DeepSeek AI ได้เปิดตัว DeepSeek-VL2 ซึ่งเป็นตระกูล Vision-Language Models (VLM) ที่ขณะนี้สามารถใช้งานได้ภายใต้ใบอนุญาตโอเพ่นซอร์ส ซีรีส์นี้แนะนำตัวแปรสามแบบ ได้แก่ Tiny, Small และ VL2 มาตรฐาน ซึ่งมีขนาดพารามิเตอร์ที่เปิดใช้งานอยู่ที่ 1.0 พันล้าน, 2.8 พันล้าน และ 4.5 พันล้าน ตามลำดับ
โมเดลต่างๆ สามารถเข้าถึงได้ผ่าน GitHub และ ใบหน้ากอด. พวกเขาสัญญาว่าจะพัฒนาแอปพลิเคชัน AI ที่สำคัญ ๆ รวมถึงการตอบคำถามด้วยภาพ (VQA) การรู้จำอักขระด้วยแสง (OCR) และการวิเคราะห์เอกสารและแผนภูมิที่มีความละเอียดสูง
ตามเอกสาร GitHub อย่างเป็นทางการ “DeepSeek-VL2 แสดงให้เห็นถึงความสามารถที่เหนือกว่าในงานต่างๆ รวมถึงแต่ไม่จำกัดเพียงการตอบคำถามด้วยภาพ การทำความเข้าใจเอกสาร/ตาราง/แผนภูมิ และการต่อสายดินด้วยภาพ”
ช่วงเวลาของการเปิดตัวครั้งนี้ทำให้ DeepSeek AI แข่งขันโดยตรงกับผู้เล่นรายใหญ่อย่าง OpenAI และ Google ซึ่งทั้งสองคนครองโดเมน AI ภาษาแห่งการมองเห็นด้วยกรรมสิทธิ์ รุ่นต่างๆ เช่น GPT-4V และ Gemini-Exp.
การเน้นย้ำของ DeepSeek ในการทำงานร่วมกันแบบโอเพ่นซอร์ส รวมกับคุณสมบัติทางเทคนิคขั้นสูงของกลุ่ม VL2 ทำให้เป็นตัวเลือกฟรีสำหรับนักวิจัย
การเรียงข้อมูลแบบไดนามิก: การประมวลผลภาพความละเอียดสูงที่ล้ำหน้า
หนึ่งในความก้าวหน้าที่โดดเด่นที่สุดใน DeepSeek-VL2 คือกลยุทธ์การเข้ารหัสการมองเห็นแบบเรียงต่อกันแบบไดนามิก ซึ่งปฏิวัติวิธีที่โมเดลประมวลผลข้อมูลภาพที่มีความละเอียดสูง
ต่างจากความละเอียดคงที่แบบดั้งเดิม การจัดเรียงภาพแบบไดนามิกจะแบ่งภาพออกเป็นภาพย่อยที่เล็กลงและยืดหยุ่นได้ ซึ่งปรับให้เข้ากับอัตราส่วนภาพต่างๆ วิธีการนี้ช่วยให้มั่นใจได้ถึงการแยกคุณสมบัติโดยละเอียดในขณะที่ยังคงประสิทธิภาพการคำนวณไว้
ในพื้นที่เก็บข้อมูล GitHub นั้น DeepSeek อธิบายว่านี่เป็นวิธี”ประมวลผลภาพที่มีความละเอียดสูงอย่างมีประสิทธิภาพด้วยอัตราส่วนภาพที่แตกต่างกัน โดยหลีกเลี่ยงการปรับขนาดทางการคำนวณซึ่งโดยทั่วไปแล้วจะเกี่ยวข้องกับการเพิ่มความละเอียดของภาพ”
ความสามารถนี้ช่วยให้ DeepSeek-VL2 เป็นเลิศในการใช้งานต่างๆ เช่น การต่อสายดินด้วยภาพ ซึ่งจำเป็นต้องมีความแม่นยำสูงในการระบุวัตถุในภาพที่ซับซ้อน และงาน OCR ที่หนาแน่น ซึ่งต้องมีการประมวลผลข้อความในเอกสารหรือแผนภูมิที่มีรายละเอียด
ด้วยการปรับความละเอียดของภาพและอัตราส่วนภาพแบบไดนามิกแบบไดนามิก โมเดลเหล่านี้จึงเอาชนะข้อจำกัดของวิธีการเข้ารหัสแบบคงที่ ทำให้เหมาะสำหรับกรณีการใช้งานที่ต้องการทั้งความยืดหยุ่นและความแม่นยำ
การผสมผสานของผู้เชี่ยวชาญและความสนใจแฝงแบบหลายหัวเพื่อประสิทธิภาพ
ประสิทธิภาพของ DeepSeek-VL2 ที่เพิ่มขึ้นได้รับการสนับสนุนเพิ่มเติมโดยการบูรณาการของ Mixture-of-Experts (MoE) และกลไก Multi-head Latent Attention (MLA)
สถาปัตยกรรม MoE เลือกเปิดใช้งานชุดย่อยเฉพาะหรือ “ผู้เชี่ยวชาญ” ภายในโมเดลเพื่อจัดการงานได้อย่างมีประสิทธิภาพมากขึ้น การออกแบบนี้ช่วยลดค่าใช้จ่ายในการคำนวณโดยการใช้เฉพาะพารามิเตอร์ที่จำเป็นสำหรับการดำเนินการแต่ละครั้ง ซึ่งเป็นคุณลักษณะที่มีประโยชน์อย่างยิ่งในสภาพแวดล้อมที่มีทรัพยากรจำกัด
กลไก MLA ช่วยเสริมกรอบงาน MoE โดยการบีบอัดแคชคีย์-ค่าให้อยู่ในค่าแฝง เวกเตอร์ในระหว่างการอนุมาน การเพิ่มประสิทธิภาพนี้ช่วยลดการใช้หน่วยความจำและเพิ่มความเร็วในการประมวลผลโดยไม่ทำให้ความแม่นยำของโมเดลลดลง
ตามเอกสารทางเทคนิค “สถาปัตยกรรม MoE เมื่อรวมกับ MLA ช่วยให้ DeepSeek-VL2 บรรลุประสิทธิภาพการแข่งขันหรือดีกว่าโมเดลหนาแน่นที่มีพารามิเตอร์เปิดใช้งานน้อยกว่า”
ขั้นตอนการฝึกอบรมสามขั้นตอน
การพัฒนา DeepSeek-VL2 เกี่ยวข้องกับขั้นตอนการฝึกอบรมสามขั้นตอนที่เข้มงวดซึ่งออกแบบมาเพื่อเพิ่มประสิทธิภาพความสามารถหลายรูปแบบของโมเดล ขั้นตอนแรกที่มุ่งเน้นไปที่ การจัดตำแหน่งภาษาของการมองเห็น ซึ่งโมเดลได้รับการฝึกอบรมเพื่อรวมคุณลักษณะด้านภาพเข้ากับข้อมูลที่เป็นข้อความ
ทำได้สำเร็จโดยใช้ชุดข้อมูล เช่น ShareGPT4V ซึ่งให้ตัวอย่างข้อความรูปภาพที่จับคู่สำหรับการจัดตำแหน่งเริ่มต้น การฝึกอบรมภาษาล่วงหน้า ซึ่งรวมเอาชุดข้อมูลที่หลากหลาย รวมถึงข้อมูล WIT, WikiHow และข้อมูล OCR หลายภาษา เพื่อเพิ่มความสามารถในการวางนัยทั่วไปของโมเดลในหลายโดเมน
สุดท้าย ที่สาม ขั้นตอนประกอบด้วยการปรับแต่งแบบละเอียดภายใต้การดูแล (SFT) ซึ่งใช้ชุดข้อมูลเฉพาะงานเพื่อปรับแต่งประสิทธิภาพของโมเดลในด้านต่างๆ เช่น การต่อสายดินด้วยภาพ ความเข้าใจอินเทอร์เฟซผู้ใช้แบบกราฟิก (GUI) และคำอธิบายภาพแบบหนาแน่น
การฝึกอบรมเหล่านี้ ขั้นตอนดังกล่าวทำให้ DeepSeek-VL2 สามารถสร้างรากฐานที่มั่นคงสำหรับการทำความเข้าใจหลายรูปแบบ ในขณะเดียวกันก็ทำให้แบบจำลองสามารถปรับตัวเข้ากับงานเฉพาะทางได้ การรวมชุดข้อมูลหลายภาษาช่วยเพิ่มความสามารถในการบังคับใช้แบบจำลองในการวิจัยระดับโลกและการตั้งค่าอุตสาหกรรม
ที่เกี่ยวข้อง: โมเดล DeepSeek R1-Lite-Preview ของจีนมุ่งเป้าไปที่ความเป็นผู้นำของ OpenAI ในด้านการใช้เหตุผลอัตโนมัติ
ผลลัพธ์การเปรียบเทียบ
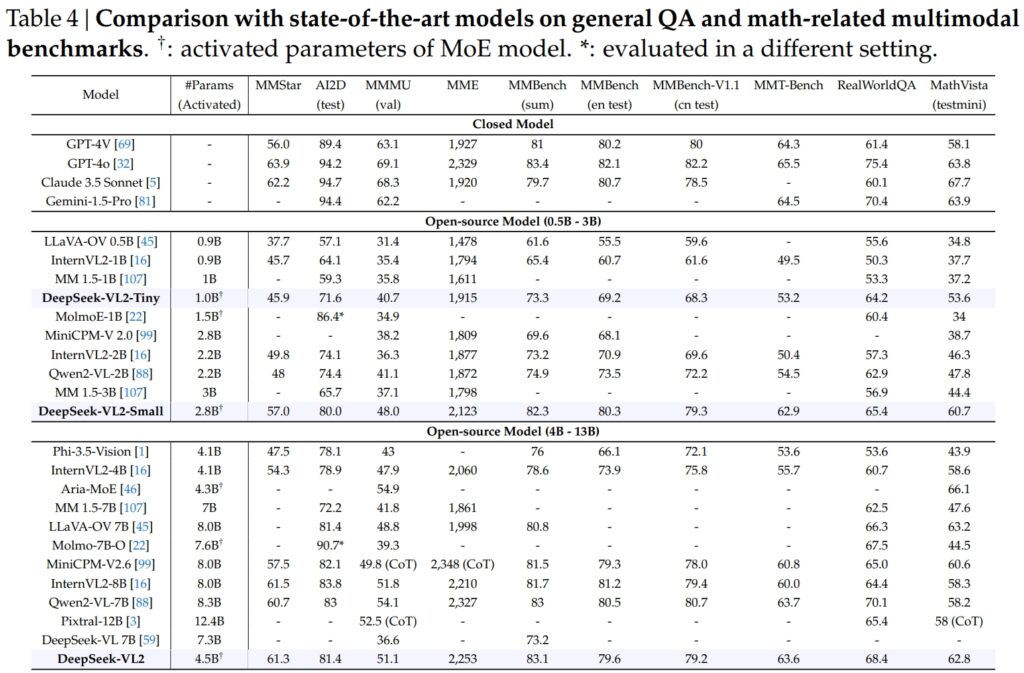
รุ่น DeepSeek-VL2 รวมถึงรุ่น Tiny, Small และรุ่นมาตรฐาน มีความเป็นเลิศในการวัดประสิทธิภาพที่สำคัญสำหรับ การตอบคำถามทั่วไป (QA) และงานต่อเนื่องหลายรูปแบบที่เกี่ยวข้องกับคณิตศาสตร์
DeepSeek-VL2-Small ซึ่งมีพารามิเตอร์ที่เปิดใช้งานถึง 2.8 พันล้านพารามิเตอร์ ได้รับคะแนน MMStar ที่ 57.0 และมีประสิทธิภาพเหนือกว่ารุ่นที่มีขนาดใกล้เคียงกัน เช่น InternVL2-2B (49.8) และ Qwen2-VL-2B (48.0) นอกจากนี้ยังเทียบเคียงได้อย่างใกล้ชิดกับรุ่นที่มีขนาดใหญ่กว่ามาก เช่น 4.1B InternVL2-4B (54.3) และ 8.3B Qwen2-VL-7B (60.7) ซึ่งแสดงให้เห็นถึงประสิทธิภาพในการแข่งขัน
ในการทดสอบ AI2D สำหรับการมองเห็น การใช้เหตุผล DeepSeek-VL2-Small ได้คะแนน 80.0 แซงหน้า InternVL2-2B (74.1) และ MM 1.5-3B (ไม่ได้รายงาน) แม้จะแข่งขันกับคู่แข่งรายใหญ่อย่าง InternVL2-4B (78.9) และ MiniCPM-V2.6 (82.1) แต่ DeepSeek-VL2 ก็แสดงผลลัพธ์ที่ยอดเยี่ยมด้วยพารามิเตอร์ที่เปิดใช้งานน้อยกว่า
 ที่มา: DeepSeek
ที่มา: DeepSeek
เรือธง รุ่น DeepSeek-VL2 (พารามิเตอร์ที่เปิดใช้งาน 4.5 พันล้านพารามิเตอร์) ให้ผลลัพธ์ที่ยอดเยี่ยม โดยได้คะแนน 61.3 ใน MMStar และ 81.4 บน AI2D มีประสิทธิภาพเหนือกว่าคู่แข่ง เช่น Molmo-7B-O (พารามิเตอร์ที่เปิดใช้งาน 7.6B, 39.3) และ MiniCPM-V2.6 (8.0B, 57.5) ซึ่งช่วยยืนยันความเหนือกว่าทางเทคนิคเพิ่มเติมอีก
ความเป็นเลิศใน OCR-เกณฑ์มาตรฐานที่เกี่ยวข้อง
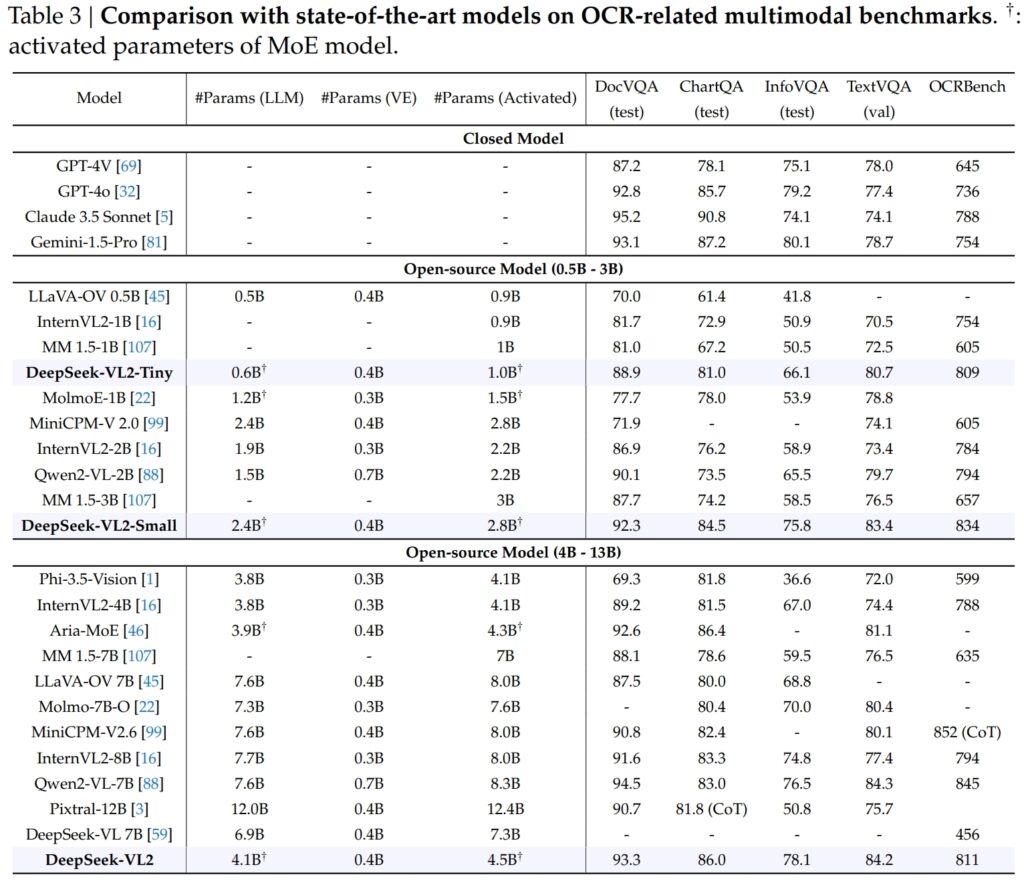
ความสามารถของ DeepSeek-VL2 ขยายอย่างเด่นชัดไปยัง OCR (การรู้จำอักขระด้วยแสง) ที่เกี่ยวข้อง งาน ซึ่งเป็นส่วนสำคัญสำหรับการทำความเข้าใจเอกสารและการแยกข้อความใน AI ในการทดสอบ DocVQA นั้น DeepSeek-VL2-Small มีความแม่นยำ 92.3% ที่น่าประทับใจ ซึ่งมีประสิทธิภาพเหนือกว่าโมเดลโอเพ่นซอร์สอื่นๆ ทั้งหมดในขนาดใกล้เคียงกัน รวมถึง InternVL2-4B (89.2%) และ MiniCPM-V2.6 (90.8%) ความแม่นยำของมันตามหลังรุ่นปิดอย่าง GPT-4o (92.8) และ Claude 3.5 Sonnet (95.2)
โมเดล DeepSeek-VL2 ยังเป็นผู้นำในการทดสอบ ChartQA ด้วยคะแนน 86.0 ซึ่งเหนือกว่า InternVL2-4B (81.5) และ MiniCPM-V2.6 (82.4) ผลลัพธ์นี้สะท้อนถึงความสามารถขั้นสูงของ DeepSeek-VL2 ในการประมวลผลแผนภูมิและดึงข้อมูลเชิงลึกจากข้อมูลภาพที่ซับซ้อน
 ที่มา: DeepSeek
ที่มา: DeepSeek
ใน OCRBench การแข่งขันสูง เมตริกสำหรับการรู้จำข้อความแบบละเอียด DeepSeek-VL2 ทำได้ 811 ซึ่งเหนือกว่า 7.6B Qwen2-VL-7B (845) และ MiniCPM-V2.6 (852 พร้อม CoT) และเน้นจุดแข็งในงาน OCR ที่หนาแน่น
เปรียบเทียบกับโมเดลภาษาวิสัยทัศน์ชั้นนำ
เมื่อวางเคียงข้างผู้นำในอุตสาหกรรม เช่น GPT-4V ของ OpenAI และ Gemini-1.5-Pro ของ Google รุ่น DeepSeek-VL2 มอบความสมดุลที่น่าสนใจ ของประสิทธิภาพและประสิทธิผล ตัวอย่างเช่น GPT-4V ได้คะแนน 87.2 ใน DocVQA ซึ่งเหนือกว่า DeepSeek-VL2 (93.3) เพียงเล็กน้อยเท่านั้น แม้ว่าอย่างหลังจะทำงานภายใต้เฟรมเวิร์กโอเพ่นซอร์สที่มีพารามิเตอร์เปิดใช้งานน้อยกว่าก็ตาม
ใน TextVQA, DeepSeek-VL2-Small ทำได้ที่ 83.4 ซึ่งมีประสิทธิภาพเหนือกว่ารุ่นโอเพ่นซอร์สที่คล้ายกันอย่าง InternVL2-2B (73.4) และ MiniCPM-V2.0 (74.1) แม้แต่ MiniCPM-V2.6 (8.0B) ที่ใหญ่กว่ามากก็สูงถึงเพียง 80.4 เท่านั้น ซึ่งตอกย้ำถึงความสามารถในการปรับขนาดและประสิทธิภาพของสถาปัตยกรรมของ DeepSeek-VL2 ได้อีก
สำหรับ ChartQA คะแนนของ DeepSeek-VL2 ที่ 86.0 สูงกว่าคะแนนของ Pixtral-12B (81.8) และ InternVL2-8B (83.3) แสดงให้เห็นถึงความสามารถในการเป็นเลิศ ในงานเฉพาะทางที่ต้องการความเข้าใจทั้งภาพและข้อความที่แม่นยำ
ที่เกี่ยวข้อง: Mistral AI เปิดตัว Pixtral 12B สำหรับการประมวลผลข้อความและรูปภาพ
การขยายแอปพลิเคชัน: จาก การสนทนาแบบมีพื้นฐานเพื่อการเล่าเรื่องด้วยภาพ
คุณลักษณะเด่นประการหนึ่งของโมเดล DeepSeek-VL2 คือความสามารถในการดำเนินการสนทนาแบบมีพื้นฐาน ซึ่งโมเดลสามารถระบุวัตถุในรูปภาพและบูรณาการได้ ให้เป็นการอภิปรายตามบริบท
ตัวอย่างเช่น โดยการใช้โทเค็นพิเศษ โมเดลสามารถให้รายละเอียดเฉพาะวัตถุ เช่น ตำแหน่งและคำอธิบาย เพื่อตอบคำถามเกี่ยวกับรูปภาพ สิ่งนี้เปิดความเป็นไปได้สำหรับแอปพลิเคชันในวิทยาการหุ่นยนต์ ความเป็นจริงเสริม และผู้ช่วยเหลือดิจิทัล ซึ่งจำเป็นต้องมีการให้เหตุผลด้วยภาพที่แม่นยำ
แอปพลิเคชันอีกด้านคือการเล่าเรื่องด้วยภาพ DeepSeek-VL2 สามารถสร้างการเล่าเรื่องที่สอดคล้องกันตามลำดับภาพ ซึ่งผสมผสานการจดจำภาพขั้นสูงและความสามารถทางภาษาเข้าด้วยกัน
สิ่งนี้มีคุณค่าอย่างยิ่งในโดเมนต่างๆ เช่น การศึกษา สื่อ และความบันเทิง ซึ่งการสร้างเนื้อหาแบบไดนามิกมีความสำคัญเป็นอันดับแรก โมเดลเหล่านี้ใช้ประโยชน์จากความเข้าใจที่หลากหลายเพื่อสร้างเรื่องราวที่มีรายละเอียดและเหมาะสมกับบริบท โดยผสานองค์ประกอบภาพ เช่น จุดสังเกตและข้อความในการเล่าเรื่องได้อย่างราบรื่น
ความสามารถของโมเดลในการสร้างภาพก็มีความแข็งแกร่งพอๆ กัน ในการทดสอบที่เกี่ยวข้องกับภาพที่ซับซ้อน DeepSeek-VL2 ได้แสดงให้เห็นถึงความสามารถในการระบุตำแหน่งและอธิบายวัตถุได้อย่างแม่นยำตามคำอธิบาย
ตัวอย่างเช่น เมื่อถูกขอให้ระบุ “รถที่จอดอยู่ทางด้านซ้ายของถนน” โมเดลสามารถระบุวัตถุที่แน่นอนในภาพและสร้างพิกัดกล่องขอบเขตเพื่อแสดงการตอบสนอง คุณสมบัติเหล่านี้ทำให้ มันใช้งานได้อย่างมากกับระบบอัตโนมัติและการเฝ้าระวัง ซึ่งการวิเคราะห์ภาพโดยละเอียดเป็นสิ่งสำคัญ
การเข้าถึงแบบโอเพ่นซอร์สและความสามารถในการปรับขนาด
การตัดสินใจของ DeepSeek AI ที่จะเผยแพร่ DeepSeek-VL2 ในฐานะโอเพ่นซอร์สแตกต่างอย่างมากกับลักษณะกรรมสิทธิ์ของคู่แข่ง เช่น GPT-4V ของ OpenAI และ Gemini-Exp ของ Google ซึ่งเป็นระบบปิดที่ออกแบบมาเพื่อการเข้าถึงสาธารณะอย่างจำกัด
ตามเอกสารทางเทคนิค “ด้วยการเผยแพร่โมเดลและโค้ดที่ได้รับการฝึกอบรมล่วงหน้าของเราต่อสาธารณะ เราตั้งเป้าที่จะเร่งความก้าวหน้าในการสร้างแบบจำลองภาษาวิสัยทัศน์ และส่งเสริมนวัตกรรมการทำงานร่วมกันทั่วทั้งชุมชนการวิจัย”
ความสามารถในการปรับขนาดของ DeepSeek-VL2 ช่วยเพิ่มความน่าสนใจยิ่งขึ้นไปอีก โมเดลเหล่านี้ได้รับการปรับให้เหมาะสมสำหรับการปรับใช้ในการกำหนดค่าฮาร์ดแวร์ที่หลากหลาย ตั้งแต่ GPU ตัวเดียวที่มีหน่วยความจำ 10GB ไปจนถึงการตั้งค่า GPU หลายตัวที่สามารถรองรับปริมาณงานขนาดใหญ่ได้
ความยืดหยุ่นนี้ช่วยให้มั่นใจได้ว่าองค์กรทุกขนาดสามารถใช้ DeepSeek-VL2 ได้ ตั้งแต่สตาร์ทอัพไปจนถึงองค์กรขนาดใหญ่ โดยไม่จำเป็นต้องใช้โครงสร้างพื้นฐานเฉพาะทาง
นวัตกรรมด้านข้อมูลและ การฝึกอบรม
ปัจจัยสำคัญเบื้องหลังความสำเร็จของ DeepSeek-VL2 คือข้อมูลการฝึกอบรมที่กว้างขวางและหลากหลาย ขั้นตอนการเตรียมการฝึกรวมชุดข้อมูล เช่น WIT, WikiHow และ OBELICS ซึ่งจัดให้มีการผสมผสานระหว่างคู่ข้อความรูปภาพที่สลับกันเพื่อการสรุปทั่วไป
ข้อมูลเพิ่มเติมสำหรับงานเฉพาะ เช่น OCR และการตอบคำถามด้วยภาพ มาจากแหล่งที่มา เช่น LaTeX OCR และ PubTabNet เพื่อให้มั่นใจว่าแบบจำลองสามารถจัดการทั้งงานทั่วไปและงานเฉพาะทางด้วยความแม่นยำสูง
การรวมชุดข้อมูลหลายภาษายังสะท้อนถึงเป้าหมายของ DeepSeek AI ที่ต้องการนำไปใช้ทั่วโลก ชุดข้อมูลภาษาจีน เช่น Wanjuan ถูกรวมเข้ากับชุดข้อมูลภาษาอังกฤษเพื่อให้แน่ใจว่าโมเดลสามารถทำงานได้อย่างมีประสิทธิภาพในสภาพแวดล้อมหลายภาษา
แนวทางนี้ช่วยเพิ่มความสามารถในการใช้งาน DeepSeek-VL2 ในภูมิภาคที่มีข้อมูลที่ไม่ใช่ภาษาอังกฤษครอบงำ และขยายฐานผู้ใช้ที่มีศักยภาพอย่างมีนัยสำคัญ
ขั้นตอนการปรับแต่งอย่างละเอียดภายใต้การดูแลได้ปรับปรุงโมเดลเพิ่มเติม ความสามารถโดยมุ่งเน้นไปที่งานเฉพาะเช่นความเข้าใจ GUI และการวิเคราะห์แผนภูมิ ด้วยการรวมชุดข้อมูลภายในองค์กรเข้ากับทรัพยากรโอเพ่นซอร์สคุณภาพสูง DeepSeek-VL2 จึงได้รับประสิทธิภาพที่ล้ำสมัยบนเกณฑ์มาตรฐานต่างๆ ซึ่งตรวจสอบประสิทธิภาพของวิธีการฝึกอบรม
การดูแลจัดการอย่างระมัดระวังของ DeepSeek AI ของข้อมูลและไปป์ไลน์การฝึกอบรมเชิงนวัตกรรมทำให้โมเดล VL2 เก่งในงานที่หลากหลาย ขณะเดียวกันก็รักษาประสิทธิภาพและความสามารถในการปรับขนาดได้ ปัจจัยเหล่านี้ทำให้พวกเขาเป็นส่วนเสริมที่มีคุณค่าในด้าน AI ต่อเนื่องหลายรูปแบบ
ความสามารถของโมเดลในการจัดการงานการประมวลผลภาพที่ซับซ้อน เช่น การต่อสายดินด้วยภาพและ OCR ที่หนาแน่น ทำให้โมเดลเหล่านี้เหมาะสำหรับอุตสาหกรรม เช่น โลจิสติกส์และการรักษาความปลอดภัย ในด้านลอจิสติกส์ พวกเขาสามารถทำให้การติดตามสินค้าคงคลังเป็นอัตโนมัติโดยการวิเคราะห์รูปภาพสต็อกในคลังสินค้า การระบุรายการ และบูรณาการสิ่งที่ค้นพบเข้ากับระบบการจัดการสินค้าคงคลัง
ในโดเมนความปลอดภัย DeepSeek-VL2 สามารถช่วยในการเฝ้าระวังโดยการระบุวัตถุหรือบุคคลแบบเรียลไทม์ โดยอิงจากการสืบค้นเชิงอธิบาย และให้ข้อมูลบริบทโดยละเอียดแก่ผู้ปฏิบัติงาน
DeepSeek-ความสามารถในการสนทนาที่มีพื้นฐานมาจาก VL2 ยังมอบความเป็นไปได้ในด้านวิทยาการหุ่นยนต์และความเป็นจริงเสริมอีกด้วย ตัวอย่างเช่น หุ่นยนต์ที่ติดตั้งโมเดลนี้สามารถตีความสภาพแวดล้อมด้วยสายตา ตอบสนองต่อคำถามของมนุษย์เกี่ยวกับวัตถุเฉพาะ และดำเนินการตามความเข้าใจในการป้อนข้อมูลด้วยภาพ
ในทำนองเดียวกัน อุปกรณ์ความเป็นจริงเสริมสามารถใช้ประโยชน์จากคุณสมบัติการมองเห็นและการเล่าเรื่องของโมเดลเพื่อมอบประสบการณ์เชิงโต้ตอบและดื่มด่ำ เช่น ทัวร์ชมพร้อมคำแนะนำหรือการวางซ้อนตามบริบทในสภาพแวดล้อมแบบเรียลไทม์
ความท้าทายและอนาคต
แม้จะมีจุดแข็งมากมาย DeepSeek-VL2 ก็เผชิญกับความท้าทายหลายประการ ข้อจำกัดที่สำคัญประการหนึ่งคือขนาดของหน้าต่างบริบท ซึ่งปัจจุบันจำกัดจำนวนรูปภาพที่สามารถประมวลผลได้ภายในการโต้ตอบครั้งเดียว
การขยายหน้าต่างบริบทนี้ในการทำซ้ำในอนาคตจะช่วยให้เกิดการโต้ตอบแบบหลายภาพที่สมบูรณ์ยิ่งขึ้น และปรับปรุงยูทิลิตี้ของโมเดลในงานที่ต้องการความเข้าใจตามบริบทที่กว้างขึ้น
ความท้าทายอีกประการหนึ่งอยู่ที่การจัดการนอก โดเมนหรืออินพุตภาพคุณภาพต่ำ เช่น รูปภาพที่ไม่ชัดหรือวัตถุที่ไม่ปรากฏในข้อมูลการฝึก แม้ว่า DeepSeek-VL2 จะแสดงให้เห็นถึงความสามารถในการวางลักษณะทั่วไปที่น่าทึ่ง แต่การปรับปรุงความทนทานต่ออินพุตดังกล่าวจะช่วยเพิ่มความสามารถในการนำไปใช้ในสถานการณ์จริง
เมื่อมองไปข้างหน้า DeepSeek AI วางแผนที่จะเสริมสร้างความสามารถในการให้เหตุผลของโมเดล เพื่อให้สามารถจัดการกับงานต่อเนื่องหลายรูปแบบที่ซับซ้อนมากขึ้นได้ ด้วยการผสานรวมไปป์ไลน์การฝึกอบรมที่ได้รับการปรับปรุงและการขยายชุดข้อมูลเพื่อให้ครอบคลุมสถานการณ์ที่หลากหลายมากขึ้น DeepSeek-VL2 เวอร์ชันในอนาคตจะสามารถสร้างเกณฑ์มาตรฐานใหม่สำหรับประสิทธิภาพของ AI ภาษาวิสัยทัศน์ได้

