DeepSeek har lanserat sina senaste AI-modeller med öppen källkod, DeepSeek-R1 och DeepSeek-R1-Zero, som omdefinierar hur resonemangsförmåga kan uppnås genom förstärkningsinlärning (RL).
De nya modellerna utmanar konventionell AI-utveckling genom att bevisa att övervakad finjustering (SFT) är inte nödvändigt för att odla avancerade problemlösningsförmåga. Med benchmarkresultat som konkurrerar med proprietära system som OpenAI:s o1-serie, illustrerar DeepSeeks modeller den växande potentialen hos öppen källkod AI för att leverera konkurrenskraftiga, högpresterande verktyg.
Framgången för dessa modeller ligger i deras unika tillvägagångssätt för förstärkning. Lärande (RL), införandet av kallstartsdata och en effektiv destillationsprocess. Dessa innovationer har skapat resonemangsmöjligheter inom kodning, matematik och allmänna logiska uppgifter, vilket understryker lönsamheten hos öppen källkod AI som en konkurrent till ledande proprietära modeller.
Benchmark Results Highlight Open-Source Potential
DeepSeek-R1:s prestanda bekräftade i stor utsträckning dess riktmärke funktioner:
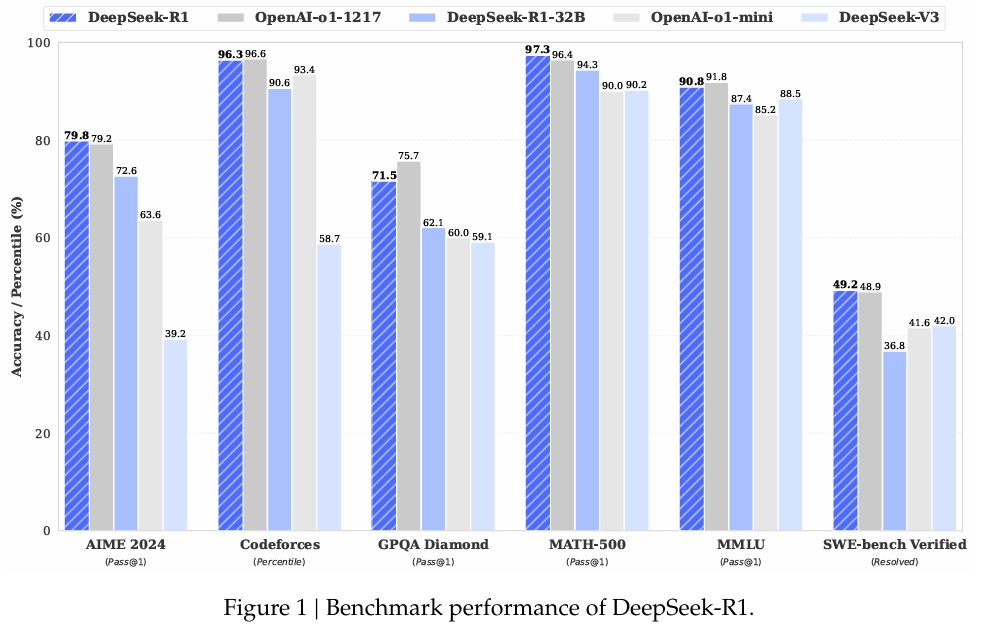
In MATH-500, en datauppsättning designad för att utvärdera matematisk problemlösning, DeepSeek-R1 uppnådde ett Pass@1-poäng på 97,3 %, vilket matchade OpenAI:s o1-1217-modell. På AIME 2024-riktmärket, som fokuserar på avancerade resonemangsuppgifter, fick modellen 79,8 %, något bättre än OpenAI:s resultat.
Modellens prestanda i LiveCodeBench, ett riktmärke för kodnings-och logikuppgifter, var lika anmärkningsvärt, med ett Pass@1-CoT-poäng på 65,9 %. Enligt DeepSeeks forskning gör detta den till en av de bästa bland modellerna med öppen källkod i denna kategori.
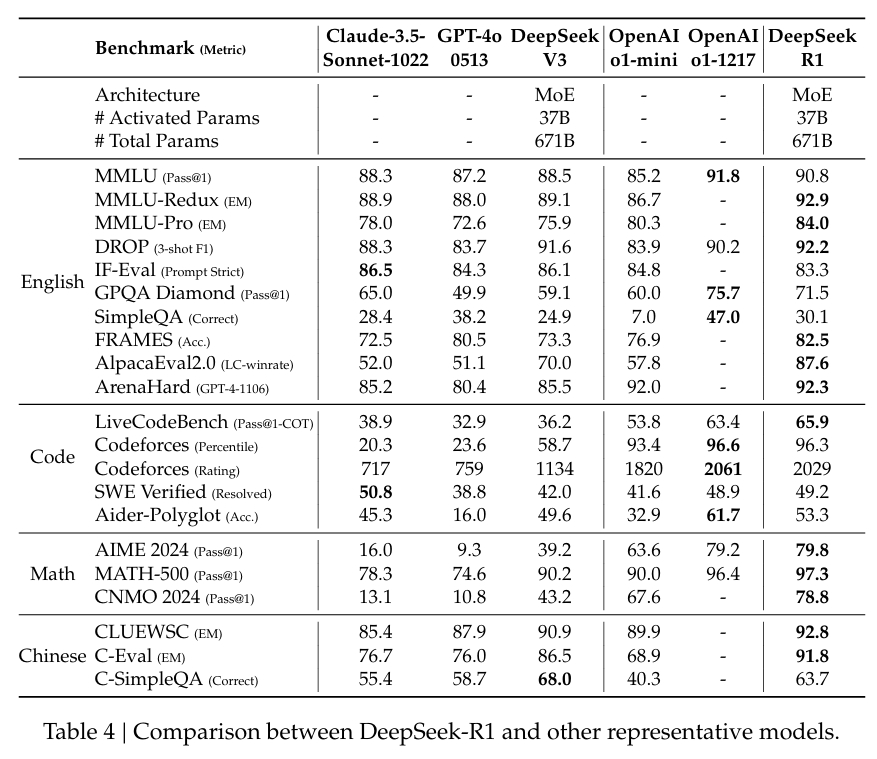
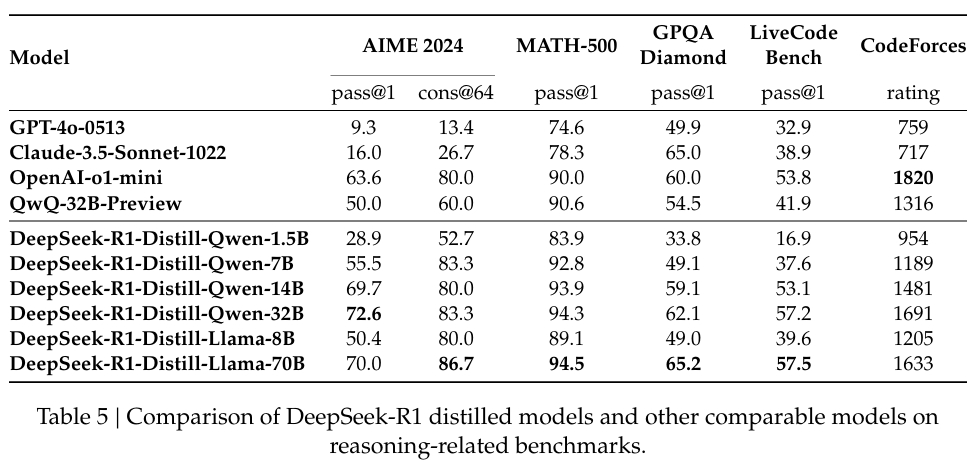
Företaget har också investerat tungt i destillation, vilket säkerställer att mindre versioner av DeepSeek-R1 behåller mycket av resonemangskapaciteten hos de större modellerna. Noterbart är att modellen med 32 miljarder parametrar, DeepSeek-R1-Distill-Qwen-32B, överträffade OpenAI:s o1-mini i flera kategorier samtidigt som den var mer beräkningsmässigt tillgänglig.
Förstärkt lärande utan övervakning: DeepSeek-R1-Zero
DeepSeek-R1-Zero är företagets djärva försök att utforska RL-enbart utbildning. Den använder en unik algoritm, Group Relative Policy Optimization (GRPO), som effektiviserar RL-utbildning genom att eliminera behovet av en separat kritikermodell.
Istället använder den grupperade poäng för att uppskatta baslinjer, vilket avsevärt minskar beräkningskostnaderna samtidigt som utbildningskvaliteten bibehålls. Detta tillvägagångssätt gör det möjligt för modellen att utveckla resonemangsbeteenden, inklusive tankekedja (CoT) resonemang och självreflektion.
I deras forskningsuppsats, DeepSeek-teamet sa:
“DeepSeek-R1-Zero demonstrerar funktioner som självverifiering, reflektion och generering av långa CoTs. Den kämpar dock med upprepning, läsbarhet och språkblandning, vilket gör den mindre lämplig för verkliga användningsfall.”
Även om dessa framväxande beteenden var lovande, visade modellens begränsningar behovet av förfining. Till exempel , dess utdata var ibland repetitiva eller visade problem med blandade språk, vilket minskade användbarheten i praktiska scenarier.
Från RL-Endast till Hybridträning: DeepSeek-R1
För att möta dessa utmaningar utvecklade DeepSeek DeepSeek-R1, som kombinerade RL med övervakad finjustering. Processen började med en kurerad kallstartsdatauppsättning av långa, mänskliga-läsbara CoTs utformade för att förbättra grundlinjekoherens och läsbarhet Genom att träna på denna grund kom modellen in i RL med en förbättrad förmåga att möta mänskliga förväntningar på tydlighet och. relevans.
DeepSeek beskrev detta tillvägagångssätt i sin dokumentation:
“Till skillnad från R1-Zero, för att förhindra den tidiga instabila kallstartfasen av RL-träning från basmodellen, för R1 konstruerar och samlar vi in en liten mängd långa CoT-data för att finjustera modellen som den ursprungliga RL-aktören.”
Piplinen inkluderade också iterativ RL för att förfina resonemang och problemlösningsförmåga ytterligare, producerar en modell som kan hantera komplexa scenarier som kodning och matematiska bevis.
Tillgänglighet med öppen källkod och framtida utmaningar
DeepSeek har släppt sina modeller under MIT-licens, som betonar dess engagemang för principer om öppen källkod. Denna licensmodell tillåter forskare och utvecklare att fritt använda, modifiera och bygga vidare på DeepSeeks arbete, vilket främjar samarbete och innovation inom AI-gemenskapen.
Trots framgångarna, erkänner teamet att utmaningarna kvarstår. Blandade språkutgångar, snabb känslighet och behovet av bättre mjukvaruteknik är områden för förbättring. Framtida iterationer av DeepSeek-R1 kommer att syfta till att ta itu med dessa begränsningar samtidigt som den utökar dess funktionalitet till nya domäner.
Forskarna har uttryckt optimism om deras framsteg och säger:
“Genom att noggrant utforma mönstret för kyla-startdata med mänskliga tidigare, vi observerar bättre prestanda mot DeepSeek-R1-Zero. Vi tror att den iterativa träningen är ett bättre sätt att resonera modeller.”
Konsekvenser för AI-industrin
DeepSeeks arbete signalerar en förändring i AI-forskningslandskapet , där modeller med öppen källkod nu kan konkurrera med egna ledare genom att bevisa att RL kan uppnå resonemang på hög nivå utan SFT och betona destillation för att skala tillgänglighet, DeepSeek har satt ett riktmärke för framtida AI-forskning.
I takt med att AI med öppen källkod fortsätter att utvecklas ger DeepSeek-R1s framsteg en plan för att utnyttja RL för att producera praktiska, högpresterande modeller. Företagets engagemang för transparens och samarbete säkerställer att denna utveckling kommer att gynna både AI-forskare och branschfolk.