Forskare vid Tencent AI Lab har avslöjat ett nytt AI-ramverk utformat för att krossa hastighetsgränserna för nuvarande stora språkmodeller.
Detaljerad i en tidning som publicerades på nätet denna vecka kallas systemet CALM, för kontinuerliga autoregressiva språkmodeller. Det utmanar direkt den långsamma, token-by-token-process som driver den mest generativa AI idag.
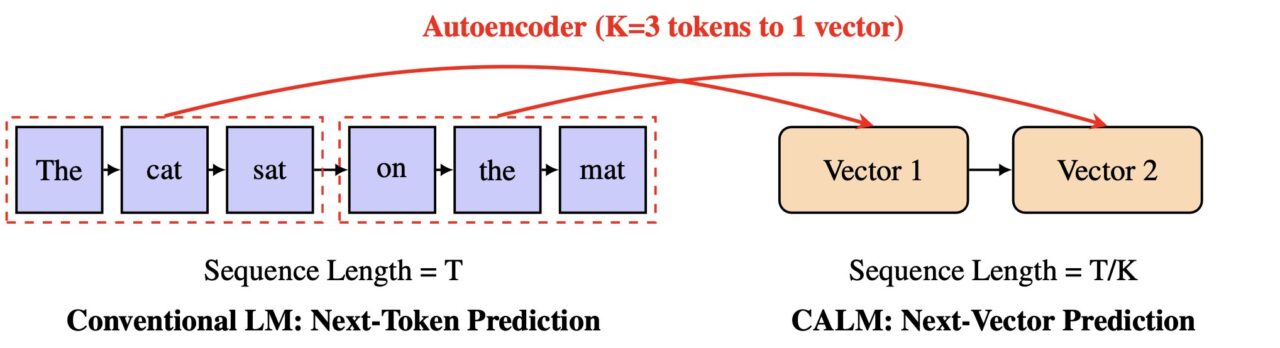
Istället för att förutsäga en liten bit av ett ord i taget, lär sig CALM att förutsäga en enda vektor som representerar en hel bit av text. Den här metoden skulle kunna göra AI-generering mycket snabbare och effektivare, vilket öppnar en ny väg för skalning av modeller.
Det här effektivitetsproblemet har blivit en central kampplats för AI-utvecklare. Som Google Research tidigare noterat, “när vi distribuerar dessa modeller till fler användare, är det en avgörande utmaning att göra dem snabbare och billigare utan att offra kvalitet.”
Branschen har utforskat många lösningar, från Googles spekulativa kaskader till nya komprimeringstekniker. Nu föreslår Tencents arbete en mer radikal lösning.
Tidningen föreslår en ritning för en ny klass av ultraeffektiva språkmodeller och till den tokeninducerade flaskhalsen för hastighet.
Målet är att i grunden förändra enheten för förutsägelse från ett enda token med låg information till något mycket rikare.
I en direkt utmaning mot status quo för generativ AI, omarbetar CALM prediktionsuppgiften helt. Forskarna föreslår en ny skalningsaxel för LLM:er.
“Vi hävdar att för att övervinna denna flaskhals krävs en ny designaxel för LLM-skalning: att öka den semantiska bandbredden för varje generativt steg”, skriver de i tidningen.
Genom att öka denna”semantiska bandbredd”, kan modellen bearbeta mer information i en enda steg. CALM uppnår detta genom en innovativ tvåstegsprocess som arbetar i ett kontinuerligt, snarare än diskret, utrymme.
Hjärtat i CALMs design är en högfientlig autokodare. Den här komponenten lär sig att komprimera en bit av K tokens – till exempel fyra tokens – till en enda, tät kontinuerlig vektor.
Det är avgörande att den kan rekonstruera de ursprungliga tokens från denna vektor med över 99,9 % noggrannhet. En separat språkmodell utför sedan autoregressiv förutsägelse i detta nya vektorutrymme.
Enligt projektets officiella dokumentation,”istället för att förutsäga en diskret token åt gången, lär sig CALM att förutsäga en hel kontinuerlig vektor som representerar Kp>.”minskar antalet generativa steg med en faktor K, vilket leder till betydande effektivitetsvinster.
The Likelihood-Free Toolkit: How CALM Learns and Measures Success
Att flytta från diskreta tokens till kontinuerliga vektorer introducerar en stor utmaning: modellen kan inte längre beräkna en explicit sannolikhetsfördelning över ett standardpmax-mjukt lager.
Detta gör traditionella utbildnings-och utvärderingsmetoder, som bygger på beräkning av sannolikheter, otillämpliga. För att lösa detta utvecklade Tencent-teamet ett omfattande ramverk utan sannolikhet.
För utbildning använder CALM en energibaserad träningsmetod, som använder en strikt korrekt poängregel för att styra modellen utan att behöva beräkna sannolikheter.
För utvärdering introducerade forskarna ett nytt mått kallat BrierLM. BrierLM flyttar sig bort från traditionella mätvärden som förvirring och härleds från Brier-poängen, ett verktyg från probabilistiska prognoser.
Det möjliggör en rättvis, urvalsbaserad jämförelse av modellkapacitet genom att kontrollera hur väl förutsägelser överensstämmer med verkligheten, en metod som är perfekt lämpad för modeller där sannolikheterna är svårlösta.
för effektivitet
Den praktiska effekten av den här nya arkitekturen är en överlägsen avvägning mellan prestanda och beräkningar.
CALM-modellen minskar utbildningsberäkningskraven med 44 % och slutsatserna med 33 % jämfört med en stark baslinje. Detta visar att skalning av den semantiska bandbredden för varje steg är en kraftfull ny hävstång för att förbättra beräkningseffektiviteten.
Arbetet positionerar CALM som en betydande utmanare i det branschomfattande kapplöpningen att bygga snabbare, billigare och mer tillgänglig AI.
Google har tacklat AI-hastighetsproblemet med metoder som spekulativa kaskader. Andra startups, som Inception, utforskar helt andra arkitekturer som diffusionsbaserade LLM:er i dess “Mercury Coder” för att undkomma autoregressionens”strukturella flaskhals”.
Tillsammans belyser dessa olika tillvägagångssätt utvecklingen. Branschen går från ett rent fokus på skala till en mer hållbar strävan efter smartare, mer ekonomiskt gångbar artificiell intelligens. CALMs vektorbaserade tillvägagångssätt erbjuder en ny väg framåt på den fronten.