OBELICS, na nagbigay ng halo ng mga interleaved image-text pares para sa generalization.
Ang karagdagang data para sa mga partikular na gawain, tulad ng OCR at visual na pagsagot sa tanong, ay nagmula sa mga mapagkukunan tulad ng LaTeX OCR at PubTabNet, na tinitiyak na ang mga modelo ay maaaring pangasiwaan ang mga pangkalahatan at espesyal na gawain na may mataas na katumpakan.
Ang pagsasama ng mga multilinggwal na dataset ay sumasalamin din sa layunin ng DeepSeek AI ng global applicability. Ang mga dataset sa wikang Chinese tulad ng Wanjuan ay isinama sa mga English na dataset para matiyak na ang mga modelo ay maaaring gumana nang epektibo sa mga multilingual na kapaligiran.
Pinapahusay ng diskarteng ito ang kakayahang magamit ng DeepSeek-VL2 sa mga rehiyon kung saan nangingibabaw ang data na hindi English, na nagpapalawak ng potensyal na base ng user nito.
Ang pinangangasiwaang bahagi ng fine-tuning ay higit na nagpapino sa mga modelo. mga kakayahan sa pamamagitan ng pagtutok sa mga partikular na gawain tulad ng pag-unawa sa GUI at pagsusuri ng tsart. Sa pamamagitan ng pagsasama-sama ng mga in-house na dataset na may mataas na kalidad na open-source na mapagkukunan, nakamit ng DeepSeek-VL2 ang makabagong pagganap sa ilang mga benchmark, na nagpapatunay sa pagiging epektibo ng pamamaraan ng pagsasanay nito.
Maingat na curation ng DeepSeek AI ng data at makabagong pipeline ng pagsasanay ay nagbigay-daan sa mga modelo ng VL2 na maging mahusay sa malawak na hanay ng mga gawain habang pinapanatili ang kahusayan at scalability. Ang mga salik na ito ay ginagawa silang isang mahalagang karagdagan sa larangan ng multimodal AI.
Ang kakayahan ng mga modelo na pangasiwaan ang mga kumplikadong gawain sa pagpoproseso ng imahe, tulad ng visual na saligan at siksik na OCR, ay ginagawa silang perpekto para sa mga industriya tulad ng logistik at seguridad. Sa logistik, maaari nilang i-automate ang pagsubaybay sa imbentaryo sa pamamagitan ng pagsusuri ng mga larawan ng stock ng warehouse, pagtukoy ng mga item, at pagsasama ng mga natuklasan sa mga sistema ng pamamahala ng imbentaryo.
Sa domain ng seguridad, maaaring tumulong ang DeepSeek-VL2 sa pagsubaybay sa pamamagitan ng pagtukoy ng mga bagay o indibidwal sa real time, batay sa mga mapaglarawang query, at pagbibigay ng detalyadong impormasyon sa konteksto sa mga operator.
DeepSeek-Nag-aalok din ang grounded na kakayahan sa pag-uusap ng VL2 ng mga posibilidad sa robotics at augmented reality. Halimbawa, ang isang robot na nilagyan ng modelong ito ay maaaring bigyang kahulugan ang kapaligiran nito nang biswal, tumugon sa mga tanong ng tao tungkol sa mga partikular na bagay, at magsagawa ng mga aksyon batay sa pag-unawa nito sa visual input.
Katulad nito, maaaring gamitin ng mga augmented reality na device ang visual grounding at pagkukuwento ng mga feature ng modelo upang magbigay ng mga interactive at nakaka-engganyong karanasan, gaya ng mga guided tour o contextual overlay sa mga real-time na kapaligiran.
Mga Hamon at Mga Prospect sa Hinaharap
Sa kabila ng maraming lakas nito, nahaharap ang DeepSeek-VL2 ng ilang hamon. Ang isang pangunahing limitasyon ay ang laki ng window ng konteksto nito, na kasalukuyang naghihigpit sa bilang ng mga larawang maaaring iproseso sa loob ng iisang pakikipag-ugnayan.
Ang pagpapalawak sa window ng konteksto na ito sa mga pag-ulit sa hinaharap ay magbibigay-daan sa mas mayaman, maraming-imahe na pakikipag-ugnayan at mapahusay ang utility ng modelo sa mga gawaing nangangailangan ng mas malawak na pang-unawa sa konteksto.
Ang isa pang hamon ay nakasalalay sa paghawak ng out-of-domain o mababang kalidad na visual input, gaya ng malabong mga larawan o mga bagay na wala sa data ng pagsasanay nito. Bagama’t ang DeepSeek-VL2 ay nagpakita ng mga kahanga-hangang kakayahan sa generalization, ang pagpapabuti ng katatagan laban sa mga naturang input ay higit na magpapalaki sa pagiging angkop nito sa mga totoong sitwasyon.
Sa hinaharap, plano ng DeepSeek AI na palakasin ang mga kakayahan sa pangangatwiran ng mga modelo nito, na nagbibigay-daan sa kanila na pangasiwaan ang lalong kumplikadong mga multimodal na gawain. Sa pamamagitan ng pagsasama ng mga pinahusay na pipeline ng pagsasanay at pagpapalawak ng mga dataset para masakop ang mas magkakaibang mga sitwasyon, ang mga hinaharap na bersyon ng DeepSeek-VL2 ay maaaring magtakda ng mga bagong benchmark para sa vision-language AI performance.