Mark Russinovich, Chief Technology Officer för Microsoft Azure, har lyft fram de växande säkerhetsproblemen i samband med generativ AI. När han talade vid Microsoft Build 2024-konferensen i Seattle, underströk Russinovich de olika en rad hot som Chief Information Security Officers (CISO) och utvecklare måste navigera när de integrerar generativ AI-teknik. Han betonade nödvändigheten av ett tvärvetenskapligt tillvägagångssätt för AI-säkerhet, som inkluderar att granska hot från olika vinklar såsom AI-applikationer, underliggande modellkod, API-förfrågningar, utbildningsdata och potentiella bakdörrar.
Dataförgiftning. och felklassificering av modeller
En av de primära problemen som Russinovich tog upp är dataförgiftning. I dessa attacker manipulerar motståndare de datauppsättningar som används för att träna AI eller maskininlärningsmodeller, vilket leder till korrupta utdata. Han illustrerade detta med ett exempel där digitalt brus lagt till en bild fick AI:n att felklassificera en panda som en apa. Den här typen av attack kan vara särskilt lömsk eftersom till och med en mindre ändring, till exempel en bakdörrsinsättning, avsevärt kan påverka modellens prestanda.
Russinovich diskuterade också frågan om bakdörrar inom AI-modeller. Även om de ofta ses som en sårbarhet, kan bakdörrar också tjäna till att verifiera en modells äkthet och integritet. Han förklarade att bakdörrar kunde användas för att fingeravtrycka en modell, vilket gör det möjligt för programvara att kontrollera dess äkthet. Detta innebär att man lägger till unika frågor till koden som sannolikt inte kommer att ställas av riktiga användare, vilket säkerställer modellens integritet.
Snabbinsprutningstekniker
Ett annat betydande hot som Russinovich lyfte fram är tekniker för snabbinsprutning. Dessa involverar att infoga dolda texter i dialoger, vilket kan leda till dataläckor eller påverka AI-beteende utöver dess avsedda verksamhet. Vi har sett hur OpenAI:s GPT-4 V är sårbar för denna typ av attack. Han demonstrerade hur en bit dold text som injiceras i en dialog kan resultera i läckande privata data, liknande skriptexploateringar på flera webbplatser inom webbsäkerhet. Detta kräver att användare, sessioner och innehåll isoleras från varandra för att förhindra sådana attacker.
I spetsen för Microsofts oro är frågor relaterade till avslöjande av känslig data, jailbreaking-tekniker för att köra om AI-modeller och tvingande av tredje man-partsapplikationer och modellinsticksprogram för att kringgå säkerhetsfilter eller producera begränsat innehåll. Russinovich nämnde en specifik attackmetod, Crescendo, som kan kringgå säkerhetsåtgärder för innehåll för att få en modell att generera skadligt innehåll.
Holistisk syn på AI-säkerhet
Russinovich liknade AI-modeller vid”riktigt smarta men juniora eller naiva anställda”som, trots sin intelligens, är sårbara för manipulation och kan agera mot en organisations policy utan strikt övervakning. Han betonade de inneboende säkerhetsriskerna inom stora språkmodeller (LLM) och behov av stränga skyddsräcken för att mildra dessa sårbarheter.
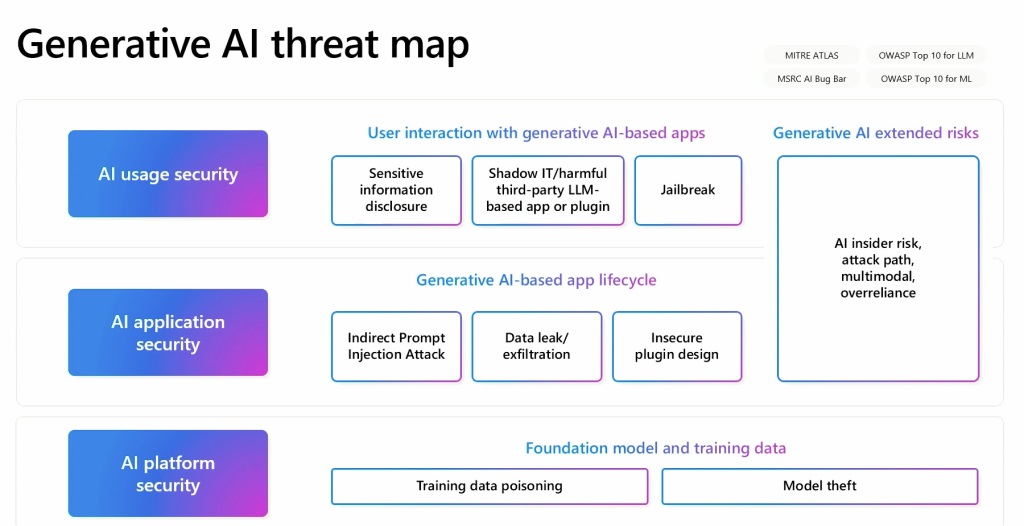
Russinovich har utvecklat en generativ AI-hotkarta som beskriver relationerna mellan dessa olika element. Denna karta fungerar som ett avgörande verktyg för att förstå och hantera AI-säkerhetens mångfacetterade natur hot Han gav ett exempel på hur att plantera förgiftade data på en Wikipedia-sida, som är känd för att vara en datakälla, kan leda till långsiktiga problem även om data korrigeras. Detta gör det svårt att spåra förgiftade data finns i originalkällan.