DeepSeek สตาร์ทอัพด้านปัญญาประดิษฐ์ (AI) ของจีนกำลังเขย่ารากฐานของตลาดเทคโนโลยีระดับโลก ทำให้เกิดคำถามกับการประเมินมูลค่าที่สูงเกินจริงของยักษ์ใหญ่ด้านเทคโนโลยีของสหรัฐฯ
โมเดล R1 ของบริษัทซึ่งเปิดตัวเมื่อวันที่ 10 มกราคม ได้พิสูจน์แล้วว่าระบบ AI ที่สามารถแข่งขันได้สามารถพัฒนาได้โดยใช้ทรัพยากรเพียงเล็กน้อยที่ผู้นำในอุตสาหกรรมโดยทั่วไปต้องการ
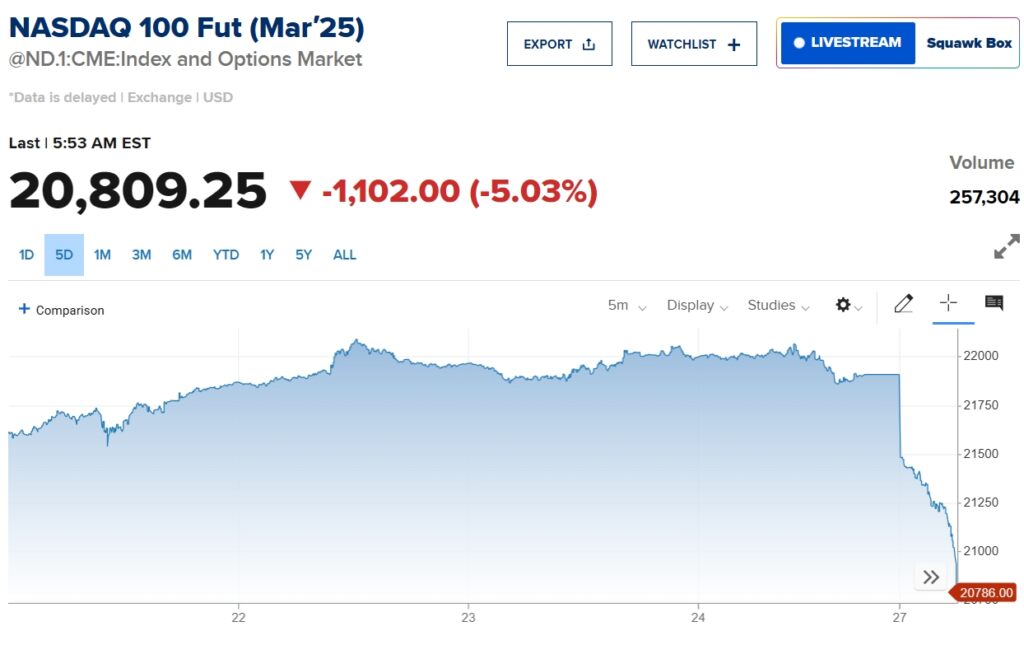
ส่งผลให้ Nasdaq 100 Futures ร่วงลงมากกว่า 5% ในวันจันทร์ ในขณะที่นักลงทุนต่อสู้กับผลกระทบดังกล่าว บางคนก็ถามคำถามเร่งด่วนว่า DeepSeek เพิ่งจะระเบิดฟองสบู่ตลาดหุ้นเทคโนโลยีของสหรัฐฯ หรือไม่
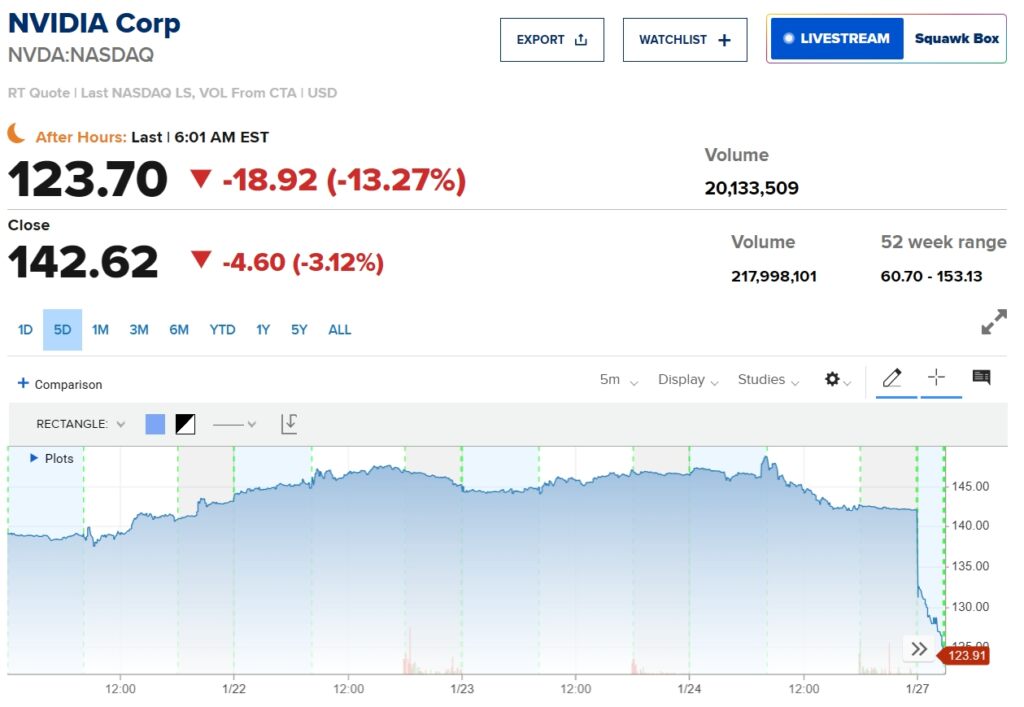
Nvidia ลูกโปสเตอร์ของ AI บูม พบว่าหุ้นดิ่งลงมากกว่า 13% ในการซื้อขายล่วงหน้า
แก่นแท้ของการเปลี่ยนแปลงครั้งใหญ่คือประสิทธิภาพเชิงปฏิวัติของ DeepSeek R1 ต่างจากรุ่นที่พัฒนาโดย OpenAI และ Meta ที่ต้องอาศัยฮาร์ดแวร์ประสิทธิภาพสูงและมีราคาแพง R1 มีประสิทธิภาพที่เทียบเคียงได้โดยใช้ GPU H800 ของ Nvidia ซึ่งเป็นชิปเกรดต่ำกว่าที่ถูกจำกัดโดยการคว่ำบาตรของสหรัฐอเมริกา
ที่เกี่ยวข้อง: DeepSeek R1 เหนือกว่า ChatGPT o1 อย่างไรภายใต้การคว่ำบาตร กำหนดนิยามใหม่ให้กับประสิทธิภาพ AI โดยใช้ GPU เพียง 2,048 ตัว
ความสำเร็จนี้ได้พลิกโฉมสถานะที่มีมายาวนาน สมมติฐานเกี่ยวกับความจำเป็นในการใช้จ่ายโครงสร้างพื้นฐานจำนวนมากในการพัฒนา AI และทำให้เกิดข้อกังวลใหม่เกี่ยวกับความยั่งยืนของโมเดลธุรกิจของ Silicon Valley
DeepSeek R1: ผู้ท้าชิงที่คุ้มค่าต่อต้นทุนของ Silicon Valley
โมเดล R1 ของ DeepSeek ถือเป็นหลักชัยสำคัญของนวัตกรรม AI โดยไต่ขึ้นสู่จุดสูงสุดอย่างรวดเร็วใน App Store ของ Apple ในสหรัฐอเมริกา เพียงไม่กี่วันหลังจากเปิดตัว ด้วยความโปร่งใสในกระบวนการให้เหตุผล แอปนี้ได้รับการยกย่องในเรื่องความสามารถในการแก้ไขคำถามที่ซับซ้อนได้อย่างมีประสิทธิภาพ รีวิวจากผู้ใช้เน้นย้ำถึงความสามารถในการเข้าถึงและความน่าเชื่อถือ ซึ่งตรงกันข้ามกับแนวทางที่เน้นทรัพยากรของคู่ค้าในสหรัฐฯ
โมเดลดังกล่าวได้รับการฝึกอบรมโดยใช้ GPU Nvidia H800 จำนวน 2,048 ตัว ในราคารวมต่ำกว่า 6 ล้านเหรียญสหรัฐ ตามข้อมูลในเดือนธันวาคม 2024 บทความวิจัยที่เผยแพร่โดย DeepSeek GPU เหล่านี้ได้รับการออกแบบโดยตั้งใจให้มีความสามารถลดลงเพื่อให้สอดคล้องกับข้อจำกัดการส่งออกของสหรัฐอเมริกา ทำให้เกิดความท้าทายที่ไม่เหมือนใคร
ทว่า วิศวกรของ DeepSeek ได้พัฒนาเทคนิคการเพิ่มประสิทธิภาพแบบใหม่เพื่อลดความต้องการด้านการคำนวณและหน่วยความจำ ให้บรรลุเกณฑ์มาตรฐานประสิทธิภาพที่ 97.3% ใน MATH-500 และ 79.8% ใน AIME 2024
ผู้ก่อตั้ง Liang Wenfeng อดีตผู้จัดการกองทุนเฮดจ์ฟันด์กล่าวถึงกลยุทธ์ของบริษัทว่า “เราประเมินว่าโมเดลในประเทศและต่างประเทศที่ดีที่สุดอาจมีช่องว่าง 1 เท่าในโครงสร้างโมเดลและการฝึกอบรม พลวัต ด้วยเหตุนี้ เราจึงจำเป็นต้องใช้พลังการประมวลผลเพิ่มขึ้นสี่เท่าเพื่อให้ได้ผลลัพธ์เดียวกัน สิ่งที่เราต้องทำคือจำกัดช่องว่างเหล่านี้ให้แคบลงอย่างต่อเนื่อง”[36Kr]
ผลกระทบจากระลอกคลื่นในตลาดโลก
การเปิดตัว R1 กระตุ้นให้เกิดการขายออกอย่างรวดเร็วใน หุ้นเทคโนโลยีระดับโลก Nvidia ซึ่งได้รับการยกย่องอย่างกว้างขวางว่าจำเป็นต่อการพัฒนา AI มีมูลค่าลดลงนับพันล้าน
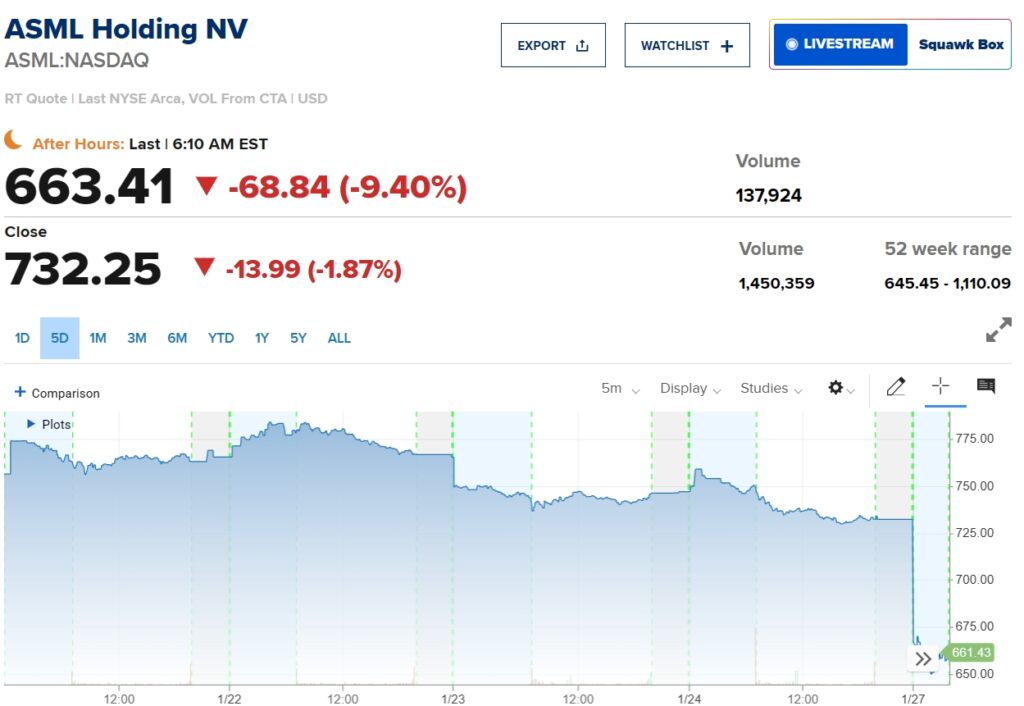
ผู้ผลิตชิปของยุโรป ASML Holding NV ก็ประสบปัญหาการลดลง 11% ในขณะที่ Nasdaq 100 Futures มีปริมาณการซื้อขายสี่เท่าของค่าเฉลี่ยรายวัน ภายในช่วงต้นวันจันทร์ นักลงทุนกำลังประเมินรากฐานทางการเงินของภาคส่วน AI อีกครั้ง ซึ่งได้ขับเคลื่อนการเติบโตอย่างมีนัยสำคัญของหุ้นเทคโนโลยีในปีที่ผ่านมา
ผลกระทบดังกล่าวขยายไปไกลกว่าสหรัฐอเมริกา โดยมีชาวจีน หุ้นที่เกี่ยวข้องกับ AI เช่น Merit Interactive Co. เพิ่มขึ้นมากถึง 20% เพื่อตอบรับความสำเร็จของ DeepSeek ดัชนี Hang Seng Tech เพิ่มขึ้นก่อนปีใหม่ทางจันทรคติ ซึ่งสะท้อนให้เห็นว่า การมองโลกในแง่ดีเกี่ยวกับการปรากฏตัวที่เพิ่มขึ้นของจีนในด้านนวัตกรรม AI
มิติทางภูมิศาสตร์การเมือง: การคว่ำบาตรและนวัตกรรม
การเพิ่มขึ้นของ DeepSeek คือ การตอบสนองโดยตรงต่อการควบคุมการส่งออกของสหรัฐฯ ที่ออกแบบมาเพื่อจำกัดการเข้าถึงเทคโนโลยีขั้นสูงของจีน ตั้งแต่ปี 2021 ข้อจำกัดเหล่านี้มีเป้าหมายเพื่อป้องกันการพัฒนาระบบ AI ที่สามารถแข่งขันได้ในประเทศจีน โดยการจำกัดการเข้าถึงฮาร์ดแวร์ที่ล้ำสมัย
อย่างไรก็ตาม การใช้ GPU H800 อย่างมีไหวพริบของ DeepSeek ได้แสดงให้เห็นว่านวัตกรรมสามารถเจริญเติบโตได้แม้อยู่ภายใต้ความเข้มงวดที่เข้มงวด ข้อจำกัด
กลยุทธ์ของ Liang ในการเก็บสะสม GPU ที่ถูกจำกัดก่อนที่มาตรการคว่ำบาตรจะมีผลเต็มที่ถือเป็นหัวใจสำคัญ ด้วยการมุ่งเน้นไปที่ประสิทธิภาพมากกว่าพลังการคำนวณที่ดุร้าย วิศวกรของ DeepSeek ได้แสดงให้เห็นว่าข้อจำกัดสามารถขับเคลื่อนการแก้ปัญหาอย่างสร้างสรรค์ได้อย่างไร
Yann LeCun หัวหน้านักวิทยาศาสตร์ AI ของ Meta ยกย่องหลักการโอเพ่นซอร์สที่อยู่เบื้องหลังการพัฒนาของ R1 โดยระบุว่า:”DeepSeek ได้รับประโยชน์จากการวิจัยแบบเปิดและโอเพ่นซอร์ส (เช่น PyTorch และ Llama จาก Meta) พวกเขาเกิดแนวคิดใหม่ๆ และสร้างขึ้นมาจากงานของผู้อื่น”
ผลกระทบต่อบริษัทยักษ์ใหญ่ด้านเทคโนโลยีของสหรัฐฯ
ความสำเร็จของโมเดล R1 ของ DeepSeek ก่อให้เกิด คำถามที่ไม่สบายใจสำหรับผู้นำด้านเทคโนโลยีของสหรัฐอเมริกาเช่น Meta และ Microsoft ซึ่งลงทุนหลายพันล้านในโครงสร้างพื้นฐาน AI Mark Zuckerberg เมื่อเร็ว ๆ นี้สรุปแผนการอันทะเยอทะยานของบริษัทในการปรับใช้ GPU มากกว่า 1.3 ล้านตัวใน ปี 2025 โดยระบุว่า”เรากำลังวางแผนที่จะลงทุน 60-65 พันล้านดอลลาร์ในฝ่ายทุนในปีนี้ ในขณะเดียวกันก็ทำให้ทีม AI ของเราเติบโตอย่างมีนัยสำคัญ และเรามีเงินทุนสำหรับการลงทุนต่อไปในปีต่อๆ ไป”
ยุคใหม่ของนวัตกรรม AI
ความมุ่งมั่นของ DeepSeek ในการทำงานร่วมกันแบบโอเพ่นซอร์สทำให้ DeepSeek แตกต่างจากยักษ์ใหญ่ในอุตสาหกรรม ด้วยการเผยแพร่สถาปัตยกรรมและวิธีการฝึกอบรมของ R1 บริษัทได้ช่วยให้นักพัฒนาทั่วโลกสามารถทำซ้ำหรือปรับปรุงงานของตนได้
ความโปร่งใสนี้ตรงกันข้ามกับธรรมชาติที่เป็นกรรมสิทธิ์ของแพลตฟอร์ม เช่น ChatGPT ของ OpenAI โดยเน้นถึงการเปลี่ยนแปลงที่อาจเกิดขึ้นไปสู่นวัตกรรม AI ที่เข้าถึงได้มากขึ้น
ความสำเร็จของ DeepSeek เป็นเครื่องเตือนใจว่าความเป็นผู้นำทางเทคโนโลยีไม่ได้ถูกกำหนดโดยเพียงอย่างเดียว ทรัพยากรทางการเงิน ไม่ว่าจะเป็นจุดสิ้นสุดของฟองสบู่ตลาดหุ้นเทคโนโลยีในสหรัฐฯ หรือบทใหม่ในการแข่งขัน AI ระดับโลก สิ่งหนึ่งที่ชัดเจน: กฎของเกมกำลังเปลี่ยนแปลง