นักวิจัยที่ Sakana AI ซึ่งเป็นสตาร์ทอัพด้าน AI ในโตเกียว ได้เปิดตัวระบบเพิ่มประสิทธิภาพหน่วยความจำแบบใหม่ที่ช่วยเพิ่มประสิทธิภาพของโมเดลที่ใช้ Transformer รวมถึงโมเดลภาษาขนาดใหญ่ (LLM)
วิธีการ เรียกว่า Neural Attention Memory Models (NAMM) มีให้ใช้งานผ่านโค้ดการฝึกอบรมฉบับเต็มใน GitHub ลดการใช้หน่วยความจำได้ถึง 75% พร้อมปรับปรุงประสิทธิภาพโดยรวม ด้วยการมุ่งเน้นไปที่โทเค็นที่จำเป็นและการลบข้อมูลที่ซ้ำซ้อน NAMM จัดการกับหนึ่งในความท้าทายที่ต้องใช้ทรัพยากรมากที่สุดใน AI สมัยใหม่: การจัดการหน้าต่างบริบทที่ยาว
โมเดลหม้อแปลงซึ่งเป็นแกนหลักของ LLM พึ่งพา”หน้าต่างบริบท”เพื่อประมวลผลข้อมูลอินพุต หน้าต่างบริบทเหล่านี้จัดเก็บ”คู่คีย์-ค่า”(แคช KV) สำหรับทุกโทเค็นในลำดับอินพุต
เมื่อความยาวของหน้าต่างเพิ่มขึ้น—ขณะนี้มีโทเค็นถึงแสนโทเค็น— ต้นทุนการคำนวณพุ่งสูงขึ้น โซลูชันก่อนหน้านี้พยายามลดต้นทุนนี้ผ่านการตัดโทเค็นด้วยตนเองหรือกลยุทธ์การเรียนรู้ แต่มักจะลดประสิทธิภาพลง อย่างไรก็ตาม NAMM ใช้โครงข่ายประสาทเทียมที่ได้รับการฝึกผ่านการเพิ่มประสิทธิภาพเชิงวิวัฒนาการเพื่อทำให้กระบวนการจัดการหน่วยความจำเป็นอัตโนมัติและปรับแต่ง
การเพิ่มประสิทธิภาพหน่วยความจำด้วย NAMM
NAMM วิเคราะห์ค่าความสนใจ สร้างโดย Transformers เพื่อกำหนดความสำคัญของโทเค็น โดยจะประมวลผลค่าเหล่านี้เป็นสเปกโตรแกรม ซึ่งเป็นการแสดงตามความถี่ที่ใช้กันทั่วไปในการประมวลผลเสียงและสัญญาณ เพื่อบีบอัดและแยกคุณลักษณะสำคัญของรูปแบบความสนใจ
จากนั้นข้อมูลนี้จะถูกส่งผ่านโครงข่ายประสาทเทียมน้ำหนักเบาซึ่งกำหนดคะแนนให้กับแต่ละโทเค็น เพื่อตัดสินใจว่าควรเก็บไว้หรือทิ้งไป
Sakana AI เน้นย้ำว่าอัลกอริธึมเชิงวิวัฒนาการขับเคลื่อน NAMM อย่างไร ความสำเร็จ. ต่างจากวิธีการไล่ระดับแบบดั้งเดิม ซึ่งเข้ากันไม่ได้กับการตัดสินใจแบบไบนารี่ เช่น”จดจำ”หรือ”ลืม”การเพิ่มประสิทธิภาพเชิงวิวัฒนาการจะทดสอบซ้ำแล้วซ้ำอีก และปรับปรุงกลยุทธ์หน่วยความจำเพื่อเพิ่มประสิทธิภาพดาวน์สตรีมให้สูงสุด
“วิวัฒนาการเอาชนะความสามารถที่ไม่สร้างความแตกต่างโดยธรรมชาติ ของการดำเนินการจัดการหน่วยความจำของเรา ซึ่งเกี่ยวข้องกับผลลัพธ์แบบ’จดจำ’หรือ’ลืม’แบบไบนารี”นักวิจัยอธิบาย
ผลลัพธ์ที่พิสูจน์แล้วทั่วทั้ง เกณฑ์มาตรฐาน
เพื่อตรวจสอบประสิทธิภาพและประสิทธิภาพของ Neural Attention Memory Models (NAMM) Sakana AI ได้ทำการทดสอบอย่างกว้างขวางเกี่ยวกับเกณฑ์มาตรฐานชั้นนำของอุตสาหกรรมหลายรายการ ซึ่งออกแบบมาเพื่อประเมินการประมวลผลตามบริบทแบบยาวและความสามารถแบบมัลติทาสก์ ผลลัพธ์ดังกล่าวตอกย้ำความสามารถของ NAMM ในการปรับปรุงประสิทธิภาพอย่างมีนัยสำคัญในขณะที่ลดความต้องการหน่วยความจำ ซึ่งพิสูจน์ถึงประสิทธิภาพในกรอบการประเมินที่หลากหลาย
ใน LongBench เกณฑ์มาตรฐานที่สร้างขึ้นโดยเฉพาะเพื่อวัดประสิทธิภาพของแบบจำลองในงานที่มีบริบทยาว ทำให้ NAMM มีความแม่นยำเพิ่มขึ้น 11% เมื่อเทียบกับโมเดลพื้นฐานแบบเต็มบริบท การปรับปรุงนี้ประสบความสำเร็จในขณะที่ลดการใช้หน่วยความจำลง 75% โดยเน้นที่ประสิทธิภาพของวิธีการในการจัดการแคชคีย์-ค่า (KV)
ด้วยการตัดโทเค็นที่เกี่ยวข้องน้อยกว่าอย่างชาญฉลาด NAMM ช่วยให้โมเดลมุ่งเน้นไปที่บริบทที่สำคัญโดยไม่สูญเสียผลลัพธ์ ทำให้เหมาะสำหรับสถานการณ์ที่ต้องใช้อินพุตเพิ่มเติม เช่น การวิเคราะห์เอกสาร หรือการตอบคำถามแบบยาว
p>
สำหรับ InfiniteBench เกณฑ์มาตรฐานที่ผลักดันโมเดลให้ถึงขีดจำกัดด้วยความยาวที่ยาวมาก ลำดับ—มีโทเค็นมากกว่า 200,000 โทเค็น—NAMM แสดงให้เห็นถึงความสามารถในการปรับขนาดได้อย่างมีประสิทธิภาพ
ในขณะที่โมเดลพื้นฐานต่อสู้กับความต้องการในการคำนวณของอินพุตที่มีความยาวดังกล่าว NAMM ก็ประสบความสำเร็จในการเพิ่มประสิทธิภาพอย่างมาก โดยเพิ่มความแม่นยำจาก 1.05% เป็น 11.00%
ผลลัพธ์นี้มีความโดดเด่นเป็นพิเศษ เนื่องจากแสดงให้เห็นความสามารถของ NAMM ในการจัดการบริบทที่ยาวเป็นพิเศษ ซึ่งเป็นความสามารถที่จำเป็นมากขึ้นสำหรับการใช้งาน เช่น การประมวลผลวรรณกรรมทางวิทยาศาสตร์ เอกสารทางกฎหมาย หรือที่เก็บรหัสขนาดใหญ่ที่มีขนาดอินพุตโทเค็นมีขนาดใหญ่มาก
ในเกณฑ์มาตรฐาน ChouBun ของ Sakana AI ซึ่งประเมินการใช้เหตุผลตามบริบทแบบยาวสำหรับงานภาษาญี่ปุ่น NAMM มีการปรับปรุง 15% จากระดับพื้นฐาน ChouBun จัดการกับช่องว่างในเกณฑ์มาตรฐานที่มีอยู่ ซึ่งมีแนวโน้มที่จะมุ่งเน้นไปที่ภาษาอังกฤษและภาษาจีน โดยการทดสอบแบบจำลองในการป้อนข้อความภาษาญี่ปุ่นแบบขยาย
ความสำเร็จของ NAMM บน ChouBun เน้นย้ำถึงความสามารถรอบด้านในภาษาต่างๆ และพิสูจน์ความแข็งแกร่งในการจัดการอินพุตที่ไม่ใช่ภาษาอังกฤษ ซึ่งเป็นคุณลักษณะสำคัญสำหรับแอปพลิเคชัน AI ทั่วโลก NAMM สามารถรักษาเนื้อหาเฉพาะบริบทได้อย่างมีประสิทธิภาพ ในขณะเดียวกันก็ละทิ้งความซ้ำซ้อนทางไวยากรณ์และโทเค็นที่มีความหมายน้อยกว่า ทำให้แบบจำลองสามารถทำงานได้อย่างมีประสิทธิผลมากขึ้นในงานต่างๆ เช่น การสรุปแบบยาวและความเข้าใจในภาษาญี่ปุ่น
 ที่มา: Sakana AI
ที่มา: Sakana AI
The ผลลัพธ์แสดงให้เห็นโดยรวมว่า NAMM เป็นเลิศในการเพิ่มประสิทธิภาพการใช้หน่วยความจำโดยไม่กระทบต่อความแม่นยำ ไม่ว่าจะได้รับการประเมินในงานที่ต้องใช้ลำดับที่ยาวมากหรือในบริบทที่ไม่ใช่ภาษาอังกฤษ NAMM มีประสิทธิภาพเหนือกว่าโมเดลพื้นฐานอย่างต่อเนื่อง โดยบรรลุทั้งประสิทธิภาพในการคำนวณและผลลัพธ์ที่ได้รับการปรับปรุง
การผสมผสานระหว่างการประหยัดหน่วยความจำและความแม่นยำทำให้ NAMM เป็นความก้าวหน้าที่ยอดเยี่ยมสำหรับระบบ AI ขององค์กรที่ได้รับมอบหมายให้จัดการกับอินพุตจำนวนมากและซับซ้อน
ผลลัพธ์มีความโดดเด่นเป็นพิเศษเมื่อเปรียบเทียบกับวิธีการก่อนหน้านี้ เช่น H₂O และ L2 ซึ่งเสียสละประสิทธิภาพเพื่อประสิทธิภาพ ในทางกลับกัน NAMM บรรลุเป้าหมายทั้งสองประการ
“ผลลัพธ์ของเราแสดงให้เห็นว่า NAMM ประสบความสำเร็จในการปรับปรุงอย่างต่อเนื่องทั้งในด้านประสิทธิภาพและแกนประสิทธิภาพโดยสัมพันธ์กับ Transformers พื้นฐาน”นักวิจัยระบุ
การใช้งานแบบข้ามโมดัล: เหนือกว่าภาษา
หนึ่งในการค้นพบที่น่าประทับใจที่สุดคือความสามารถของ NAMM ในการถ่ายโอน Zero-shot ไปยังงานอื่นๆ และรูปแบบการป้อนข้อมูล
ที่น่าทึ่งที่สุดแห่งหนึ่ง ลักษณะต่างๆ ของ Neural Attention Memory Models (NAMM) คือความสามารถในการถ่ายโอนงานต่างๆ และรูปแบบการป้อนข้อมูลได้อย่างราบรื่น นอกเหนือจากแอปพลิเคชันที่ใช้ภาษาแบบดั้งเดิม
ไม่เหมือนกับวิธีการเพิ่มประสิทธิภาพหน่วยความจำอื่นๆ ซึ่งมักต้องมีการฝึกอบรมใหม่หรือการปรับแต่งอย่างละเอียด สำหรับแต่ละโดเมน NAMM จะรักษาประสิทธิภาพและผลประโยชน์ด้านประสิทธิภาพไว้โดยไม่มีการปรับเปลี่ยนเพิ่มเติม การทดลองของ Sakana AI แสดงให้เห็นความเก่งกาจนี้ในสองโดเมนหลัก: การมองเห็นคอมพิวเตอร์และการเรียนรู้แบบเสริมกำลัง ซึ่งทั้งสองอย่างนี้นำเสนอความท้าทายที่ไม่เหมือนใครสำหรับ โมเดลที่ใช้หม้อแปลงไฟฟ้า
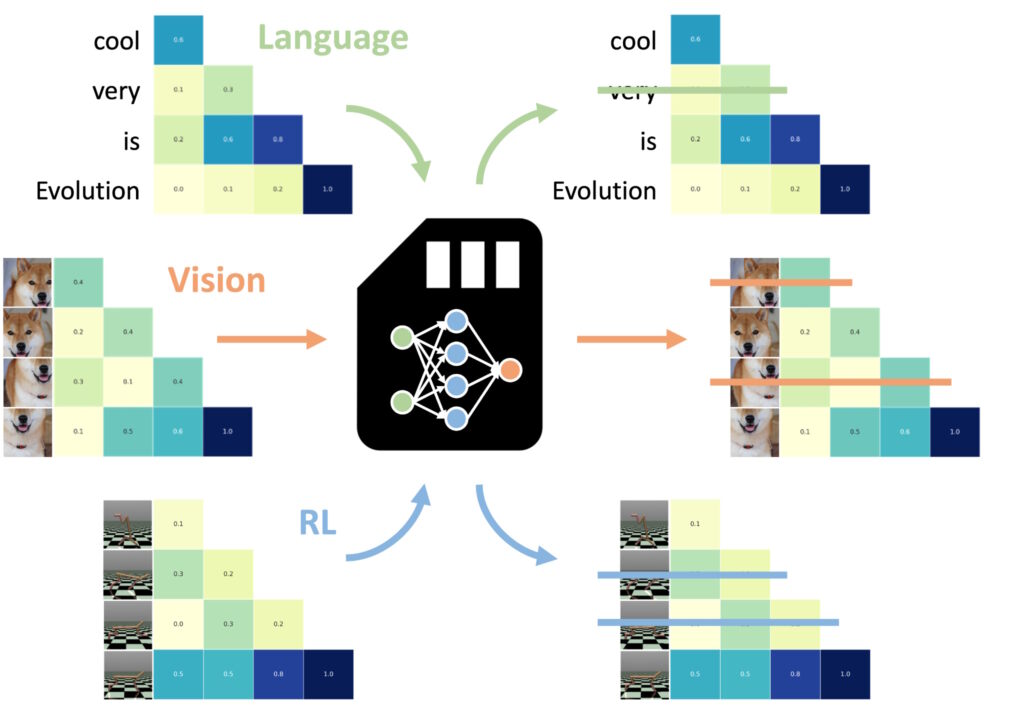 NAMM ที่ได้รับการฝึกภาษาสามารถเป็นศูนย์ได้ shot ที่ถ่ายโอนไปยังหม้อแปลงอื่น ๆ ผ่านทางรูปแบบอินพุตและโดเมนงาน (ภาพ: Sakana AI)
NAMM ที่ได้รับการฝึกภาษาสามารถเป็นศูนย์ได้ shot ที่ถ่ายโอนไปยังหม้อแปลงอื่น ๆ ผ่านทางรูปแบบอินพุตและโดเมนงาน (ภาพ: Sakana AI)
ใน คอมพิวเตอร์วิทัศน์ NAMM ได้รับการประเมินโดยใช้ โมเดล Llava Next Video ซึ่งเป็น หม้อแปลงไฟฟ้าที่ออกแบบมาสำหรับการประมวลผลลำดับวิดีโอขนาดยาว วิดีโอมักมีข้อมูลที่ซ้ำซ้อนจำนวนมหาศาล เช่น เฟรมที่ซ้ำกันหรือรูปแบบเล็กๆ น้อยๆ ที่ให้ข้อมูลเพิ่มเติมเพียงเล็กน้อย
NAMM จะระบุและทิ้งเฟรมที่ซ้ำซ้อนเหล่านี้โดยอัตโนมัติในระหว่างการอนุมาน โดยบีบอัดหน้าต่างบริบทอย่างมีประสิทธิภาพโดยไม่กระทบต่อความสามารถของโมเดลในการตีความเนื้อหาวิดีโอ
ตัวอย่างเช่น NAMM จะรักษาเฟรมที่มีรายละเอียดภาพที่สำคัญ เช่น การเปลี่ยนแปลงการดำเนินการ การโต้ตอบของวัตถุ หรือเหตุการณ์สำคัญ ในขณะที่ลบเฟรมที่ซ้ำหรือคงที่ออก ส่งผลให้ประสิทธิภาพการประมวลผลดีขึ้น ทำให้โมเดลสามารถมุ่งเน้นไปที่องค์ประกอบภาพที่เกี่ยวข้องมากที่สุด จึงรักษาความแม่นยำในขณะที่ลดต้นทุนการคำนวณ
ในการเรียนรู้แบบเสริมกำลัง NAMM ถูกนำไปใช้กับ Decision Transformer โมเดลที่ออกแบบมาเพื่อประมวลผลลำดับของการกระทำ การสังเกต และรางวัลเพื่อเพิ่มประสิทธิภาพการตัดสินใจ งาน งานการเรียนรู้แบบเสริมกำลังมักจะเกี่ยวข้องกับลำดับอินพุตที่ยาวนานซึ่งมีระดับความเกี่ยวข้องที่แตกต่างกัน ซึ่งการกระทำที่ต่ำกว่าปกติหรือซ้ำซ้อนสามารถขัดขวางประสิทธิภาพการทำงานได้
NAMM จัดการกับความท้าทายนี้โดยเลือกลบโทเค็นที่เกี่ยวข้องกับการดำเนินการที่ไม่มีประสิทธิภาพและข้อมูลมูลค่าต่ำ ขณะเดียวกันก็รักษาสิ่งเหล่านั้นที่สำคัญเพื่อให้บรรลุผลลัพธ์ที่ดีขึ้น
ตัวอย่างเช่น ในงานเช่น Hopper และ Walker2d—ซึ่งเกี่ยวข้องกับการควบคุมเอเจนต์เสมือนในการเคลื่อนไหวต่อเนื่อง—NAMM ปรับปรุงประสิทธิภาพมากกว่า 9% ด้วยการกรองการเคลื่อนไหวที่ต่ำกว่าปกติหรือรายละเอียดที่ไม่จำเป็นออก Decision Transformer จึงบรรลุการเรียนรู้ที่มีประสิทธิภาพและประสิทธิผลมากขึ้น โดยเน้นไปที่พลังในการคำนวณในการตัดสินใจที่เพิ่มความสำเร็จสูงสุดในงาน
ผลลัพธ์เหล่านี้เน้นย้ำถึงความสามารถในการปรับตัวของ NAMM ในโดเมนที่แตกต่างกันอย่างมากมาย ไม่ว่าจะประมวลผลเฟรมวิดีโอในโมเดลการมองเห็นหรือเพิ่มประสิทธิภาพลำดับการดำเนินการในการเรียนรู้แบบเสริมกำลัง NAMM แสดงให้เห็นถึงความสามารถในการเพิ่มประสิทธิภาพ ลดการใช้ทรัพยากร และรักษาความแม่นยำของโมเดล ทั้งหมดนี้โดยไม่ต้องฝึกอบรมซ้ำ
NAMM เรียนรู้ที่จะลืมส่วนต่างๆ เกือบทั้งหมด ของเฟรมวิดีโอที่ซ้ำซ้อน แทนที่จะเป็นโทเค็นภาษาที่อธิบายพรอมต์สุดท้าย กระดาษโน้ตที่เน้นความสามารถในการปรับตัวของ NAMM
การสนับสนุนทางเทคนิคของ NAMM
ประสิทธิภาพและประสิทธิผลของ Neural Attention Memory Models (NAMM) อยู่ในกระบวนการดำเนินการที่คล่องตัวและเป็นระบบ ซึ่งช่วยให้สามารถตัดโทเค็นได้อย่างแม่นยำโดยไม่ต้องมีการแทรกแซงด้วยตนเอง กระบวนการนี้สร้างขึ้นจากองค์ประกอบหลักสามประการ: สเปกโตรแกรมความสนใจ การบีบอัดคุณลักษณะ และการให้คะแนนอัตโนมัติ
NAMM ปรับพฤติกรรมแบบไดนามิกโดยขึ้นอยู่กับข้อกำหนดของงานและความลึกของเลเยอร์ Transformer เลเยอร์แรกจะจัดลำดับความสำคัญของบริบท”ทั่วโลก”เช่น คำอธิบายงาน ในขณะที่เลเยอร์ที่ลึกกว่าจะเก็บรายละเอียดเฉพาะงาน”ในท้องถิ่น”ในงานเขียนโค้ด NAMM จะละทิ้งความคิดเห็นและโค้ดสำเร็จรูป ในงานภาษาธรรมชาติ พวกเขากำจัดความซ้ำซ้อนทางไวยากรณ์ในขณะที่ยังคงรักษาเนื้อหาสำคัญไว้
การเก็บรักษาโทเค็นที่ปรับเปลี่ยนได้นี้ช่วยให้มั่นใจได้ว่าโมเดลยังคงมุ่งเน้นไปที่ข้อมูลที่เกี่ยวข้องตลอดการประมวลผล ซึ่งปรับปรุงความเร็วและความแม่นยำ
ครั้งแรก ขั้นตอนเกี่ยวข้องกับการสร้าง สเปกตรัมความสนใจ Transformers คำนวณ “ค่าความสนใจ” ในทุกเลเยอร์เพื่อกำหนดความสำคัญสัมพัทธ์ของแต่ละโทเค็นภายในหน้าต่างบริบท NAMM แปลงค่าความสนใจเหล่านี้เป็น การแสดงตามความถี่ โดยใช้ การแปลงฟูริเยร์เวลาสั้น (STFT)
STFT เป็นเทคนิคการประมวลผลสัญญาณที่ใช้กันอย่างแพร่หลาย ซึ่งแบ่งลำดับออกเป็นส่วนประกอบความถี่ที่แปลเป็นภาษาท้องถิ่นในช่วงเวลาหนึ่งๆ โดยให้การแสดงความสำคัญของโทเค็นที่มีขนาดกะทัดรัดแต่มีรายละเอียด เมื่อใช้ STFT จะทำให้ NAMM แปลงลำดับความสนใจดิบเป็นข้อมูลที่มีลักษณะคล้ายสเปกโตรแกรม การวิเคราะห์ที่ชัดเจนยิ่งขึ้นว่าโทเค็นใดมีส่วนสำคัญต่อเอาท์พุตของโมเดล
ถัดไป การบีบอัดคุณลักษณะ จะถูกนำไปใช้เพื่อลดมิติของข้อมูลสเปกโตรแกรมในขณะที่ยังคงรักษาข้อมูลที่จำเป็นไว้ คุณลักษณะนี้สามารถทำได้โดยใช้ค่าเฉลี่ยเคลื่อนที่แบบเอ็กซ์โปเนนเชียล (EMA) ซึ่งเป็นวิธีการทางคณิตศาสตร์ที่บีบอัดรูปแบบความสนใจในอดีตให้เป็นข้อมูลสรุปที่มีขนาดคงที่และกะทัดรัด EMA ทำให้แน่ใจว่าการนำเสนอยังคงมีน้ำหนักเบาและสามารถจัดการได้ ทำให้ NAMM สามารถวิเคราะห์ลำดับความสนใจที่ยาวนานได้อย่างมีประสิทธิภาพในขณะที่ลดค่าใช้จ่ายในการคำนวณ
ขั้นตอนสุดท้ายคือ การให้คะแนนและการตัดออก โดยที่ NAMM ใช้น้ำหนักเบา ตัวแยกประเภทโครงข่ายประสาทเทียมเพื่อประเมินการแสดงโทเค็นที่ถูกบีบอัดและกำหนดคะแนนตามความสำคัญ โทเค็นที่มีคะแนนต่ำกว่าเกณฑ์ที่กำหนดจะถูกตัดออกจากหน้าต่างบริบท โดยจะ”ลืม”รายละเอียดที่ไม่มีประโยชน์หรือซ้ำซ้อนได้อย่างมีประสิทธิภาพ กลไกการให้คะแนนนี้ช่วยให้ NAMM สามารถจัดลำดับความสำคัญของโทเค็นที่สำคัญซึ่งนำไปสู่กระบวนการตัดสินใจของแบบจำลองในขณะที่ละทิ้งข้อมูลที่เกี่ยวข้องน้อยกว่า
สิ่งที่ทำให้ NAMM มีประสิทธิภาพเป็นพิเศษคือการพึ่งพาการเพิ่มประสิทธิภาพเชิงวิวัฒนาการในการปรับแต่งกระบวนการนี้ งานที่ไม่สามารถแยกแยะได้ เช่น การตัดสินใจว่าควรเก็บโทเค็นไว้หรือทิ้งไป
แต่ NAMM จะใช้อัลกอริธึมวิวัฒนาการซ้ำๆ ซึ่งได้รับแรงบันดาลใจจากการคัดเลือกโดยธรรมชาติ เพื่อ”กลายพันธุ์”และ”เลือก”หน่วยความจำที่มีประสิทธิภาพมากที่สุด กลยุทธ์การจัดการเมื่อเวลาผ่านไป ผ่านการทดลองซ้ำหลายครั้ง ระบบจะพัฒนาเพื่อจัดลำดับความสำคัญของโทเค็นที่จำเป็นโดยอัตโนมัติ ทำให้เกิดความสมดุลระหว่างประสิทธิภาพและประสิทธิภาพของหน่วยความจำโดยไม่ต้องมีการปรับแต่งแบบละเอียดด้วยตนเอง
สิ่งนี้มีความคล่องตัวมากขึ้น การดำเนินการ—รวมการวิเคราะห์โทเค็นที่ใช้สเปกโตรแกรม การบีบอัดที่มีประสิทธิภาพ และการตัดแบบอัตโนมัติ—ทำให้ NAMM สามารถประหยัดทั้งหน่วยความจำได้อย่างมากและเพิ่มประสิทธิภาพในงานต่างๆ ที่ใช้ Transformer ที่หลากหลาย ด้วยการลดข้อกำหนดในการคำนวณในขณะที่รักษาหรือปรับปรุงความแม่นยำ NAMM ได้สร้างมาตรฐานใหม่สำหรับการจัดการหน่วยความจำที่มีประสิทธิภาพในโมเดล AI สมัยใหม่
อะไรจะเกิดขึ้นต่อไปสำหรับ Transformers
Sakana AI เชื่อว่า NAMM เป็นเพียงจุดเริ่มต้นเท่านั้น แม้ว่างานปัจจุบันจะมุ่งเน้นไปที่การปรับโมเดลที่ได้รับการฝึกอบรมล่วงหน้าให้เหมาะสมตามอนุมาน แต่การวิจัยในอนาคตอาจรวม NAMM เข้ากับกระบวนการฝึกอบรมด้วย ซึ่งอาจทำให้โมเดลสามารถเรียนรู้กลยุทธ์การจัดการหน่วยความจำแบบเนทีฟ โดยขยายความยาวของหน้าต่างบริบทและเพิ่มประสิทธิภาพข้ามโดเมน
“งานนี้เพิ่งเริ่มสำรวจพื้นที่การออกแบบของโมเดลหน่วยความจำของเรา ซึ่งเราคาดหวังไว้ อาจเสนอโอกาสใหม่ๆ มากมายในการพัฒนาหม้อแปลงรุ่นต่อไปในอนาคต”ทีมงานสรุป
ความสามารถที่ได้รับการพิสูจน์แล้วของ NAMMs ในการขยายขนาดประสิทธิภาพ ลดต้นทุน และปรับตัวข้ามรูปแบบต่างๆ ได้ทำให้เกิดมาตรฐานใหม่สำหรับประสิทธิภาพของหม้อแปลงขนาดใหญ่ AI โมเดล