Google DeepMind ได้เปิดตัว FACTS Grounding ซึ่งเป็นเกณฑ์มาตรฐานใหม่ที่ออกแบบมาเพื่อทดสอบโมเดลภาษาขนาดใหญ่ (LLM) เกี่ยวกับความสามารถในการสร้างการตอบสนองตามข้อเท็จจริงที่แม่นยำตามเอกสาร
เกณฑ์มาตรฐาน โฮสต์บน Kaggle มีเป้าหมายที่จะจัดการกับหนึ่งในความท้าทายเร่งด่วนที่สุดใน ปัญญาประดิษฐ์: ตรวจสอบให้แน่ใจว่าเอาต์พุตของ AI นั้นยึดตามข้อมูลที่มอบให้ แทนที่จะอาศัยความรู้ภายนอกหรือทำให้เกิดอาการประสาทหลอน ซึ่งเป็นข้อมูลที่น่าเชื่อถือแต่ไม่ถูกต้อง
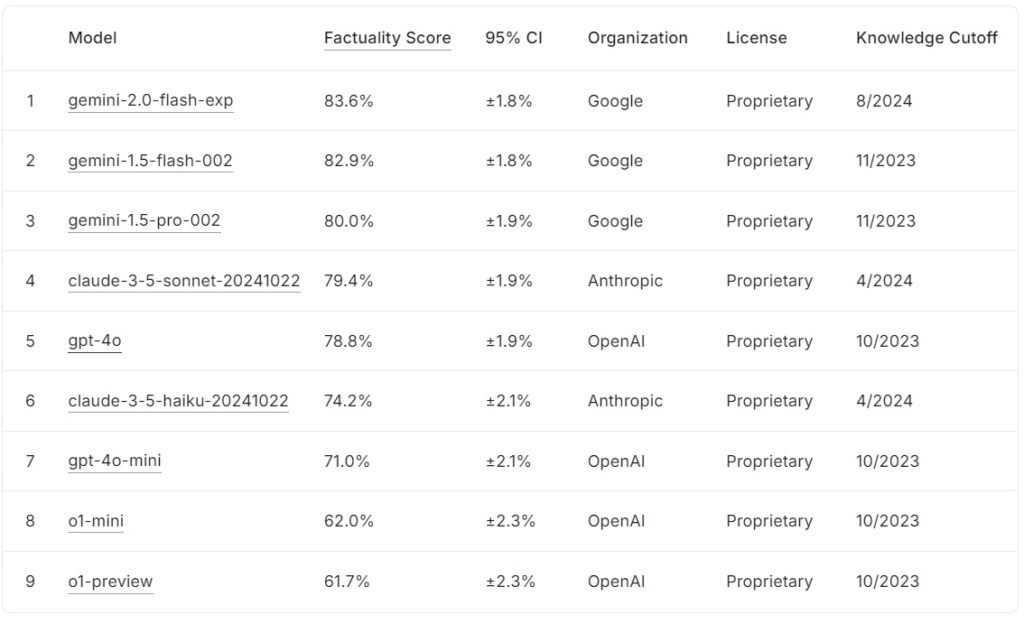
บอร์ดผู้นำ FACTS Grounding ในปัจจุบันจัดอันดับโมเดลภาษาขนาดใหญ่ตามคะแนนข้อเท็จจริง โดย Google gemini-2.0-flash-exp ชั้นนำที่ 83.6% ตามมาอย่างใกล้ชิดด้วย gemini-1.5-flash-002 ที่ 82.9% และ gemini-1.5-pro-002 ที่ 80.0%
claude-3.5-sonnet-20241022 ของมานุษยวิทยา อันดับที่สี่ด้วย 79.4% ในขณะที่ OpenAI gpt-4o ทำได้ 78.8% อยู่ในอันดับที่ 5 อันดับที่ต่ำกว่า ได้แก่ claude-3.5-haiku-20241022 ของ Anthropic ได้คะแนน 74.2% ตามด้วย gpt-4o-mini ที่ 71.0%
โมเดลขนาดเล็กของ OpenAI o1-mini และ o1-preview ปัดเศษบอร์ดผู้นำที่ 62.0% และ 61.7% ตามลำดับ
 ที่มา: คากเกิล
ที่มา: คากเกิล
FACTS Grounding มีความโดดเด่นโดยกำหนดให้มีการตอบกลับแบบยาวที่สังเคราะห์เอกสารอินพุตโดยละเอียด ทำให้เป็นหนึ่งใน เกณฑ์มาตรฐานที่เข้มงวดที่สุดสำหรับข้อเท็จจริงของ AI จนถึงปัจจุบัน
FACTS Grounding แสดงถึงการพัฒนาที่สำคัญสำหรับอุตสาหกรรม AI โดยเฉพาะอย่างยิ่งในการใช้งานที่จำเป็นต้องมีความน่าเชื่อถือและความแม่นยำ ด้วยการประเมิน LLM ในโดเมนต่างๆ เช่น การแพทย์ กฎหมาย การเงิน การค้าปลีก และเทคโนโลยี มาตรฐานดังกล่าวจะกำหนดขั้นตอนสำหรับการปรับปรุงความน่าเชื่อถือของ AI ในสถานการณ์จริง
ตามรายงานของทีมวิจัยของ DeepMind “เกณฑ์มาตรฐานวัดความสามารถของ LLM ในการสร้างการตอบสนองโดยมีพื้นฐานเฉพาะในบริบทที่ให้มา…แม้ว่าบริบทจะขัดแย้งกับความรู้ก่อนการฝึกอบรมก็ตาม”
ชุดข้อมูลสำหรับความซับซ้อนในโลกแห่งความเป็นจริง
FACTS Grounding ประกอบด้วยตัวอย่าง 1,719 ตัวอย่าง เรียบเรียงโดยผู้อธิบายประกอบที่เป็นมนุษย์เพื่อให้แน่ใจว่าตัวอย่างเหล่านี้มีความเกี่ยวข้องและหลากหลาย ดึงมาจากเอกสารที่มีรายละเอียดซึ่งมีมากถึง 32,000 โทเค็น ซึ่งเทียบเท่ากับคำประมาณ 20,000 คำ
แต่ละงานท้าทาย LLM ให้ดำเนินการสรุป การสร้างคำถามและคำตอบ หรือการเขียนเนื้อหาใหม่ โดยมีคำแนะนำที่เข้มงวดในการอ้างอิงเฉพาะข้อมูลที่ให้ไว้ เกณฑ์มาตรฐานหลีกเลี่ยงงานที่ต้องใช้ความคิดสร้างสรรค์ การใช้เหตุผลทางคณิตศาสตร์ หรือการตีความของผู้เชี่ยวชาญ โดยมุ่งเน้นไปที่การทดสอบความสามารถของแบบจำลองในการสังเคราะห์และสื่อสารข้อมูลที่ซับซ้อนแทน
เพื่อรักษาความโปร่งใสและป้องกันการใส่ข้อมูลมากเกินไป DeepMind ได้แบ่งชุดข้อมูลออกเป็นสองส่วน ได้แก่ ตัวอย่างสาธารณะ 860 ตัวอย่างสำหรับใช้ภายนอก และตัวอย่างส่วนตัว 859 ตัวอย่างที่สงวนไว้สำหรับการประเมินบอร์ดผู้นำ
โครงสร้างแบบคู่นี้ปกป้องความสมบูรณ์ของเกณฑ์มาตรฐาน ในขณะเดียวกันก็สนับสนุนการทำงานร่วมกันจากนักพัฒนา AI ทั่วโลก “เราประเมินผู้ประเมินอัตโนมัติของเราอย่างเข้มงวดโดยใช้ข้อมูลการทดสอบที่เก็บไว้เพื่อตรวจสอบประสิทธิภาพในการทำงานของเรา” ทีมวิจัยตั้งข้อสังเกต โดยเน้นการออกแบบที่ระมัดระวังซึ่งเป็นรากฐานของ FACTS Grounding
ตัดสินความแม่นยำโดยผู้เชี่ยวชาญ โมเดล AI
FACTS Grounding แตกต่างจากการวัดประสิทธิภาพทั่วไปตรงที่ใช้กระบวนการตรวจสอบโดยผู้ทรงคุณวุฒิที่เกี่ยวข้องกับ LLM ขั้นสูง 3 รายการ ได้แก่ Gemini 1.5 Pro GPT-4o และ Claude 3.5 Sonnet โมเดลเหล่านี้ทำหน้าที่เป็นผู้ตัดสิน โดยให้คะแนนคำตอบตามเกณฑ์สำคัญ 2 ประการ: สิทธิ์และความถูกต้องของข้อเท็จจริง จากนั้นผู้ที่มีคุณสมบัติจะได้รับการประเมินตามพื้นฐานในแหล่งข้อมูล โดยมีคะแนนรวมในแบบจำลองทั้งสามเพื่อลดอคติ
นักวิจัยของ DeepMind เน้นย้ำถึงความสำคัญของสิ่งนี้ การประเมินแบบหลายชั้น โดยระบุว่า “ตัวชี้วัดที่มุ่งเน้นไปที่การประเมินความเป็นจริงของข้อความที่สร้างขึ้น…สามารถหลีกเลี่ยงได้โดยการเพิกเฉยต่อเจตนาเบื้องหลังคำขอของผู้ใช้ ด้วยการให้คำตอบที่สั้นลงซึ่งหลีกเลี่ยงการถ่ายทอดข้อมูลที่ครอบคลุม…จึงเป็นไปได้ที่จะได้รับคะแนนตามข้อเท็จจริงที่สูงโดยไม่ได้ให้คำตอบที่เป็นประโยชน์”
การใช้เทมเพลตการให้คะแนนหลายรายการ รวมถึงแนวทางระดับสแปนและ JSON ยังรับประกันความสอดคล้องกับวิจารณญาณของมนุษย์และความสามารถในการปรับตัวเข้ากับงานที่หลากหลาย
การจัดการกับความท้าทายของภาพหลอนของ AI
ภาพหลอนของ AI เป็นหนึ่งในอุปสรรคที่สำคัญที่สุดของ การใช้ LLM อย่างกว้างขวางในสาขาที่สำคัญ ข้อผิดพลาดเหล่านี้ซึ่งแบบจำลองสร้างผลลัพธ์ที่ดูน่าเชื่อถือแต่ไม่ถูกต้องตามข้อเท็จจริง ก่อให้เกิดความเสี่ยงร้ายแรงในโดเมนต่างๆ เช่น การดูแลสุขภาพ การวิเคราะห์ทางกฎหมาย และการรายงานทางการเงิน
การต่อสายดินระบุข้อเท็จจริงโดยตรง ปัญหานี้โดยการบังคับใช้การปฏิบัติตามข้อมูลอินพุตที่ให้มาอย่างเข้มงวด วิธีการนี้ไม่เพียงแต่ประเมินความสามารถของโมเดลในการหลีกเลี่ยงการแนะนำสิ่งที่เป็นเท็จ แต่ยังช่วยให้แน่ใจว่าเอาต์พุตยังคงสอดคล้องกับข้อมูลของผู้ใช้อีกด้วย ความตั้งใจ
ตรงกันข้ามกับเกณฑ์มาตรฐานอย่าง SimpleQA ของ OpenAI ซึ่งวัดความเป็นจริงในการดึงข้อมูลการฝึกอบรม FACTS Grounding จะทดสอบว่าโมเดลสังเคราะห์ข้อมูลใหม่ได้ดีเพียงใด
รายงานการวิจัยเน้นย้ำความแตกต่างนี้: “การรับรองความถูกต้องของข้อเท็จจริงในขณะที่สร้างคำตอบ LLM ถือเป็นเรื่องท้าทาย ความท้าทายหลักในข้อเท็จจริงของ LLM คือการสร้างแบบจำลอง (เช่น สถาปัตยกรรม การฝึกอบรม และการอนุมาน) และการวัดผล (เช่น วิธีการประเมิน ข้อมูล และตัวชี้วัด)”
ความท้าทายทางเทคนิคและการออกแบบเกณฑ์มาตรฐาน
ความซับซ้อนของอินพุตแบบยาวทำให้เกิดความท้าทายทางเทคนิคที่ไม่เหมือนใคร โดยเฉพาะอย่างยิ่งในการออกแบบวิธีการประเมินอัตโนมัติที่สามารถประเมินการตอบสนองดังกล่าวได้อย่างแม่นยำ
ข้อเท็จจริง ในกระบวนการที่ต้องใช้คอมพิวเตอร์อย่างเข้มข้นเพื่อตรวจสอบการตอบสนอง โดยใช้เกณฑ์ที่เข้มงวดเพื่อรับรองความน่าเชื่อถือ การรวมแบบจำลองการตัดสินหลายแบบช่วยลดอคติที่อาจเกิดขึ้นและเสริมความแข็งแกร่งให้กับกรอบการประเมินโดยรวม
ทีมวิจัยเน้นย้ำถึงความสำคัญของการตัดสิทธิ์คำตอบที่คลุมเครือหรือไม่เกี่ยวข้อง โดยสังเกตว่า “การตัดสิทธิ์คำตอบที่ไม่มีคุณสมบัติจะนำไปสู่การลดลง…เนื่องจากคำตอบเหล่านี้ถือว่าไม่ถูกต้อง”
การบังคับใช้ความเกี่ยวข้องที่เข้มงวดนี้ทำให้แน่ใจได้ว่าโมเดลจะไม่ได้รับรางวัลจากการหลีกเลี่ยงเจตนารมณ์ของงาน
สนับสนุนการทำงานร่วมกันด้วยความโปร่งใส
การตัดสินใจของ DeepMind ในการโฮสต์ FACTS Grounding บน Kaggle สะท้อนให้เห็นถึงความมุ่งมั่นของบริษัทในการส่งเสริมความร่วมมือในอุตสาหกรรม AI ด้วยการทำให้ส่วนสาธารณะของชุดข้อมูลสามารถเข้าถึงได้ โครงการนี้จึงขอเชิญชวนนักวิจัยและนักพัฒนา AI ให้ประเมินแบบจำลองของตนกับมาตรฐานที่แข็งแกร่ง และมีส่วนช่วยในการพัฒนาเกณฑ์มาตรฐานข้อเท็จจริงที่ก้าวหน้า
แนวทางนี้สอดคล้องกับเป้าหมายที่กว้างขึ้นในด้านความโปร่งใสและความก้าวหน้าร่วมกันใน AI เพื่อให้มั่นใจว่าการปรับปรุงด้านความแม่นยำและพื้นฐานไม่ได้จำกัดอยู่เพียงองค์กรเดียว
ความแตกต่างจากองค์กรอื่น เกณฑ์มาตรฐาน
ข้อเท็จจริง การต่อสายดินสร้างความแตกต่างจากเกณฑ์มาตรฐานอื่นๆ โดยการมุ่งเน้นไปที่การต่อสายดินในอินพุตที่เพิ่งเปิดตัว แทนที่จะเป็นความรู้ที่ได้รับการฝึกอบรมล่วงหน้า
ในขณะที่เกณฑ์มาตรฐาน เช่น SimpleQA ของ OpenAI ประเมินว่าแบบจำลองดึงข้อมูลและใช้ข้อมูลจากคลังข้อมูลการฝึกอบรมได้ดีเพียงใด FACTS Grounding จะประเมินแบบจำลองเกี่ยวกับความสามารถในการสังเคราะห์และแสดงการตอบสนองโดยอิงจากข้อมูลที่ให้มาโดยเฉพาะ
ความแตกต่างนี้มีความสำคัญอย่างยิ่งในการจัดการกับความท้าทายที่เกิดจากอคติหรืออคติโดยธรรมชาติ ด้วยการแยกงานการประมวลผลอินพุตภายนอก FACTS Grounding ช่วยให้มั่นใจได้ว่าการวัดประสิทธิภาพสะท้อนถึงความสามารถของโมเดลในการทำงานในสถานการณ์จริงที่มีไดนามิก แทนที่จะเพียงดึงข้อมูลที่เรียนรู้ไว้ล่วงหน้ากลับคืนมา
ดังที่ DeepMind อธิบายไว้ในรายงานการวิจัย เกณฑ์มาตรฐานได้รับการออกแบบมาเพื่อประเมิน LLM เกี่ยวกับความสามารถในการจัดการคำถามที่ซับซ้อนและยาวโดยอาศัยข้อเท็จจริง เป็นการจำลองงานที่เกี่ยวข้องกับแอปพลิเคชันในโลกแห่งความเป็นจริง
วิธีการทางเลือกสำหรับการต่อสายดิน LLM
วิธีการหลายวิธีนำเสนอคุณสมบัติการต่อสายดินที่คล้ายกันกับการต่อสายดินของข้อเท็จจริง โดยแต่ละวิธีมีจุดแข็งและจุดอ่อน วิธีการเหล่านี้มีจุดมุ่งหมายเพื่อปรับปรุงผลลัพธ์ของ LLM โดยการปรับปรุงการเข้าถึงข้อมูลที่ถูกต้องหรือปรับปรุงกระบวนการฝึกอบรมและการจัดตำแหน่ง
Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) ช่วยเพิ่มความแม่นยำของเอาท์พุต LLM โดยการดึงข้อมูลที่เกี่ยวข้องแบบไดนามิกจากความรู้ภายนอก ฐานหรือฐานข้อมูลและรวมเข้ากับการตอบสนองของโมเดล แทนที่จะฝึกอบรม LLM ทั้งหมดใหม่ RAG จะทำงานโดยสกัดกั้นการแจ้งเตือนของผู้ใช้และเพิ่มข้อมูลที่ทันสมัย
การใช้งาน RAG ขั้นสูงมักจะใช้ประโยชน์จากการดึงข้อมูลตามเอนทิตี โดยที่ข้อมูลที่เกี่ยวข้องกับเอนทิตีเฉพาะจะรวมเป็นหนึ่งเดียว ให้บริบทที่มีความเกี่ยวข้องสูงสำหรับการตอบสนองของ LLM
โดยทั่วไปแล้ว RAG จะใช้เทคนิคการค้นหาเชิงความหมายในการดึงข้อมูล เอกสารหรือส่วนต่างๆ ของเอกสารได้รับการจัดทำดัชนีตามการฝังความหมาย ช่วยให้ระบบสามารถจับคู่คำค้นหาของผู้ใช้กับรายการที่เกี่ยวข้องตามบริบทมากที่สุด แนวทางนี้ช่วยให้แน่ใจว่า LLM สร้างคำตอบโดยได้รับแจ้งจากข้อมูลล่าสุดและเกี่ยวข้องมากที่สุด
ประสิทธิภาพของ RAG ขึ้นอยู่กับคุณภาพและการจัดระเบียบของฐานความรู้เป็นอย่างมาก รวมถึงความแม่นยำของอัลกอริธึมการดึงข้อมูล ในขณะที่ FACTS Grounding ประเมินความสามารถของ LLM ที่จะยังคงยึดติดกับเอกสารบริบทที่ให้มา RAG ก็ช่วยเสริมสิ่งนี้ด้วยการทำให้ LLM สามารถขยายความรู้แบบไดนามิก โดยดึงมาจากแหล่งข้อมูลภายนอกเพื่อเพิ่มข้อเท็จจริงและความเกี่ยวข้อง
การกลั่นความรู้
การกลั่นกรองความรู้เกี่ยวข้องกับการถ่ายโอน ความสามารถของแบบจำลองขนาดใหญ่และซับซ้อน (เรียกว่าครู) ไปสู่แบบจำลองเฉพาะงานที่มีขนาดเล็กกว่า (นักเรียน) วิธีการนี้ช่วยเพิ่มประสิทธิภาพในขณะที่ยังคงความแม่นยำของรุ่นดั้งเดิมไว้ได้มาก แนวทางหลักสองประการถูกนำมาใช้ในการกลั่นกรองความรู้:
การกลั่นกรองความรู้ตามการตอบสนอง: มุ่งเน้นไปที่การจำลองผลลัพธ์ของแบบจำลองของครู เพื่อให้แน่ใจว่าแบบจำลองของนักเรียนจะให้ผลลัพธ์ที่คล้ายคลึงกันสำหรับอินพุตที่กำหนด
การกลั่นกรองความรู้ตามคุณลักษณะ: แยกการนำเสนอและคุณลักษณะภายในออกจากโมเดลของครู ทำให้โมเดลของนักเรียนจำลองข้อมูลเชิงลึกที่ลึกซึ้งยิ่งขึ้นได้
โดยการปรับปรุงให้เล็กลง การกลั่นความรู้ช่วยให้สามารถปรับใช้ LLM ในสภาพแวดล้อมที่มีทรัพยากรจำกัดได้โดยไม่สูญเสียประสิทธิภาพอย่างมีนัยสำคัญ แตกต่างจาก FACTS Grounding ซึ่งประเมินความถูกต้องของสายดิน การกลั่นความรู้เกี่ยวข้องกับการปรับขนาดความสามารถของ LLM และการเพิ่มประสิทธิภาพสำหรับงานเฉพาะ
การปรับแต่งอย่างละเอียดด้วยชุดข้อมูลที่มีการต่อสายดิน
การปรับแต่งอย่างละเอียดเกี่ยวข้องกับการปรับตัวที่ได้รับการฝึกอบรมมาล่วงหน้า LLM ไปยังโดเมนหรืองานเฉพาะโดยการฝึกอบรมพวกเขาเกี่ยวกับชุดข้อมูลที่รวบรวมไว้ซึ่งพื้นฐานข้อเท็จจริงเป็นสิ่งสำคัญ ตัวอย่างเช่น ชุดข้อมูลที่ประกอบด้วยวรรณกรรมทางวิทยาศาสตร์หรือบันทึกทางประวัติศาสตร์สามารถนำมาใช้เพื่อปรับปรุงความสามารถของแบบจำลองในการสร้างผลลัพธ์ที่แม่นยำและเฉพาะเจาะจงโดเมน เทคนิคนี้ช่วยเพิ่มประสิทธิภาพ LLM สำหรับการใช้งานเฉพาะทาง เช่น การวิเคราะห์เอกสารทางการแพทย์หรือทางกฎหมาย
อย่างไรก็ตาม การปรับแต่งอย่างละเอียดต้องใช้ทรัพยากรจำนวนมากและเสี่ยงต่อการลืมอย่างหายนะ โดยที่แบบจำลองจะสูญเสียความรู้ที่ได้รับระหว่างการฝึกอบรมครั้งแรก ข้อเท็จจริง Grounding มุ่งเน้นไปที่การทดสอบข้อเท็จจริงในบริบทที่แยกออกมา ในขณะที่การปรับแต่งอย่างละเอียดพยายามปรับปรุงประสิทธิภาพพื้นฐานของ LLM ในพื้นที่เฉพาะ
การเรียนรู้แบบเสริมกำลังด้วยผลตอบรับของมนุษย์ (RLHF)
การเรียนรู้แบบเสริมกำลังด้วยการตอบสนองของมนุษย์ (RLHF) รวมเอามนุษย์ การตั้งค่าในกระบวนการฝึกอบรมของ LLM ด้วยการฝึกแบบจำลองซ้ำๆ เพื่อปรับการตอบสนองให้สอดคล้องกับความคิดเห็นของมนุษย์ RLHF จะปรับปรุงคุณภาพ ข้อเท็จจริง และประโยชน์ของผลลัพธ์ ผู้ประเมินที่เป็นมนุษย์จะให้คะแนนผลลัพธ์ของ LLM และคะแนนเหล่านี้จะใช้เป็นสัญญาณในการปรับโมเดลให้เหมาะสม
RLHF ประสบความสำเร็จเป็นพิเศษในการเพิ่มความพึงพอใจของผู้ใช้ และรับรองว่าการตอบสนองที่สร้างขึ้นนั้นสอดคล้องกับความคาดหวังของมนุษย์ ในขณะที่ FACTS Grounding ประเมินข้อเท็จจริงตามเอกสารเฉพาะ RLHF เน้นการจัดเอาต์พุต LLM ให้สอดคล้องกับคุณค่าและความชอบของมนุษย์
การติดตามคำแนะนำและการเรียนรู้ในบริบท
การเรียนรู้ตามคำสั่งและการเรียนรู้ในบริบทเกี่ยวข้องกับการสาธิตพื้นฐาน LLM ผ่านตัวอย่างที่สร้างขึ้นอย่างพิถีพิถันภายในพร้อมท์ผู้ใช้ วิธีการเหล่านี้ขึ้นอยู่กับความสามารถของโมเดลในการสรุปจากการสาธิตเพียงไม่กี่ช็อต แม้ว่าแนวทางนี้สามารถให้การปรับปรุงอย่างรวดเร็ว แต่ก็อาจไม่บรรลุถึงคุณภาพการต่อสายดินในระดับเดียวกับวิธีการปรับแต่งหรือดึงข้อมูล
เครื่องมือภายนอกและ API
LLM สามารถผสานรวมกับเครื่องมือและ API ภายนอกเพื่อให้สามารถเข้าถึงข้อมูลภายนอกแบบเรียลไทม์ ซึ่งช่วยเพิ่มความสามารถในการต่อสายดินได้อย่างมาก ตัวอย่างได้แก่:
ความสามารถในการเรียกดู: ช่วยให้ LLM สามารถเข้าถึงและดึงข้อมูลแบบเรียลไทม์จากเว็บเพื่อตอบคำถามเฉพาะหรืออัปเดตความรู้
การเรียก API: ช่วยให้ LLM สามารถโต้ตอบกับฐานข้อมูลหรือบริการที่มีโครงสร้าง เพิ่มการตอบสนองด้วยข้อมูลที่แม่นยำและทันสมัย
เครื่องมือเหล่านี้ขยายอรรถประโยชน์ของ LLM โดยการเชื่อมต่อเข้ากับของจริง-ความรู้ทางโลก แหล่งที่มา ปรับปรุงความสามารถในการสร้างผลลัพธ์ที่แม่นยำและมีเหตุผล ในขณะที่ FACTS Grounding ประเมินความเที่ยงตรงของการต่อสายดินภายใน เครื่องมือภายนอกจะมอบทางเลือกอื่นในการขยายและตรวจสอบข้อเท็จจริง
การต่อสายดินแบบจำลองโอเพ่นซอร์ส ตัวเลือก
การใช้งานโอเพ่นซอร์สหลายอย่างพร้อมใช้งานสำหรับวิธีการต่อลงดินทางเลือกที่กล่าวถึงข้างต้น:
ผลกระทบสำหรับแอปพลิเคชันที่มีเดิมพันสูง
ความสำคัญของความถูกต้องแม่นยำ และ การตอบสนองของ AI ที่มีพื้นฐานชัดเจนโดยเฉพาะอย่างยิ่งในการใช้งานที่มีความเสี่ยงสูง เช่น การวินิจฉัยทางการแพทย์ การตรวจสอบทางกฎหมาย และการวิเคราะห์ทางการเงิน ในบริบทเหล่านี้ แม้แต่ความไม่ถูกต้องเล็กน้อยก็สามารถนำไปสู่ผลลัพธ์ที่สำคัญได้ ทำให้ความน่าเชื่อถือของเอาต์พุตที่สร้างโดย AI เป็นข้อกำหนดที่ไม่สามารถต่อรองได้
ข้อเท็จจริง การเน้นย้ำของ Grounding เกี่ยวกับข้อเท็จจริงและการยึดมั่นในแหล่งข้อมูลทำให้มั่นใจได้ว่าแบบจำลองจะได้รับการทดสอบภายใต้เงื่อนไขที่สะท้อนความต้องการในโลกแห่งความเป็นจริงอย่างใกล้ชิด
ตัวอย่างเช่น ในบริบททางการแพทย์ LLM ที่ได้รับมอบหมายให้ดูแล การสรุปบันทึกผู้ป่วยต้องหลีกเลี่ยงข้อผิดพลาดที่อาจให้ข้อมูลการตัดสินใจในการรักษาที่ไม่ถูกต้อง ในทำนองเดียวกัน ในการตั้งค่าทางกฎหมาย การสร้างบทสรุปหรือการวิเคราะห์คดีต่างๆ จำเป็นต้องมีพื้นฐานที่ชัดเจนในเอกสารที่ให้มา
ข้อเท็จจริง Grounding ไม่เพียงแต่ประเมินแบบจำลองเกี่ยวกับความสามารถในการปฏิบัติตามข้อกำหนดที่เข้มงวดเหล่านี้ แต่ยังสร้างเกณฑ์มาตรฐานสำหรับนักพัฒนาเพื่อมุ่งเป้าในการสร้างระบบที่เหมาะสมสำหรับแอปพลิเคชันดังกล่าว
การขยาย ชุดข้อมูล FACTS และทิศทางในอนาคต
DeepMind ได้วางตำแหน่ง FACTS Grounding ให้เป็น”เกณฑ์มาตรฐานที่มีชีวิต”ซึ่งจะพัฒนาควบคู่ไปกับความก้าวหน้าใน AI การอัปเดตในอนาคตมีแนวโน้มที่จะขยายชุดข้อมูลให้รวม โดเมนและประเภทงานใหม่ๆ ช่วยให้มั่นใจว่ามีความเกี่ยวข้องอย่างต่อเนื่องในขณะที่ความสามารถของ LLM เติบโตขึ้น
นอกจากนี้ การเปิดตัวเทมเพลตการประเมินที่หลากหลายมากขึ้นยังช่วยเพิ่มความแข็งแกร่งของกระบวนการให้คะแนน จัดการกับกรณี Edge และลดอคติที่หลงเหลืออยู่
ดังที่ทีมวิจัยของ DeepMind รับทราบ ไม่มีเกณฑ์มาตรฐานใดที่สามารถสรุปความซับซ้อนของแอปพลิเคชันในโลกแห่งความเป็นจริงได้อย่างสมบูรณ์ อย่างไรก็ตาม โดยการทำซ้ำบน FACTS Grounding และการมีส่วนร่วมกับชุมชน AI ในวงกว้าง โครงการนี้มีจุดมุ่งหมายเพื่อยกระดับความเป็นจริงและพื้นฐานในระบบ AI
ดังที่ทีมงานของ DeepMind กล่าวว่า “ข้อเท็จจริงและพื้นฐานเป็นหนึ่งในปัจจัยสำคัญที่จะกำหนดความสำเร็จและประโยชน์ของ LLM และระบบ AI ที่กว้างขึ้นในอนาคต และเราตั้งเป้าที่จะเติบโตและทำซ้ำ FACTS Grounding ในขณะที่ภาคสนามดำเนินไป ยกระดับมาตรฐานอย่างต่อเนื่อง”