Hindi ito madalas, ngunit magkakaroon ng mga sitwasyon kung saan kailangan mong mag-extract ng mga larawan mula sa isang PDF na dokumento. Halimbawa, maaaring gumagawa ka ng isang presentasyon at kailangan mo ng mga larawan mula sa isang research paper. Maaaring isa kang graphic designer at kailangan mong muling gumamit ng mga logo o larawan mula sa PDF brochure ng kliyente. O marahil isa kang mag-aaral na gumagawa ng mga custom na tala at nangangailangan ng mga larawan mula sa textbook.
Anuman ang sitwasyon/situasyon, ang pag-save ng lahat ng larawan mula sa isang PDF na dokumento ay isang simpleng gawain. Sa tutorial na ito, ipapakita ko sa iyo kung paano mag-extract ng mga larawan mula sa isang PDF na dokumento gamit ang pdfcpu, isang libre at open-source na tool. Magsimula tayo.
Mga Hakbang sa Pag-extract ng Mga Larawan mula sa PDF
Dahil walang native na opsyon ang Windows, gagamit kami ng libre at open-source na PDF tool na tinatawag na pdfcpu. Ito ay isang makapangyarihang command-line tool para sa pagpoproseso ng PDF. Ganito.
Hakbang 1: I-download ang pdfcpu
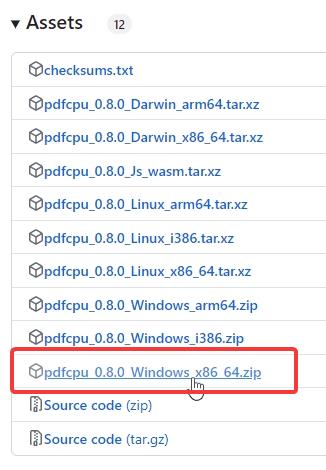
Una, pumunta sa opisyal na pahina ng GitHub ng pdfcpu. Mag-scroll pababa sa seksyong Mga Asset at i-download ang pinakabagong “Windows_x86_64.zip”na file para sa mga 64-bit na Windows system.
Hakbang 2: I-extract ang na-download na pdfcpu file
Hanapin ang na-download na zip file sa folder ng Mga Download, i-right-click dito, at piliin ang “I-extract Lahat.”
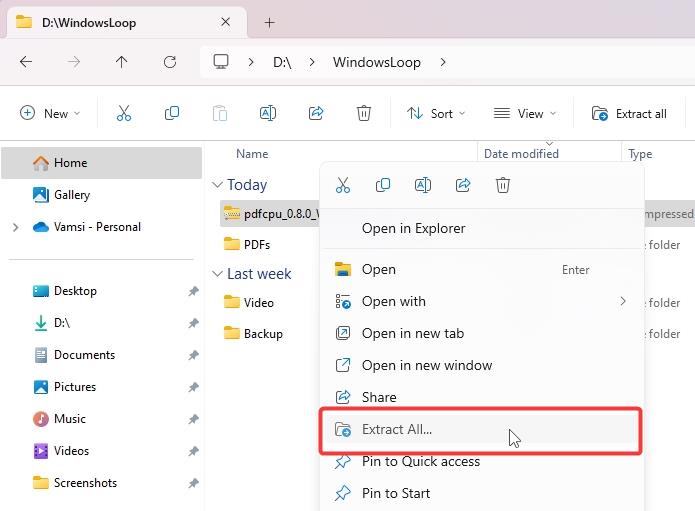
Kapag na-prompt, i-click ang button na “I-extract ang zip sa isang hiwalay na folder sa parehong direktoryo.
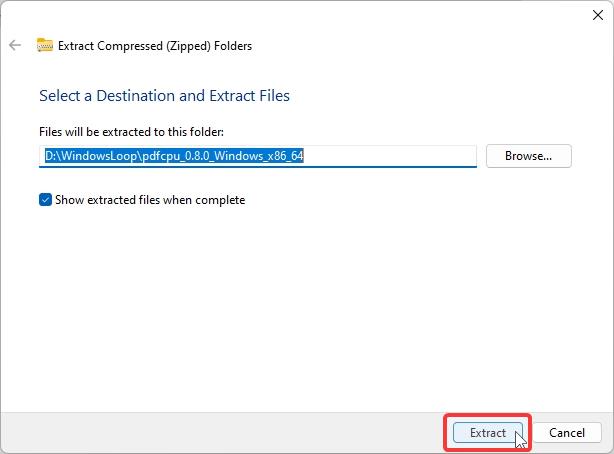
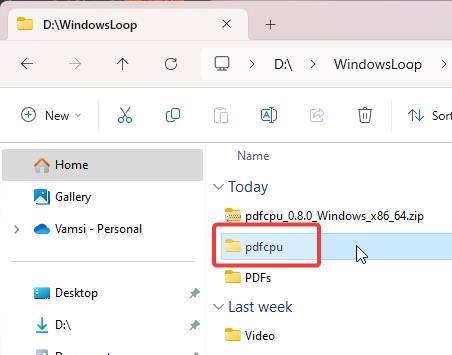
(Opsyonal) Para sa kadalian ng paggamit, palitan ang pangalan ng na-extract na folder sa “pdfcpu.”Ito ay hindi kinakailangang hakbang ngunit ginagawang madali ang pag-navigate sa Command Prompt.
Hakbang 3: Buksan ang Command Prompt
Pindutin ang Start button, hanapin ang “Command Prompt ,”at i-click ang “Buksan.”
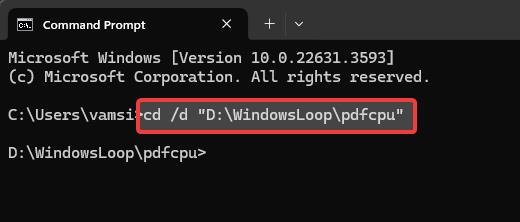
Hakbang 4: Mag-navigate sa pdfcpu directory sa Command Prompt
Sa Command Prompt, patakbuhin ang sumusunod na command to go sa pdfcpu directory. Tiyaking palitan ang dummy path ng aktwal na path ng folder. Ginagawa nitong madali ang pagpapatupad ng command sa susunod na hakbang.
cd/d “C:\path\to\pdfcpu\folder”
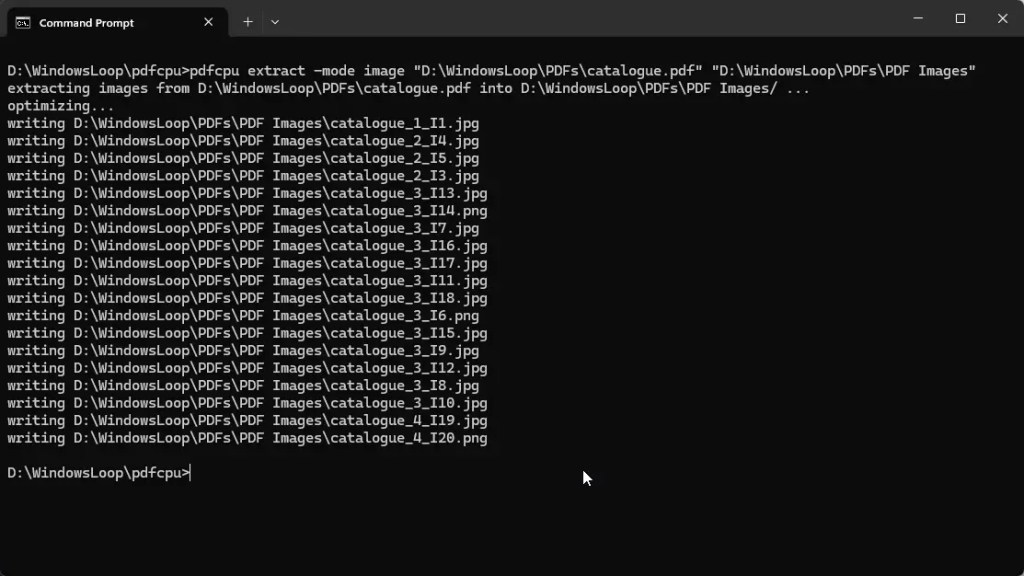
Hakbang 5: Ipatupad pdfcpu command para mag-extract ng mga larawan mula sa PDF
Susunod, patakbuhin ang sumusunod na command, palitan ang dummy PDF path at dummy output directory path ng mga aktwal na path.
pdfcpu extract-mode image “C:\path\to\file.pdf”“C:\path\to\output\folder”
Halimbawa, pagkatapos palitan ang parehong dummy path, magiging ganito ang command:
pdfcpu extract-mode image”D: \WindowsLoop\PDFs\catalogue.pdf”
“D:\WindowsLoop\PDFs\PDF Images”
Sa sandaling patakbuhin mo ang command , kukunin ng pdfcpu ang mga larawan mula sa ibinigay na PDF file at ise-save ang mga ito sa direktoryo ng output.
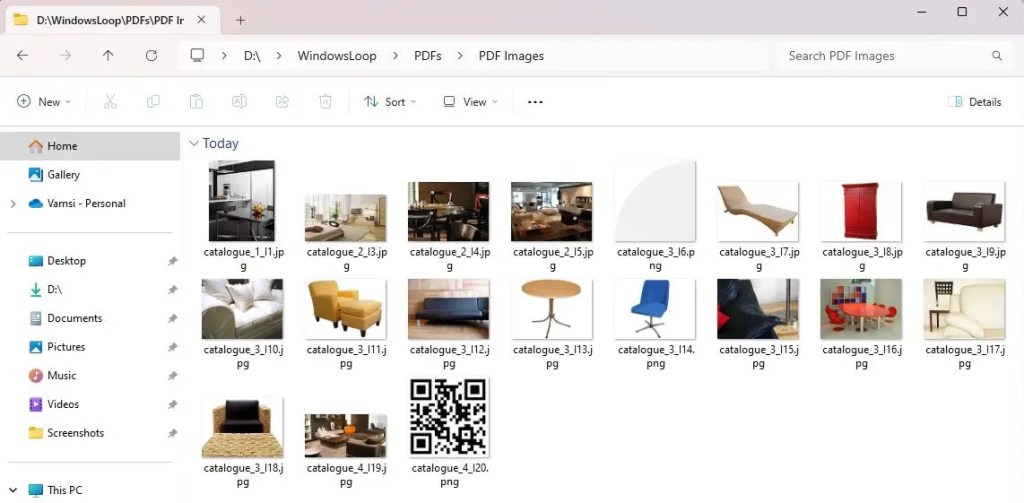
Hakbang 6: I-verify ang mga kinuhang larawan
Upang i-verify ang na-extract mga imahe, buksan ang File Explorer (pindutin ang Start + E) at mag-navigate sa direktoryo ng output. Dapat ay nakuha nito ang lahat ng larawan mula sa PDF file.
Mga Hakbang sa Pag-troubleshoot
Narito ang ilang karaniwang error na maaari mong maranasan habang ginagamit ang pdfcpu tool at kung paano ayusin ang mga ito.
Error:’pdfcpu’ay hindi kinikilala bilang isang panloob o panlabas na command, operable program, o batch file
Kung nakikita mo ang error na ito, tiyaking ang path ng direktoryo kung saan na-extract mo ang”pdfcpu”ay tama at naglalaman ng”pdfcpu.exe”na file. Upang i-verify, buksan ang File Explorer at mag-navigate sa folder. Dapat mong makita ang pdfcpu.exe file sa loob nito.
Error: Hindi mahanap ng system ang path na tinukoy
Kung nakita mo ang error na”Hindi mahanap ng system ang tinukoy na path ,”karaniwan itong nangangahulugan na may problema sa mga path para sa PDF file o sa output directory. Upang ayusin ito, sundin ang mga hakbang na ito:
Una, tiyaking tama ang path patungo sa iyong PDF file at iyon umiiral ang file doon. Susunod, tingnan kung tama ang path para sa direktoryo ng output at mayroon na ang direktoryo, dahil hindi ito gagawa ng”pdfcpu”para sa iyo
Mga Naka-encrypt na PDF
Kung ang PDF dokumento kung saan sinusubukan mong kunin ang mga imahe ay naka-encrypt, kailangan mo munang i-decrypt ito. Kung susubukan mong mag-extract ng mga larawan nang hindi nagde-decrypt, makikita mo ang mensahe ng error na “pdfcpu: mangyaring ibigay ang tamang password.”Upang i-decrypt ang isang PDF file, patakbuhin ang sumusunod na command, palitan ang
pdfcpu decrypt-upw
Pagkatapos ng pag-decryption, sundin ang mga hakbang na inilarawan sa tutorial upang mag-extract ng mga larawan.
Hindi magawang mag-extract ng mga larawan ang pdfcpu
Mayroong ilang sitwasyon kung saan hindi na-extract ng pdfcpu ang mga larawan mula sa isang PDF file. (hal., SVG) o sa mga espesyal na format tulad ng JBIG2 o JPEG2000, na maaaring hindi suportado ng mga PDF tool gaya ng pdfcpu.Mga naka-embed na object: Kung ang mga larawan ay naka-embed sa iba pang mga bagay, tulad ng interactive na nilalaman, multimedia content, form XObjects, inline na mga larawan, atbp., pdfcpu ay maaaring balewalain ang mga ito o i-extract ang mga ito nang hindi tama.
Wrapping Up — Pag-save ng Mga Larawan mula sa PDF
Tulad ng nakikita mo, ang pag-extract at pag-save ng mga larawan mula sa mga PDF file ay mas madali kaysa sa iyong iniisip, salamat sa pdfcpu. Habang ginagamit ang tool, tiyaking tama ang mga path at hindi naka-encrypt ang PDF file. Kung makatagpo ka ng mga error, tingnan ang seksyon ng pag-troubleshoot sa itaas at makakatulong ito sa iyong ayusin ang mga karaniwang error at sagutin ang mga karaniwang problema.
Kung mayroon kang anumang mga tanong o kailangan ng tulong, magkomento sa ibaba. Sasagot ako.
Mga kaugnay na tutorial:

