ห้องแล็บปัญญาประดิษฐ์ของจีน DeepSeek ได้เปิดตัว DeepSeek V3 ซึ่งเป็นโมเดลภาษาจากแหล่งจีโนเพนตัวถัดไป โมเดลนี้มีพารามิเตอร์ถึง 6.71 แสนล้านพารามิเตอร์ ใช้สถาปัตยกรรมที่เรียกว่า Mixture-of-Experts (MoE) เพื่อรวมประสิทธิภาพการคำนวณเข้ากับประสิทธิภาพสูง
ความก้าวหน้าทางเทคนิคของ DeepSeek V3 จัดให้เป็นหนึ่งในระบบ AI ที่ทรงพลังที่สุดในการเทียบเคียง ทั้งคู่แข่งโอเพ่นซอร์สเช่น Llama 3.1 ของ Meta และรุ่นที่เป็นกรรมสิทธิ์เช่น GPT-4o ของ OpenAI
การเปิดตัวครั้งนี้เน้นย้ำถึงช่วงเวลาสำคัญใน AI ซึ่งแสดงให้เห็นว่าระบบโอเพ่นซอร์สสามารถทำได้ แข่งขันกับ—และในบางกรณีก็มีประสิทธิภาพเหนือกว่า—ทางเลือกอื่นที่มีราคาแพงกว่าและปิด
ที่เกี่ยวข้อง:
โมเดล DeepSeek R1-Lite-Preview ของจีนตั้งเป้าเป็นผู้นำของ OpenAI ในด้านการใช้เหตุผลอัตโนมัติ
Alibaba Qwen เปิดตัวโมเดล AI การใช้เหตุผลหลายรูปแบบ QVQ-72B-ดูตัวอย่าง
สถาปัตยกรรมที่มีประสิทธิภาพและเป็นนวัตกรรม
สถาปัตยกรรมของ DeepSeek V3 ผสมผสานแนวคิดขั้นสูงสองประการเข้าด้วยกัน เพื่อให้บรรลุประสิทธิภาพและประสิทธิภาพที่ยอดเยี่ยม: Multi-Head Latent Attention (MLA) และ Mixture-of-Experts (MoE)
MLA ปรับปรุง ความสามารถของโมเดลในการประมวลผลอินพุตที่ซับซ้อนโดยใช้หัวความสนใจหลายอันเพื่อมุ่งเน้นไปที่แง่มุมที่แตกต่างกันของข้อมูล โดยดึงข้อมูลบริบทที่หลากหลายและหลากหลาย
ในทางกลับกัน MoE จะเปิดใช้งานเพียงชุดย่อยของจำนวนรวม 671 ของโมเดล พารามิเตอร์นับพันล้าน-ประมาณ 37 พันล้านต่องาน-ทำให้มั่นใจได้ว่าทรัพยากรการคำนวณจะถูกใช้อย่างมีประสิทธิภาพโดยไม่กระทบต่อความแม่นยำ กลไกเหล่านี้ร่วมกันช่วยให้ DeepSeek V3 สามารถส่งมอบผลลัพธ์คุณภาพสูงในขณะที่ลดความต้องการด้านโครงสร้างพื้นฐาน
เพื่อจัดการกับความท้าทายทั่วไปในระบบ MoE เช่น การกระจายปริมาณงานที่ไม่สม่ำเสมอในหมู่ผู้เชี่ยวชาญ DeepSeek ได้เปิดตัวระบบเสริมที่ปราศจากการสูญเสีย กลยุทธ์การสร้างสมดุล วิธีการแบบไดนามิกนี้จะจัดสรรงานทั่วทั้งเครือข่ายผู้เชี่ยวชาญ โดยรักษาความสม่ำเสมอและเพิ่มความแม่นยำของงานให้สูงสุด
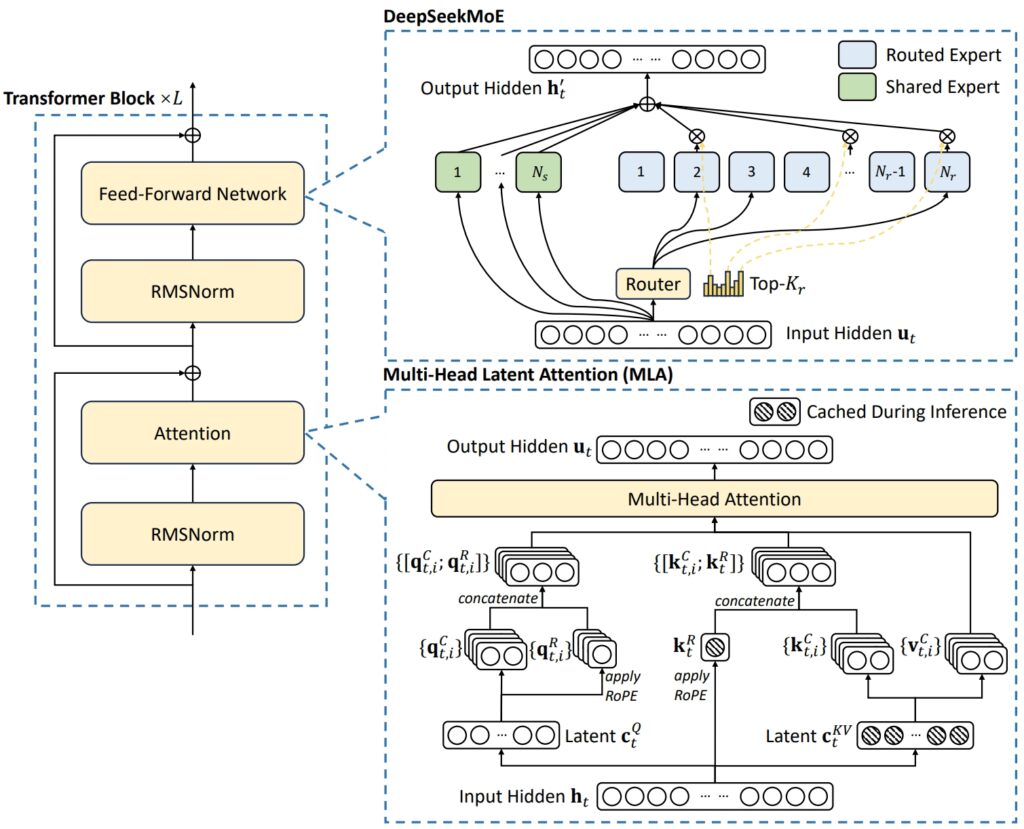 ภาพประกอบสถาปัตยกรรมพื้นฐานของ DeepSeek-V3 (รูปภาพ: DeepSeek)
ภาพประกอบสถาปัตยกรรมพื้นฐานของ DeepSeek-V3 (รูปภาพ: DeepSeek)
เพื่อเพิ่มประสิทธิภาพให้ดียิ่งขึ้น DeepSeek V3 ใช้ Multi-Token การคาดการณ์ (MTP) ซึ่งเป็นฟีเจอร์ที่ช่วยให้โมเดลสร้างโทเค็นหลายรายการพร้อมกัน ซึ่งช่วยเร่งการสร้างข้อความได้อย่างมาก
ฟีเจอร์นี้ไม่เพียงแต่ปรับปรุงประสิทธิภาพการฝึกเท่านั้น แต่ยังวางตำแหน่งโมเดลเพื่อการใช้งานจริงที่รวดเร็วยิ่งขึ้นอีกด้วย ซึ่งตอกย้ำ ยืนหยัดเป็นผู้นำในนวัตกรรม AI แบบโอเพ่นซอร์ส
ประสิทธิภาพเกณฑ์มาตรฐาน: ผู้นำในด้านคณิตศาสตร์และการเขียนโค้ด
ผลลัพธ์เกณฑ์มาตรฐานของ DeepSeek V3 แสดงให้เห็นถึงความสามารถที่โดดเด่นในด้านต่างๆ ก งานที่หลากหลาย เสริมความแข็งแกร่งในฐานะผู้นำในโมเดล AI แบบโอเพ่นซอร์ส
ด้วยการใช้ประโยชน์จากสถาปัตยกรรมขั้นสูงและชุดข้อมูลการฝึกอบรมที่ครอบคลุม โมเดลดังกล่าวได้รับประสิทธิภาพระดับสูงสุดในด้านคณิตศาสตร์ การเขียนโค้ด และการวัดประสิทธิภาพในหลายภาษา ขณะเดียวกันก็นำเสนอผลลัพธ์การแข่งขันในพื้นที่ที่แต่ก่อนถูกครอบงำโดยโมเดลแบบปิด เช่น GPT ของ OpenAI-4o และ Claude 3.5 Sonnet ของ Anthropic
🚀 ขอแนะนำ DeepSeek-V3!
ก้าวกระโดดครั้งใหญ่ที่สุด ยัง:
⚡ 60 โทเค็น/วินาที (เร็วกว่า V2 ถึง 3 เท่า!)
💪 ความสามารถที่ได้รับการปรับปรุง
🛠 ความเข้ากันได้ของ API ไม่เสียหาย
🌍 โมเดลและเอกสารโอเพ่นซอร์สเต็มรูปแบบ🐋 1/n pic.twitter.com/p1dV9gJ2Sd
— DeepSeek (@deepseek_ai) 26 ธันวาคม 2024
การใช้เหตุผลทางคณิตศาสตร์
เกี่ยวกับ การทดสอบ Math-500 ซึ่งเป็นเกณฑ์มาตรฐานที่ออกแบบมาเพื่อประเมินทักษะการแก้ปัญหาทางคณิตศาสตร์ DeepSeek V3 ได้คะแนนที่น่าประทับใจถึง 90.2 คะแนนนี้แซงหน้าคู่แข่งโอเพ่นซอร์สทั้งหมด โดย Qwen 2.5 ได้คะแนน 80 และ Llama 3.1 ตามหลังที่ 73.8 แม้แต่ GPT-4o ซึ่งเป็นโมเดลโอเพนซอร์ซที่โด่งดังในด้านความสามารถทั่วไป ก็ยังมีคะแนนต่ำกว่าเล็กน้อยที่ 74.6 ประสิทธิภาพนี้ตอกย้ำความสามารถในการให้เหตุผลขั้นสูงของ DeepSeek V3 โดยเฉพาะอย่างยิ่งในงานที่ต้องใช้การคำนวณสูงซึ่งความแม่นยำและตรรกะเป็นสิ่งสำคัญ
นอกจากนี้ DeepSeek V3 ยังความเป็นเลิศในการทดสอบเฉพาะทางคณิตศาสตร์อื่นๆ เช่น:
MGSM (คณิตศาสตร์ระดับประถมศึกษา): คะแนน 79.8 แซงหน้า Llama 3.1 (69.9) และ Qwen 2.5 (76.2) CMath (คณิตศาสตร์จีน): ได้คะแนน 90.7 เหนือกว่าทั้ง Llama 3.1 (77.3) และ GPT-4o (84.5)
ผลลัพธ์เหล่านี้เน้นย้ำถึงจุดแข็งที่ไม่เพียงแต่ ในการให้เหตุผลทางคณิตศาสตร์เป็นภาษาอังกฤษ แต่ยังในงานที่ต้องใช้การแก้ปัญหาเชิงตัวเลขเฉพาะภาษาด้วย
ที่เกี่ยวข้อง: ซีรีส์ DeepSeek AI Open Sources VL2 Series ของโมเดลภาษาวิชั่น
การเขียนโปรแกรมและการเขียนโค้ด
DeepSeek V3 แสดงให้เห็นอย่างน่าทึ่ง ความสามารถในการเขียนโค้ดและการวัดประสิทธิภาพการแก้ปัญหา ใน Codeforces ซึ่งเป็นแพลตฟอร์มการเขียนโปรแกรมที่มีการแข่งขัน โมเดลดังกล่าวได้รับการจัดอันดับที่ 51.6 เปอร์เซ็นต์ ซึ่งสะท้อนถึงความสามารถในการจัดการงานอัลกอริทึมที่ซับซ้อน ประสิทธิภาพนี้แซงหน้าคู่แข่งโอเพ่นซอร์สอย่าง Llama 3.1 ซึ่งได้คะแนนเพียง 25.3 อย่างมาก และยังท้าทาย Claude 3.5 Sonnet ซึ่งมีเปอร์เซ็นไทล์ที่ต่ำกว่าอีกด้วย ความสำเร็จของโมเดลนี้ได้รับการตรวจสอบเพิ่มเติมด้วยคะแนนสูงสุดในเกณฑ์มาตรฐานเฉพาะการเขียนโค้ด:
HumanEval-Mul: ได้คะแนน 82.6 เหนือกว่า Qwen 2.5 (77.3) และตรงกับ GPT-4o (80.5) LiveCodeBench (Pass@1): ได้คะแนน 37.6 นำหน้า Llama 3.1 (30.1) และ Claude 3.5 Sonnet (32.8) CRUXEval-I: ได้คะแนน 67.3 ดีกว่าทั้ง Qwen 2.5 (59.1) และ Llama 3.1 (58.5) อย่างเห็นได้ชัด
ผลลัพธ์เหล่านี้เน้นย้ำถึงความเหมาะสมของโมเดลสำหรับแอปพลิเคชันในการพัฒนาซอฟต์แวร์และสภาพแวดล้อมการเขียนโค้ดในโลกแห่งความเป็นจริง ซึ่งการแก้ปัญหาและการสร้างโค้ดอย่างมีประสิทธิภาพเป็นสิ่งสำคัญยิ่ง
งานหลายภาษาและไม่ใช่ภาษาอังกฤษ
strong>
DeepSeek V3 ยังโดดเด่นในด้านการวัดประสิทธิภาพหลายภาษา โดยแสดงให้เห็นถึงความสามารถในการประมวลผลและเข้าใจภาษาที่หลากหลาย ในการทดสอบ CMMLU (การทำความเข้าใจภาษาจีนหลายภาษา) โมเดลดังกล่าวได้คะแนนโดดเด่นที่ 88.8 แซงหน้า Qwen 2.5 (89.5) และเหนือกว่า Llama 3.1 ซึ่งตามหลังที่ 73.7 ในทำนองเดียวกัน ใน C-Eval ซึ่งเป็นเกณฑ์มาตรฐานการประเมินของจีน นั้น DeepSeek V3 ได้คะแนน 90.1 ซึ่งเหนือกว่า Llama 3.1 (72.5)
ในงานหลายภาษาที่ไม่ใช่ภาษาอังกฤษ:
เกณฑ์มาตรฐานเฉพาะภาษาอังกฤษ
ในขณะที่ DeepSeek V3 เป็นเลิศในด้านคณิตศาสตร์ การเขียนโค้ด และ ประสิทธิภาพหลายภาษา ผลลัพธ์ในเกณฑ์มาตรฐานเฉพาะภาษาอังกฤษบางรายการสะท้อนถึงสิ่งที่ต้องปรับปรุง ตัวอย่างเช่น ในเกณฑ์มาตรฐาน SimpleQA ซึ่งประเมินความสามารถของโมเดลในการตอบคำถามข้อเท็จจริงที่ตรงไปตรงมาในภาษาอังกฤษ DeepSeek V3 ได้คะแนน 24.9 ซึ่งตามหลัง GPT-4o ซึ่งทำได้ 38.2 ใน FRAMES ซึ่งเป็นเกณฑ์มาตรฐานสำหรับการทำความเข้าใจโครงสร้างการเล่าเรื่องที่ซับซ้อน GPT-4o ได้คะแนน 80.5 เทียบกับ DeepSeek ที่ 73.3
แม้ว่าจะมีช่องว่างเหล่านี้ แต่ประสิทธิภาพของโมเดลยังคงมีการแข่งขันสูง โดยเฉพาะอย่างยิ่งเมื่อพิจารณาจากลักษณะของโอเพ่นซอร์สและความคุ้มค่าด้านต้นทุน ประสิทธิภาพที่ต่ำกว่าเล็กน้อยในงานเฉพาะภาษาอังกฤษถูกชดเชยด้วยการครอบงำในการวัดประสิทธิภาพทางคณิตศาสตร์และหลายภาษา ซึ่งเป็นส่วนที่ท้าทายอย่างต่อเนื่องและมักจะเหนือกว่าคู่แข่งที่มาจากแหล่งปิด
ผลลัพธ์ของการวัดประสิทธิภาพ DeepSeek V3 ไม่เพียงแต่แสดงให้เห็นถึงความซับซ้อนทางเทคนิคเท่านั้น แต่ยัง ยังวางตำแหน่งให้เป็นโมเดลอเนกประสงค์และประสิทธิภาพสูงสำหรับงานที่หลากหลาย ความเหนือกว่าในด้านคณิตศาสตร์ การเขียนโค้ด และเกณฑ์มาตรฐานหลายภาษาเน้นย้ำถึงจุดแข็ง ในขณะที่ผลการแข่งขันในงานภาษาอังกฤษแสดงให้เห็นถึงความสามารถในการแข่งขันกับผู้นำในอุตสาหกรรม เช่น GPT-4o และ Claude 3.5 Sonnet
ด้วยการนำเสนอผลลัพธ์เหล่านี้ในราคาเพียงเศษเสี้ยวของต้นทุนที่เกี่ยวข้องกับระบบที่เป็นกรรมสิทธิ์ DeepSeek V3 แสดงให้เห็นถึงศักยภาพของ AI แบบโอเพ่นซอร์สที่จะแข่งขันได้ และในบางกรณีก็มีประสิทธิภาพเหนือกว่าทางเลือกอื่นแบบปิด
ที่เกี่ยวข้อง: Apple วางแผนเปิดตัว AI ในประเทศจีนผ่าน Tencent และ ByteDance
การฝึกอบรมที่คุ้มค่าที่ ปรับขนาด
หนึ่งในความสำเร็จที่โดดเด่นของ DeepSeek V3 คือกระบวนการฝึกอบรมที่คุ้มค่า โมเดลดังกล่าวได้รับการฝึกฝนบนชุดข้อมูล 14.8 ล้านล้านโทเค็นโดยใช้ GPU Nvidia H800 โดยมีเวลาการฝึกอบรมรวม 2.788 ล้านชั่วโมง GPU ค่าใช้จ่ายโดยรวมอยู่ที่ 5.576 ล้านดอลลาร์ ซึ่งเป็นเศษเสี้ยวของค่าใช้จ่ายประมาณ 500 ล้านดอลลาร์ที่จำเป็นสำหรับการฝึก Meta’s Llama 3.1
NVIDIA H800 GPU เป็นเวอร์ชันดัดแปลงของ H100 GPU ที่ออกแบบมาสำหรับตลาดจีนเพื่อให้สอดคล้องกับการส่งออก กฎระเบียบ GPU ทั้งสองใช้สถาปัตยกรรม Hopper ของ NVIDIA และใช้สำหรับ AI และแอปพลิเคชันการประมวลผลประสิทธิภาพสูงเป็นหลัก อัตราการถ่ายโอนข้อมูลแบบชิปต่อชิปของ H800 ลดลงเหลือประมาณครึ่งหนึ่งของ H100
กระบวนการฝึกอบรมใช้วิธีการขั้นสูง รวมถึงการฝึกอบรมแบบผสมความแม่นยำแบบ FP8 วิธีการนี้จะช่วยลดการใช้หน่วยความจำโดยการเข้ารหัสข้อมูลในรูปแบบจุดลอยตัว 8 บิตโดยไม่ทำให้ความแม่นยำลดลง นอกจากนี้ อัลกอริธึม DualPipe ยังเพิ่มประสิทธิภาพการขนานไปป์ไลน์ เพื่อให้มั่นใจว่าการประสานงานระหว่างคลัสเตอร์ GPU จะราบรื่น
DeepSeek กล่าวว่าการฝึกอบรมล่วงหน้า DeepSeek-V3 ต้องใช้เวลาเพียง 180,000 H800 GPU ชั่วโมงต่อล้านล้านโทเค็น โดยใช้คลัสเตอร์ 2,048 GPU
การเข้าถึงและการปรับใช้
DeepSeek ทำให้ V3 พร้อมใช้งานภายใต้ใบอนุญาต MIT ช่วยให้นักพัฒนาสามารถเข้าถึงโมเดลสำหรับแอปพลิเคชันการวิจัยและเชิงพาณิชย์ องค์กรต่างๆ สามารถบูรณาการโมเดลผ่านแพลตฟอร์มหรือ API ของ DeepSeek Chat ซึ่งมีราคาที่สามารถแข่งขันได้ที่ 0.27 ดอลลาร์ต่อโทเค็นอินพุตหนึ่งล้านรายการ และ 1.10 ดอลลาร์ต่อล้านโทเค็นเอาท์พุต
ความสามารถรอบด้านของโมเดลขยายไปถึงความเข้ากันได้กับแพลตฟอร์มฮาร์ดแวร์ต่างๆ รวมถึง AMD GPU และ Huawei Ascend NPU สิ่งนี้ทำให้มั่นใจได้ถึงการเข้าถึงในวงกว้างสำหรับนักวิจัยและองค์กรที่มีความต้องการโครงสร้างพื้นฐานที่หลากหลาย
DeepSeek เน้นย้ำถึงการมุ่งเน้นไปที่ความน่าเชื่อถือและประสิทธิภาพ โดยระบุว่า”เพื่อให้มั่นใจว่าปฏิบัติตาม SLO และปริมาณงานที่สูง เราใช้กลยุทธ์การสำรองข้อมูลแบบไดนามิกสำหรับผู้เชี่ยวชาญในระหว่างขั้นตอนการบรรจุล่วงหน้า ซึ่งผู้เชี่ยวชาญที่มีภาระงานสูงจะถูกทำซ้ำและจัดเรียงใหม่เป็นระยะๆ เพื่อประสิทธิภาพสูงสุด”
ผลกระทบที่กว้างขึ้นสำหรับระบบนิเวศ AI
การเปิดตัว DeepSeek V3 ตอกย้ำแนวโน้มที่กว้างขึ้นต่อ การทำให้เป็นประชาธิปไตยของ AI ด้วยการนำเสนอโมเดลประสิทธิภาพสูงด้วยต้นทุนเพียงเล็กน้อยที่เกี่ยวข้องกับระบบที่เป็นกรรมสิทธิ์ DeepSeek กำลังท้าทายการครอบงำของผู้เล่นแบบปิดเช่น OpenAI และ Anthropic ความพร้อมใช้งานของเครื่องมือขั้นสูงดังกล่าวช่วยให้สามารถทดลองและสร้างสรรค์นวัตกรรมได้กว้างขึ้น อุตสาหกรรม
ไปป์ไลน์ของ DeepSeek รวมรูปแบบการตรวจสอบและการสะท้อนกลับจากโมเดล R1 ลงใน DeepSeek-V3 ซึ่งปรับปรุงความสามารถในการให้เหตุผลในขณะที่ยังคงควบคุมรูปแบบและความยาวของเอาต์พุต
ความสำเร็จของ DeepSeek V3 ทำให้เกิดคำถามเกี่ยวกับความสมดุลแห่งอำนาจในอนาคตในอุตสาหกรรม AI เนื่องจากโมเดลโอเพ่นซอร์สยังคงปิดช่องว่างด้วยระบบที่เป็นกรรมสิทธิ์ โมเดลเหล่านี้จึงมอบทางเลือกที่แข่งขันได้ให้กับองค์กรโดยให้ความสำคัญกับการเข้าถึงและความคุ้มค่า