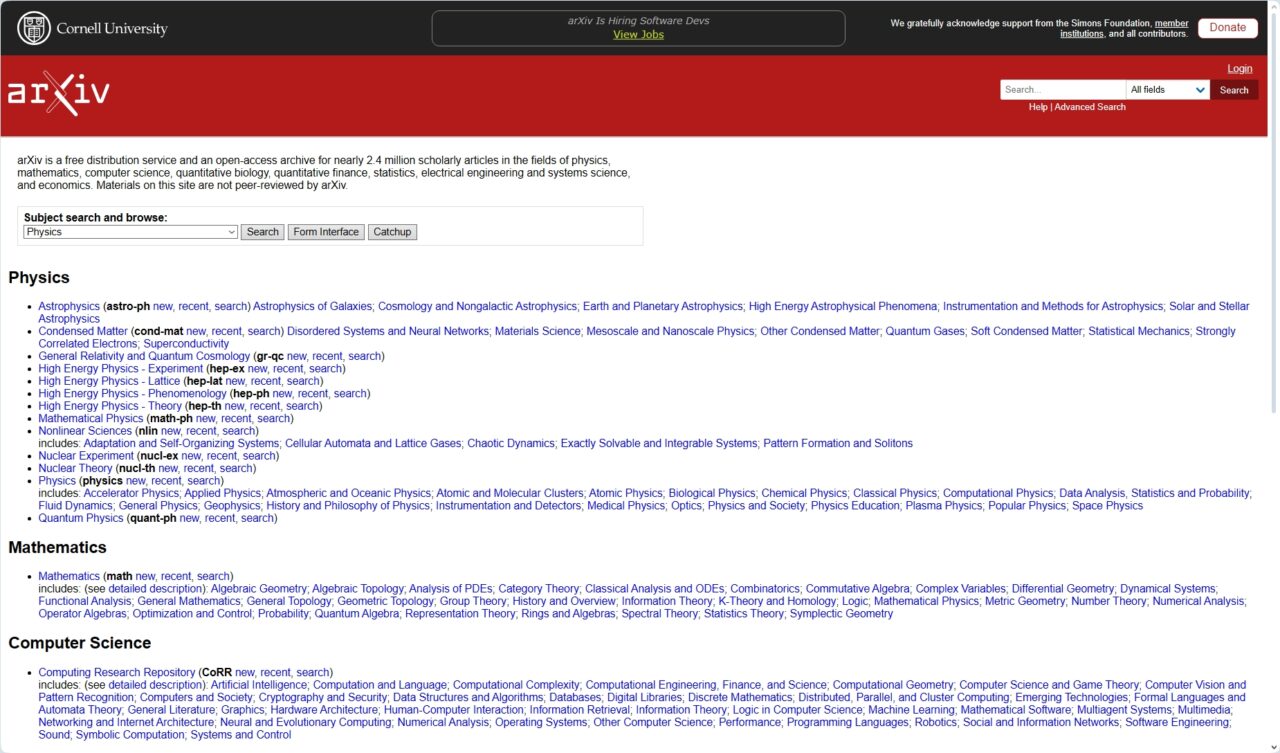
เมื่อเผชิญกับปริมาณเนื้อหาคุณภาพต่ำที่สร้างโดย AI เซิร์ฟเวอร์เตรียมพิมพ์ทางวิชาการ arXiv จึงเข้มงวดกฎการส่งเอกสารวิทยาการคอมพิวเตอร์
ในประกาศเมื่อวันที่ 31 ตุลาคม แพลตฟอร์มที่ทรงอิทธิพลดังกล่าวระบุว่าหมวดหมู่วิทยาการคอมพิวเตอร์ (CS) จะไม่รับบทความวิจารณ์หรือเอกสารแสดงตำแหน่งอีกต่อไป เว้นแต่ว่าบทความเหล่านั้นจะผ่านการทบทวนโดยผู้ทรงคุณวุฒิในวารสารหรือการประชุมที่ได้รับการยอมรับแล้ว
ความเคลื่อนไหวดังกล่าวได้รับการออกแบบมาเพื่อลดภาระของผู้ดูแลอาสาสมัคร และเผชิญหน้าโดยตรงกับการส่งบทความจำนวนมากที่ arXiv กล่าวว่า”รวดเร็วและง่ายต่อการเขียน”ด้วย AI เชิงสร้างสรรค์แต่มักจะขาดสาระสำคัญ
น้ำท่วมของ’Slop’ที่สร้างโดย AI
ในความพยายามที่จะรักษาคุณภาพการวิจัย arXiv กำลังเผชิญหน้าโดยตรงกับผลกระทบจากแบบจำลองภาษาขนาดใหญ่ที่มีต่อการเผยแพร่ทางวิชาการ แพลตฟอร์มดังกล่าวมีผู้ส่งเข้ามาอย่างล้นหลาม โดยเฉพาะอย่างยิ่งในส่วนวิทยาการคอมพิวเตอร์ที่มีการเปลี่ยนแปลงอย่างรวดเร็ว
ตามคำแถลงอย่างเป็นทางการ เว็บไซต์ดังกล่าวได้รับ”บทความวิจารณ์หลายร้อยบทความทุกเดือน”ปริมาณที่แท้จริงของมันกลายเป็นสิ่งที่ไม่สามารถจัดการได้สำหรับระบบการตรวจสอบของแพลตฟอร์ม
ผลงานเหล่านี้จำนวนมากไม่เป็นไปตามมาตรฐานทางวิชาการขั้นพื้นฐาน ผู้ดำเนินรายการ arXiv พบว่า “บทความวิจารณ์ส่วนใหญ่ที่เราได้รับนั้นมีอะไรมากกว่าบรรณานุกรมที่มีคำอธิบายประกอบเล็กน้อย โดยไม่มีการอภิปรายที่สำคัญเกี่ยวกับประเด็นการวิจัยแบบเปิด”
เอกสารดังกล่าวมีส่วนส่งเสียงทางวิชาการ ทำให้เสียเวลาของนักวิจัยในการค้นหาข้อมูลเชิงลึกใหม่ๆ ความง่ายในการผลิตดังกล่าวได้นำไปสู่ความเครียดอย่างมากต่อผู้เชี่ยวชาญอาสาสมัครที่ตรวจสอบเอกสาร
ดังที่ arXiv อธิบายไว้ว่า “AI ทั่วไป/โมเดลภาษาขนาดใหญ่ได้เพิ่มเข้ามาในกระแสนี้ด้วยการทำเอกสาร—โดยเฉพาะอย่างยิ่งเอกสารที่ไม่แนะนำผลการวิจัยใหม่—รวดเร็วและง่ายต่อการเขียน”
เนื้อหาที่ต้องใช้ความพยายามต่ำที่เพิ่มขึ้นนี้คุกคามที่จะฝังการวิจัยที่ถูกต้องตามกฎหมายและลดคุณค่าของแพลตฟอร์ม
เครื่องมือที่ซับซ้อนที่เปิดใช้งาน น้ำท่วมครั้งนี้ก็มีจำนวนและความสามารถเพิ่มขึ้นเช่นกัน บทความล่าสุด เช่นเดียวกับเอกสารที่อธิบายผู้ช่วยวิจัย AI หลายตัวแทน แสดงให้เห็นถึงเทคโนโลยีที่สามารถทำให้กระบวนการเขียนเชิงวิชาการทั้งหมดเป็นอัตโนมัติตั้งแต่แนวคิดไปจนถึงการร่าง
เทคโนโลยีนี้ทำให้การสร้างการวิจารณ์วรรณกรรมที่ดูน่าเชื่อถือแต่ท้ายที่สุดแล้วกลวงเปล่า กลายเป็นเรื่องเล็กน้อย ซึ่งทำให้ปัญหาที่ arXiv กำลังพยายามแก้ไขรุนแรงขึ้น การกำหนดให้มีการตรวจสอบโดยผู้ทรงคุณวุฒิก่อนทำหน้าที่เป็นตัวกรองที่สำคัญ โดยจ้างบุคคลภายนอกเพื่อควบคุมคุณภาพเบื้องต้นให้กับวารสารและการประชุมที่จัดตั้งขึ้น
ระบบภายใต้แรงกดดัน
แม้ว่าการเปลี่ยนแปลงนโยบายจะเป็นเรื่องใหม่ แต่ปัญหาที่ซ่อนอยู่กลับไม่ได้เป็นเช่นนั้น กระบวนการตรวจสอบโดยผู้ทรงคุณวุฒิทางวิชาการประสบปัญหามาหลายปีภายใต้วัฒนธรรม”เผยแพร่หรือพินาศ”ที่สร้างแรงจูงใจให้กับปริมาณมากกว่าคุณภาพ
ผู้เชี่ยวชาญเช่น Satoshi Tanaka จาก Kyoto Pharmaceutical University ได้แย้งว่ากระบวนการตรวจสอบโดยผู้ทรงคุณวุฒิในแวดวงวิชาการ”อยู่ในภาวะวิกฤต”
การรวมวิกฤตเข้าด้วยกันคือ มีผู้ตรวจสอบอาสาสมัครจำนวนจำกัด ซึ่งมีผลงานส่งเข้ามาอย่างล้นหลาม ความเหนื่อยล้านี้ก่อให้เกิดช่องโหว่ที่เครื่องมือ AI ทั้งด้านดีและด้านร้ายกำลังเริ่มใช้ประโยชน์
arXiv เคยเป็นศูนย์กลางของการถกเถียงเกี่ยวกับ AI และความซื่อสัตย์ทางวิชาการมาก่อน เมื่อปีที่แล้ว นักวิจัยพบว่ามีการฝังคำสั่งที่ซ่อนอยู่ในเอกสารของตนเพื่อจัดการกับระบบการตรวจสอบที่ขับเคลื่อนด้วย AI ซึ่งเป็นแนวทางปฏิบัติที่เรียกว่าการแทรกคำสั่งทันที
ผู้เขียนพยายามปกปิดคำแนะนำด้วยข้อความสีขาวหรือแบบอักษรขนาดเล็กเพื่อหลอกให้ระบบอัตโนมัติให้การตอบรับเชิงบวก เหตุการณ์ดังกล่าวเน้นย้ำว่าระบบอัตโนมัติสามารถเล่นเกมได้ง่ายเพียงใด ซึ่งบ่อนทำลายกระบวนการตรวจสอบทั้งหมด
ความแตกต่างเล็กน้อยในการเปลี่ยนแปลงล่าสุดของ arXiv ทำให้เกิดความสับสน โดยในตอนแรกช่องทางบางแห่งรายงานขอบเขตของกฎใหม่อย่างไม่ถูกต้อง
ไม่ใช่นโยบายใหม่ แต่เป็นการบังคับใช้ที่จำเป็น
เจ้าหน้าที่ arXiv อ้างถึงการยื่นเข้ามาจำนวนมากที่ไม่สามารถจัดการได้ ชี้แจงว่าการเปลี่ยนแปลงนี้เป็นการดำเนินการบังคับใช้มากกว่านโยบายใหม่
บทความวิจารณ์และเอกสารแสดงจุดยืนไม่เคยได้รับการยอมรับอย่างเป็นทางการในประเภทเนื้อหา แต่ในอดีตจะได้รับอนุญาตตามดุลยพินิจของผู้ดำเนินรายการเมื่อบทความเหล่านั้นมีคุณภาพสูงและความสนใจทางวิชาการ
ปริมาณที่เพิ่มขึ้นอย่างรวดเร็วเมื่อเร็วๆ นี้ซึ่งขับเคลื่อนโดย AI ส่งผลให้แนวทางการใช้ดุลยพินิจดังกล่าวไม่สามารถป้องกันได้ การปกป้องเวลาของผู้ตรวจสอบอาสาสมัครเหล่านี้ ซึ่งเป็นรากฐานของระบบการพิมพ์ล่วงหน้า ถือเป็นสิ่งสำคัญ
แนวทางปฏิบัติของแพลตฟอร์ม arXiv ระบุว่าผู้เขียนที่เป็นมนุษย์จะต้องรับผิดชอบอย่างเต็มที่ต่อเนื้อหาใดๆ ที่ผลิตโดยเครื่องมือ AI และห้ามอย่างชัดเจนในการลงรายการ AI เป็นผู้เขียนร่วม
การนำแนวทางปฏิบัติในการกลั่นกรองแบบใหม่นี้มาใช้สำหรับหมวดหมู่ CS ถือเป็นการขยายตรรกะของหลักการนี้ ซึ่งตอกย้ำว่าการตรวจสอบความถูกต้องที่นำโดยมนุษย์ยังคงเป็นสิ่งสำคัญยิ่ง ผู้เผยแพร่โฆษณาทั่วทั้งอุตสาหกรรมกำลังต่อสู้กับสิ่งนี้ โดยสร้างนโยบายที่กระจัดกระจาย
แม้ว่าบางแห่งจะอนุญาตให้มีการใช้ AI อย่างจำกัด บริษัทอื่นๆ เช่น Elsevier ได้สั่งห้ามโดยสิ้นเชิง โดยอ้างถึง”ความเสี่ยงที่เทคโนโลยีจะสร้างข้อสรุปที่ไม่ถูกต้อง ไม่สมบูรณ์ หรือเอนเอียง”
เมื่อมองไปข้างหน้า แพลตฟอร์มได้ระบุว่าสาขาอื่นๆ อาจเห็นการเปลี่ยนแปลงที่คล้ายกัน ในการประกาศ arXiv ตั้งข้อสังเกตว่า”หากหมวดหมู่อื่นๆ เห็นการเพิ่มขึ้นที่คล้ายกันในบทความวิจารณ์ที่เขียนโดย LLM และเอกสารแสดงจุดยืน พวกเขาอาจเลือกที่จะเปลี่ยนแนวทางปฏิบัติในการกลั่นกรองในลักษณะที่คล้ายกัน…”
การเคลื่อนไหวดังกล่าวชี้ให้เห็นถึงการเปลี่ยนแปลงที่อาจเกิดขึ้นทั่วทั้งแพลตฟอร์ม หากคลื่นของเนื้อหาที่สร้างโดย AI ยังคงแพร่กระจายต่อไป โดยวางตำแหน่งการเคลื่อนไหวของ arXiv ไม่ใช่เป็นการแก้ไขแบบแยกส่วน แต่เป็นตัวชี้ว่าชุมชนวิทยาศาสตร์ทั้งหมดจะถูกบังคับให้ปรับตัวเข้ากับความท้าทายและการล่อลวงของ generative AI อย่างไร