คดีที่ยื่นในศาลรัฐบาลกลางแคลิฟอร์เนียกล่าวหาว่า LinkedIn ละเมิดข้อตกลงความเป็นส่วนตัวโดยการแบ่งปันข้อความส่วนตัวและข้อมูลส่วนบุคคลจากสมาชิกระดับพรีเมียมเพื่อฝึกโมเดลปัญญาประดิษฐ์ (AI)
คดีความ อ้างว่าบริษัทที่ Microsoft เป็นเจ้าของละเมิด ที่จัดเก็บ พระราชบัญญัติการสื่อสาร (SCA) กฎหมายการแข่งขันที่ไม่เป็นธรรมระดับรัฐ และข้อผูกพันตามสัญญาของตนเองต่อสมาชิก
โจทก์ Alessandro De La Torre เป็นตัวแทนของกลุ่มผู้ใช้ที่ได้รับผลกระทบหลายล้านรายซึ่งส่วนใหญ่เป็นสมาชิกระดับพรีเมียม ซึ่งไว้วางใจ LinkedIn เพื่อปกป้องความลับของการสื่อสารของพวกเขา
ข้อกล่าวหามุ่งเน้นไปที่ การแนะนำของ LinkedIn การตั้งค่าความเป็นส่วนตัวใหม่ในปี 2024 ซึ่งโจทก์โต้แย้งว่าอนุญาตให้แพลตฟอร์มนำข้อมูลผู้ใช้ไปใช้ใหม่อย่างเงียบๆ โดยไม่ได้รับความยินยอมอย่างชัดแจ้ง
คดีดังกล่าวระบุว่าแนวทางปฏิบัติเหล่านี้ส่งผลให้เกิดการละเมิดความไว้วางใจ ส่งผลให้ผู้ใช้เสี่ยงต่อการนำข้อมูลที่ละเอียดอ่อนไปใช้ในทางที่ผิด ตามการยื่นฟ้อง พฤติกรรมของ LinkedIn ไม่เพียงแต่ละเมิดภาระผูกพันตามสัญญาเท่านั้น แต่ยังบ่อนทำลายหลักการทางจริยธรรมของการพัฒนา AI ด้วย
การตั้งค่าความเป็นส่วนตัวและการอัปเดตนโยบายที่เป็นข้อขัดแย้ง
การโต้เถียงมีศูนย์กลางอยู่ที่การตั้งค่าความเป็นส่วนตัว LinkedIn ที่เปิดตัวในเดือนสิงหาคม 2024 ฟีเจอร์นี้ชื่อ “ข้อมูลสำหรับการปรับปรุง Generative AI” อนุญาตให้ LinkedIn และบริษัทในเครือ รวมถึง Microsoft ประมวลผลข้อมูลผู้ใช้สำหรับการฝึกอบรม AI โมเดล
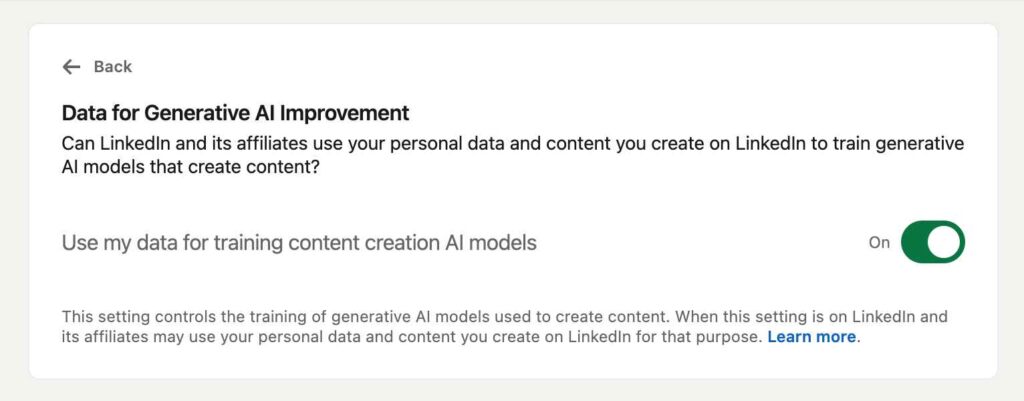 การตั้งค่า “ข้อมูลสำหรับการปรับปรุง AI แบบทั่วไป”ของ Linkedin
การตั้งค่า “ข้อมูลสำหรับการปรับปรุง AI แบบทั่วไป”ของ Linkedin
การตั้งค่านี้ถูกเปิดใช้งานตามค่าเริ่มต้น โดยเลือกผู้ใช้ทั้งหมดให้เข้าร่วมโปรแกรมอย่างมีประสิทธิภาพ เว้นแต่พวกเขาจะปิดการใช้งานด้วยตนเอง คดีดังกล่าวเน้นย้ำว่าการอัปเดตนโยบายของ LinkedIn ไม่ได้แจ้งให้ผู้ใช้ทราบอย่างเพียงพอเกี่ยวกับผลกระทบของกลไกการแบ่งปันข้อมูลนี้
ในเดือนกันยายน 2024 หลังจากการตรวจสอบข้อเท็จจริงต่อสาธารณะและรายงานของสื่อ LinkedIn ได้อัปเดตนโยบายความเป็นส่วนตัวเพื่อระบุอย่างชัดเจนถึงส่วนบุคคลนั้น ข้อมูลสามารถนำมาใช้สำหรับการฝึกอบรม AI เชิงสร้างสรรค์ได้ การอัปเดตยังชี้แจงด้วยว่าผู้ใช้ที่เลือกไม่เข้าร่วมสามารถป้องกันการแบ่งปันข้อมูลในอนาคตเท่านั้น ข้อมูลที่รวบรวมไว้แล้วจะยังคงฝังอยู่ในโมเดล AI
คำถามที่พบบ่อยที่แก้ไขแล้วของ LinkedIn เปิดเผยแล้ว: “การเลือกไม่รับหมายความว่า LinkedIn และบริษัทในเครือ จะไม่ใช้ข้อมูลส่วนบุคคลหรือเนื้อหาของคุณบน LinkedIn เพื่อฝึกโมเดลในอนาคต แต่ไม่ส่งผลกระทบต่อการฝึกอบรมที่เกิดขึ้นแล้ว”
การเปิดเผยเหล่านี้ชี้ให้เห็นว่าการควบคุมข้อมูลของผู้ใช้ถูกจำกัดอย่างดีที่สุด คดีดังกล่าวกล่าวหาว่า LinkedIn ไม่สามารถแจ้งให้ทราบอย่างเพียงพอเกี่ยวกับการเปลี่ยนแปลงเหล่านี้ ซึ่งเป็นการละเมิดนโยบายของตนเองที่จำเป็นต้องมีการสื่อสารการอัปเดตที่สำคัญล่วงหน้า และเปิดโอกาสให้ผู้ใช้ยกเลิกบัญชีของตนได้
พื้นฐานทางกฎหมายสำหรับ การร้องเรียน
โจทก์โต้แย้งว่า LinkedIn ละเมิด SCA ซึ่งห้ามมิให้ผู้ให้บริการการสื่อสารทางอิเล็กทรอนิกส์เปิดเผยเนื้อหาการสื่อสารของผู้ใช้โดยเจตนาโดยไม่ได้รับอนุญาต
คดีดังกล่าวกล่าวหาว่า LinkedIn ละเมิดกฎหมายนี้โดยการแบ่งปันข้อความ InMail ส่วนตัว— มีให้เฉพาะสำหรับสมาชิก Premium ที่ชำระเงินกับบุคคลที่สาม รวมถึงบริษัทในเครือของ Microsoft และผู้ให้บริการที่ไม่ระบุชื่ออื่นๆ เพื่อวัตถุประสงค์ในการฝึกอบรมโมเดล AI
การร้องเรียนยังยืนยันว่า LinkedIn ละเมิดข้อตกลงการสมัครสมาชิก (LSA) และข้อตกลงการปกป้องข้อมูล (DPA) ซึ่งสัญญาว่าจะปรับปรุงการปกป้องความเป็นส่วนตัวสำหรับผู้ใช้ระดับพรีเมียม ส่วนที่ 3.2 ของ LSA ห้ามมิให้แบ่งปันข้อมูลผู้ใช้ที่เป็นความลับโดยไม่ได้รับความยินยอมอย่างชัดเจน
คดีดังกล่าวระบุว่า: “LinkedIn ละเมิดสัญญาโดยการเปิดเผยข้อความส่วนตัวของลูกค้าระดับพรีเมียมไปยังบุคคลที่สามเพื่อฝึกอบรมโมเดลปัญญาประดิษฐ์เชิงกำเนิด (‘AI’)”
นอกจากนี้ โจทก์อ้างว่า LinkedIn มีส่วนร่วมในการดำเนินธุรกิจที่ไม่เป็นธรรมภายใต้กฎหมายแคลิฟอร์เนียโดยทำให้ผู้ใช้เข้าใจผิดเกี่ยวกับแนวทางปฏิบัติในการแบ่งปันข้อมูล
คณะกรรมาธิการการค้าของรัฐบาลกลาง (FTC) เตือนก่อนหน้านี้เกี่ยวกับการเปลี่ยนแปลงนโยบายความเป็นส่วนตัวย้อนหลังดังกล่าว โดยระบุในปี 2024: “บริษัทอาจไม่ยุติธรรมหรือหลอกลวงมากขึ้น แนวปฏิบัติด้านข้อมูลที่อนุญาต…ผ่านการแก้ไขข้อกำหนดในการให้บริการหรือนโยบายความเป็นส่วนตัวแบบแอบแฝงและมีผลย้อนหลัง”
ผลกระทบต่อสมาชิกระดับพรีเมียม
คดีมุ่งเน้นไปที่ สมาชิกระดับพรีเมียมที่ชำระค่าฟีเจอร์ เช่น InMail และการวิเคราะห์ขั้นสูง ผู้ใช้เหล่านี้มีสิทธิ์ได้รับการรับประกันความเป็นส่วนตัวเพิ่มเติมภายใต้ข้อกำหนดของแพลตฟอร์ม
ตามคำร้องเรียน ข้อความ InMail มักจะมีข้อมูลที่ละเอียดอ่อนที่เกี่ยวข้องกับการจ้างงาน ทรัพย์สินทางปัญญา และค่าตอบแทน การเปิดเผยข้อมูลนี้โดยไม่ได้รับอนุญาตไม่เพียงแต่เป็นการละเมิดความไว้วางใจของผู้ใช้ แต่ยังทำให้บุคคลมีความเสี่ยง เช่น ความเสียหายต่อชื่อเสียงหรือการขโมยข้อมูลระบุตัวตน
ตัวอย่างหนึ่งจากการยื่นอธิบายว่าข้อความ InMail ของโจทก์มีการอภิปรายเกี่ยวกับการเริ่มต้นทางการเงินและ ความพยายามในการหางานที่เป็นความลับ โจทก์กล่าวหาว่า: “การเปิดเผยดังกล่าวอาจเป็นอันตรายต่อความสัมพันธ์ทางอาชีพอย่างไม่อาจแก้ไขได้ ทำลายโอกาสในการทำงาน และเป็นอันตรายต่อความได้เปรียบทางการแข่งขันของบริษัทและบุคคล”
ผลกระทบในวงกว้างสำหรับ Microsoft
ในฐานะบริษัทแม่ของ LinkedIn Microsoft มีบทบาทสำคัญในข้อกล่าวหาของคดีนี้ ข้อมูลผู้ใช้จาก LinkedIn อาจปรากฏในระบบนิเวศของ Microsoft รวมถึงในผลิตภัณฑ์เช่น Word, Teams และ Excel
สิ่งนี้ทำให้เกิดความกังวลเกี่ยวกับการละเมิดความเป็นส่วนตัวโดยไม่ได้ตั้งใจ เช่น การหางานที่เป็นความลับที่ปรากฏในการเติมข้อมูลอัตโนมัติของ Teams หรือกลยุทธ์ทางธุรกิจที่อนุมานอยู่ในคำแนะนำของ Word
คดีชี้ให้เห็น: “ ข้อมูลส่วนตัวอาจปรากฏในผลิตภัณฑ์ของ Microsoft เช่น การค้นหางานที่ปรากฏในการเติมข้อความอัตโนมัติของ Word แผนธุรกิจในคำแนะนำการแชทของ Teams หรือเนื้อหาที่เกี่ยวข้องกับเงินเดือนในฟีเจอร์ของ Excel”
ตามภูมิศาสตร์ ความแตกต่างและช่องว่างด้านกฎระเบียบ
คดีดังกล่าวเน้นย้ำถึงความแตกต่างในแนวทางปฏิบัติในการแบ่งปันข้อมูลของ LinkedIn ตามสถานที่ตั้งทางภูมิศาสตร์ ผู้ใช้ในภูมิภาคที่มีกฎระเบียบความเป็นส่วนตัวที่เข้มงวดมากขึ้น เช่น สหภาพยุโรป แคนาดา และสวิตเซอร์แลนด์ ได้รับการยกเว้นจากหลักปฏิบัติในการแบ่งปันข้อมูลเหล่านี้ ในทางตรงกันข้าม ผู้ใช้ในสหรัฐฯ ซึ่งขาดการคุ้มครองความเป็นส่วนตัวของรัฐบาลกลางอย่างครอบคลุม จะต้องอยู่ภายใต้การตั้งค่าการเลือกใช้เริ่มต้น
การเยียวยาและข้อกังวลด้านจริยธรรม
โจทก์ กำลังมองหาค่าเสียหายตามกฎหมายจำนวน 1,000 ดอลลาร์ต่อผู้ใช้ภายใต้ SCA พร้อมด้วยค่าชดเชยสำหรับค่าธรรมเนียมการสมัครสมาชิกที่ชำระเกิน นอกจากนี้ พวกเขาต้องการ”การแบ่งแยกอัลกอริทึม”ซึ่งเป็นการเยียวยาทางกฎหมายที่กำหนดให้ LinkedIn ลบโมเดล AI และอัลกอริทึมที่ได้รับการฝึกอบรมเกี่ยวกับข้อมูลที่ได้รับอย่างไม่เหมาะสม
คดีดังกล่าวทำให้เกิดคำถามทางจริยธรรมเกี่ยวกับการใช้ข้อมูลส่วนบุคคลในการพัฒนา AI นักวิจารณ์แย้งว่า แนวทางปฏิบัติดังกล่าวกัดกร่อนความไว้วางใจของสาธารณชน และสร้างความเสี่ยงในการจัดทำโปรไฟล์ การเลือกปฏิบัติ และการขโมยข้อมูลระบุตัวตน คดีนี้มีผลกระทบในวงกว้างต่ออุตสาหกรรมเทคโนโลยี ซึ่งถือเป็นตัวอย่างที่เป็นไปได้สำหรับวิธีที่บริษัทต่างๆ สร้างสมดุลระหว่างนวัตกรรม AI ความเป็นส่วนตัวของผู้ใช้