Mark Russinovich ประธานเจ้าหน้าที่ฝ่ายเทคโนโลยีของ Microsoft Azure ได้เน้นย้ำข้อกังวลด้านความปลอดภัยที่เพิ่มขึ้นที่เกี่ยวข้องกับ generative AI ในการพูดที่การประชุม Microsoft Build 2024 ในซีแอตเทิล Russinovich เน้นย้ำถึงความหลากหลาย ภัยคุกคามต่างๆ ที่ประธานเจ้าหน้าที่รักษาความปลอดภัยข้อมูล (CISO) และนักพัฒนาต้องเผชิญเมื่อพวกมันรวมเทคโนโลยี AI เชิงสร้างสรรค์เข้าด้วยกัน เขาเน้นย้ำถึงความจำเป็นสำหรับแนวทางการรักษาความปลอดภัยของ AI แบบสหสาขาวิชาชีพ ซึ่งรวมถึงการพิจารณาภัยคุกคามจากมุมต่างๆ เช่น แอปพลิเคชัน AI, โค้ดโมเดลพื้นฐาน, คำขอ API, ข้อมูลการฝึกอบรม และแบ็คดอร์ที่อาจเกิดขึ้น
การวางยาพิษของข้อมูล และแบบจำลองที่ไม่ถูกต้อง
ข้อกังวลหลักประการหนึ่งที่ Russinovich กล่าวถึงคือข้อมูลเป็นพิษ ในการโจมตีเหล่านี้ ผู้ไม่หวังดีจะจัดการชุดข้อมูลที่ใช้ในการฝึกโมเดล AI หรือการเรียนรู้ของเครื่อง ซึ่งนำไปสู่ผลลัพธ์ที่เสียหาย เขาอธิบายสิ่งนี้ด้วยตัวอย่างที่สัญญาณรบกวนดิจิทัลที่เพิ่มเข้าไปในรูปภาพทำให้ AI จำแนกแพนด้าเป็นลิงผิดประเภท การโจมตีประเภทนี้อาจเป็นการร้ายกาจอย่างยิ่ง เพราะแม้แต่การเปลี่ยนแปลงเล็กน้อย เช่น การแทรกประตูหลัง ก็อาจส่งผลกระทบอย่างมีนัยสำคัญต่อประสิทธิภาพของแบบจำลอง
Russinovich ยังกล่าวถึงปัญหาของ แบ็คดอร์ภายในโมเดล AI แม้ว่ามักจะถูกมองว่าเป็นช่องโหว่ แต่แบ็คดอร์ยังสามารถทำหน้าที่ตรวจสอบความถูกต้องและความสมบูรณ์ของโมเดลได้อีกด้วย เขาอธิบายว่าแบ็คดอร์สามารถใช้เพื่อพิมพ์ลายนิ้วมือให้กับโมเดลได้ ทำให้ซอฟต์แวร์สามารถตรวจสอบความถูกต้องได้ ซึ่งเกี่ยวข้องกับการเพิ่มคำถามเฉพาะลงในโค้ดที่ผู้ใช้จริงไม่น่าจะถาม ดังนั้นจึงรับประกันความสมบูรณ์ของโมเดล
เทคนิคการฉีดทันที
ภัยคุกคามที่สำคัญอีกประการที่ Russinovich เน้นย้ำคือเทคนิคการฉีดทันที สิ่งเหล่านี้เกี่ยวข้องกับการแทรกข้อความที่ซ่อนอยู่ในบทสนทนา ซึ่งอาจนำไปสู่การรั่วไหลของข้อมูลหรือมีอิทธิพลต่อพฤติกรรมของ AI นอกเหนือจากการดำเนินการที่ตั้งใจไว้ เราได้เห็นแล้วว่า GPT-4 V ของ OpenAI มีความเสี่ยงต่อการโจมตีประเภทนี้อย่างไร เขาแสดงให้เห็นว่าชิ้นส่วนของข้อความที่ซ่อนอยู่แทรกเข้าไปในบทสนทนาอาจส่งผลให้เกิดการรั่วไหลของข้อมูลส่วนตัวได้อย่างไร คล้ายกับการโจมตีด้วยสคริปต์ข้ามไซต์ในการรักษาความปลอดภัยบนเว็บ สิ่งนี้จำเป็นต้องแยกผู้ใช้ เซสชัน และเนื้อหาออกจากกันเพื่อป้องกันการโจมตีดังกล่าว
ข้อกังวลระดับแนวหน้าของ Microsoft คือปัญหาที่เกี่ยวข้องกับการเปิดเผยข้อมูลที่ละเอียดอ่อน เทคนิคการเจลเบรกเพื่อแซงหน้าโมเดล AI และการบังคับให้บุคคลที่สาม-แอปพลิเคชันปาร์ตี้และปลั๊กอินโมเดลเพื่อหลีกเลี่ยงตัวกรองความปลอดภัยหรือสร้างเนื้อหาที่ถูกจำกัด Russinovich กล่าวถึงวิธีการโจมตีเฉพาะอย่าง Crescendo ซึ่งสามารถเลี่ยงมาตรการความปลอดภัยของเนื้อหาเพื่อกระตุ้นให้เกิดแบบจำลองในการสร้างเนื้อหาที่เป็นอันตรายได้
แนวทางแบบองค์รวมเพื่อความปลอดภัยของ AI
Russinovich เปรียบเทียบโมเดล AI กับ”พนักงานที่ฉลาดจริงๆ แต่เป็นผู้เยาว์หรือไร้เดียงสา”ซึ่งแม้จะฉลาด แต่ก็มีความเสี่ยงที่จะถูกบงการและสามารถดำเนินการกับนโยบายขององค์กรได้โดยไม่ต้องมีการควบคุมดูแลอย่างเข้มงวด เขาเน้นย้ำถึงความเสี่ยงด้านความปลอดภัยโดยธรรมชาติภายในโมเดลภาษาขนาดใหญ่ (LLM) และ จำเป็นต้องมีรั้วกั้นที่เข้มงวดเพื่อบรรเทาช่องโหว่เหล่านี้
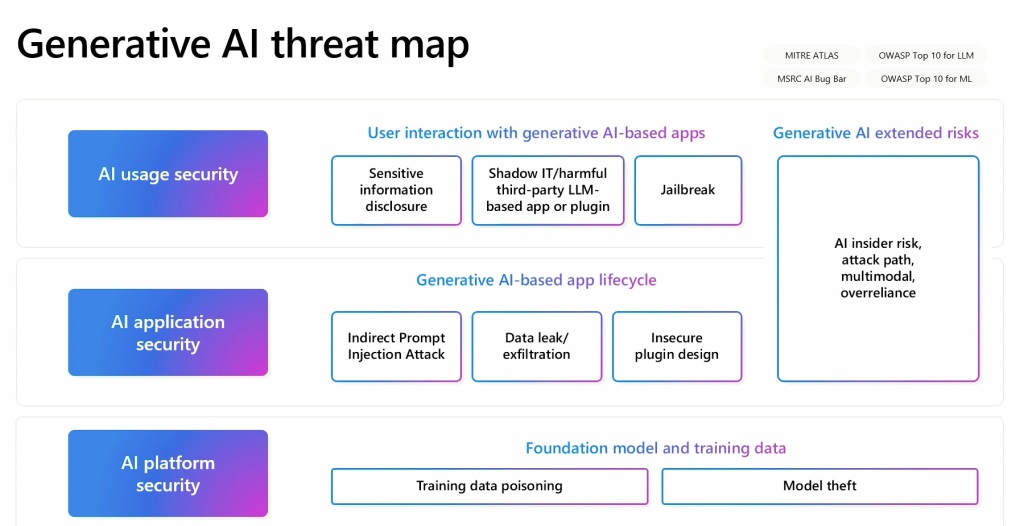
Russinovich ได้พัฒนาแผนที่ภัยคุกคาม AI ที่สร้างโครงร่างความสัมพันธ์ระหว่างองค์ประกอบต่างๆ เหล่านี้ แผนที่นี้ทำหน้าที่เป็นเครื่องมือสำคัญในการทำความเข้าใจและจัดการกับธรรมชาติที่หลากหลายของการรักษาความปลอดภัย AI ภัยคุกคาม เขายกตัวอย่างว่าการลงข้อมูลเป็นพิษบนหน้า Wikipedia ซึ่งทราบกันดีว่าเป็นแหล่งข้อมูลอาจนำไปสู่ปัญหาระยะยาวได้อย่างไรแม้ว่าข้อมูลจะได้รับการแก้ไขในภายหลังก็ตาม ซึ่งทำให้การติดตามข้อมูลที่ถูกวางยาพิษนั้นเป็นเรื่องที่ท้าทายเนื่องจากไม่มีอีกต่อไป มีอยู่ในแหล่งดั้งเดิม