Google DeepMind ka lançuar FACTS Grounding, një standard i ri i krijuar për të testuar modele të mëdha gjuhësore (LLM) mbi aftësinë e tyre për të gjeneruar përgjigje faktike të sakta, të bazuara në dokumente.
Repertimi, i strehuar në Kaggle, synon të trajtojë një nga sfidat më të ngutshme në inteligjenca artificiale: sigurimi që rezultatet e AI janë të bazuara në të dhënat e ofruara atyre, në vend që të mbështeten në njohuritë e jashtme ose të prezantojnë halucinacione-të mundshme por të pasakta informacion.
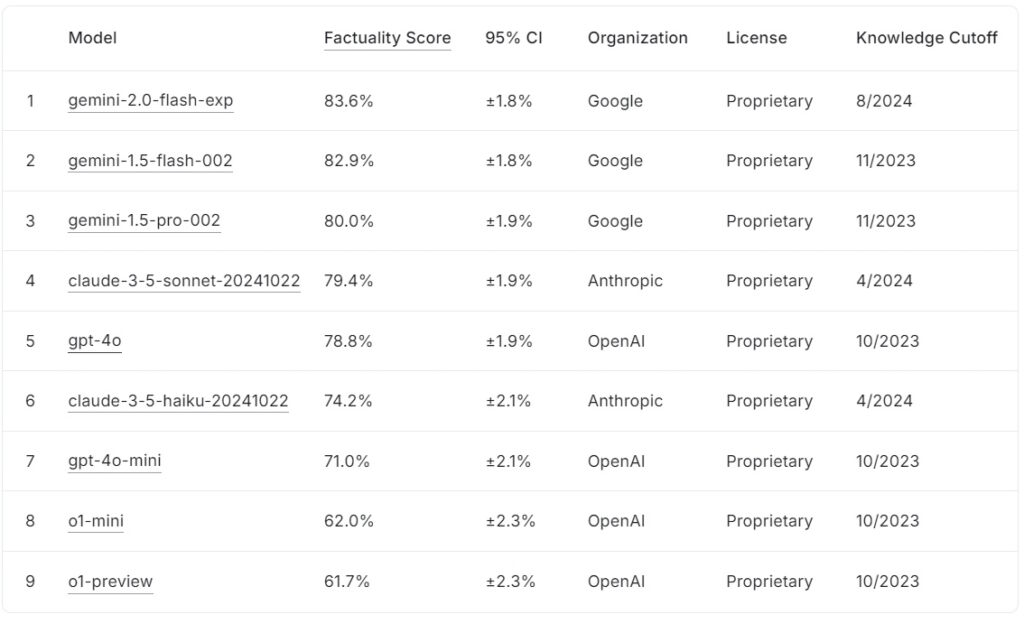
FACTS Grounding leaderboard aktual i rendit modelet e mëdha gjuhësore bazuar në rezultatet e tyre të faktit, me Google gemini-2.0-flash-exp kryeson me 83.6% e ndjekur nga afër nga gemini-1.5-flash-002 në 82.9%, dhe gemini-1.5-pro-002 në 80.0%.
Anthropic’s claude-3.5-sonnet-22>20 renditet e katërta me 79.4%, ndërsa gpt-4o i OpenAI arrin 78.8%, duke e vendosur atë në vendin e pestë. Më poshtë në listë, Anthropic’s claude-3.5-haiku-20241022 shënon 74.2%, e ndjekur nga gpt-4o-mini me 71.0%.
Modelet më të vogla të OpenAI, o1-mini dhe o1-preview, përfundojnë tabelën e liderëve në 62.0% dhe 61.7%përkatësisht.
 Burimi: Kaggle
Burimi: Kaggle
FAKTET Bazat qëndron veçmas nga duke kërkuar përgjigje të gjata që sintetizojnë dokumente hyrëse të detajuara, duke e bërë atë një nga standardet më rigoroze për faktin e AI deri më tani.
FAKTET Tokëzimi përfaqëson një zhvillim kritik për industrinë e AI, veçanërisht në aplikacionet ku besueshmëria dhe saktësia janë të vërteta. janë thelbësore. Duke vlerësuar LLM-të në fusha të tilla si mjekësia, ligji, financat, shitja me pakicë dhe teknologjia, standardi vendos bazën për besueshmërinë e përmirësuar të AI në skenarët e botës reale.
Sipas ekipit hulumtues të DeepMind,”pika referuese mat aftësinë e LLM-ve për të gjeneruar përgjigje të bazuara ekskluzivisht në kontekstin e dhënë… edhe kur konteksti bie ndesh me njohuritë e para-trajnimit.”
Grupi i të dhënave për kompleksitetin e botës reale
FAKTET Bazamenti përbëhet nga 1719 shembuj, të kuruar nga njeriu Annotators për të siguruar rëndësinë dhe diversitetin Këta shembuj janë nxjerrë nga dokumente të detajuara që përfshijnë deri në 32,000 argumente, ekuivalente me afërsisht 20,000 fjalë
Çdo detyrë sfidon LLM-të të kryejnë përmbledhjen, gjenerimin e pyetjeve dhe përgjigjeve ose rishkrimin e përmbajtjes. udhëzime strikte për t’iu referuar vetëm të dhënave të dhëna Standardi i referimit shmang detyrat që kërkojnë kreativitet. arsyetimi matematik ose interpretimi ekspert, duke u fokusuar në vend të kësaj në testimin e aftësisë së një modeli për të sintetizuar dhe artikuluar informacione komplekse.
Për të ruajtur transparencën dhe për të parandaluar mbipërshtatjen, DeepMind ndau grupin e të dhënave në dy segmente: 860 shembuj publikë të disponueshëm për përdorim të jashtëm. dhe 859 shembuj privatë të rezervuar për vlerësimet e tabelës së drejtuesve.
Kjo strukturë e dyfishtë mbron integritetin e standardit duke inkurajuar bashkëpunimin nga zhvilluesit e AI në mbarë botën.”Ne i vlerësojmë me rigorozitet vlerësuesit tanë automatikë në të dhënat e testit të mbajtura për të vërtetuar performancën e tyre në detyrën tonë,”vëren ekipi hulumtues, duke theksuar dizajnin e kujdesshëm që mbështet FAKTET në tokë.
Gjykimi i saktësisë me kolegët. Modelet e AI
Ndryshe nga standardet konvencionale, FACTS Grounding përdor një proces rishikimi nga kolegët që përfshin tre LLM-të e avancuara: Gemini 1.5 Pro, GPT-4o dhe Claude 3.5 Sonet konfirmoni se ata adresojnë pyetjen e përdoruesit në mënyrë kuptimplote. Ata që kualifikohen më pas vlerësohen për bazën e tyre në materialin burimor, me pikë agreguar në të tre modelet për të minimizuar paragjykimet.
Kërkuesit e DeepMind theksojnë rëndësinë e këtij vlerësimi me shumë shtresa, duke deklaruar,”Metrikat që janë të përqendruara në vlerësimin e faktit të tekstit të krijuar…mund të anashkalohen duke injoruar synimi pas kërkesës së përdoruesit. Duke dhënë përgjigje më të shkurtra që shmangin përcjelljen e informacionit gjithëpërfshirës…është e mundur të arrihet një rezultat i lartë i fakteve duke mos dhënë një përgjigje të dobishme.”
Përdorimi i modeleve të shumëfishta të vlerësimit, duke përfshirë qasjet e nivelit të hapësirës dhe të bazuara në JSON , siguron më tej përafrimin me gjykimin njerëzor dhe përshtatshmërinë ndaj detyrave të ndryshme.
Trajtimi i Sfidës së AI-së. Halucinacionet
Halucinacionet e AI janë ndër pengesat më të rëndësishme për adoptimin e gjerë të LLM-ve në fusha kritike. si kujdesi shëndetësor, analiza ligjore dhe raportimi financiar respektimi i të dhënave hyrëse të ofruara Kjo qasje jo vetëm që vlerëson aftësinë e një modeli për të shmangur paraqitjen e gënjeshtrave, por gjithashtu siguron që rezultatet të mbeten në linjë me qëllimin e përdoruesit.
Në dallim nga standardet si SimpleQA e OpenAI, e cila mat faktin në. marrja e të dhënave të trajnimit, FAKTET Testet e argumentimit se sa mirë modelet sintetizojnë informacionin e ri.
Dokumenti kërkimor nënvizon këtë dallim: “Sigurimi i saktësisë faktike gjatë gjenerimit të përgjigjeve LLM është sfidues. Sfidat kryesore në faktin e LLM janë modelimi (d.m.th., arkitektura, trajnimi dhe konkluzioni) dhe matja (d.m.th., metodologjia e vlerësimit, të dhënat dhe metrikat).”
Sfidat teknike dhe dizajni i standardeve
Kompleksiteti i inputeve në formë të gjatë paraqet sfida teknike unike, veçanërisht në hartimin e metodave të automatizuara të vlerësimit që mund të vlerësojnë me saktësi të tilla Përgjigjet
FAKTET Bazamentimi mbështetet në procese kompjuterike intensive për të vërtetuar përgjigjet, duke përdorur kritere rigoroze për të siguruar besueshmërinë. Ekipi hulumtues thekson rëndësinë e skualifikimit të përgjigjeve të paqarta ose të parëndësishme, duke vënë në dukje,”Diskualifikimi i përgjigjeve të papërshtatshme çon në një reduktim…pasi këto përgjigje trajtohen si të pasakta.”Ky zbatim i rreptë i rëndësisë siguron që modelet të mos shpërblehen për anashkalimin e frymës së detyrës.
Inkurajimi i bashkëpunimit përmes transparencës
Vendimi i DeepMind për të organizuar FACTS Grounding. në Kaggle pasqyron angazhimin e saj për të nxitur bashkëpunimin në të gjithë industrinë e AI. Duke e bërë të aksesueshëm segmentin publik të grupit të të dhënave, projekti fton studiuesit dhe zhvilluesit e AI që të vlerësojnë modelet e tyre kundrejt një standardi të fortë dhe të kontribuojnë në avancimin e standardeve të faktit.
Kjo qasje përputhet me qëllimet më të gjera të transparencës dhe përparimit të përbashkët në AI, duke siguruar që përmirësimet në saktësi dhe bazë të mos kufizohen në një organizatë të vetme.
Dallimi nga të tjerat. Standardet
FAKTET Tokëzimi dallon veten nga standardet e tjera nga fokusi i tij në tokëzimin në hyrjet e reja të prezantuara rishtazi sesa njohuri të trajnuara paraprakisht.
Ndërsa standardet si SimpleQA e OpenAI vlerësojnë se sa mirë një model merr dhe përdor informacion nga korpusi i tij i trajnimit, FACTS Grounding vlerëson modelet mbi aftësinë e tyre për të sintetizuar dhe artikuluar përgjigjet bazuar ekskluzivisht në të dhënat e ofruara.
Siç shpjegon DeepMind në punimin e tij kërkimor, pikë referimi është krijuar për të vlerësuar LLM-të mbi aftësinë e tyre për të menaxhuar pyetje komplekse, të gjata me bazë faktike, duke simuluar detyra të rëndësishme për aplikacionet e botës reale.
Metodat alternative për tokëzimin e LLM-ve
Disa metoda ofrojnë karakteristika të ngjashme të tokëzimit me FAKTET Tokëzimi, secila me pikat e forta dhe të dobëta. Këto metoda synojnë të përmirësojnë rezultatet e LLM ose duke përmirësuar aksesin e tyre ndaj informacionit të saktë ose duke rafinuar proceset e tyre të trajnimit dhe shtrirjes.
Rikthim-Gjenerimi i Shtuar (RAG)
>Retrieval-Augmented Generation (RAG) përmirëson saktësia e rezultateve të LLM duke tërhequr në mënyrë dinamike informacionin përkatës nga bazat e jashtme të njohurive ose bazat e të dhënave dhe duke e përfshirë atë në përgjigjet e modelit. Në vend që të ritrajnojë të gjithë LLM-në, RAG funksionon duke përgjuar kërkesat e përdoruesve dhe duke i pasuruar ato me informacione të përditësuara.
Zbatimet e avancuara të RAG-së shpesh përdorin rikthimin e bazuar në entitete, ku të dhënat e lidhura me entitete specifike unifikohen për të ofrojnë një kontekst shumë të rëndësishëm për përgjigjet LLM.
RAG zakonisht përdor teknika kërkimi semantike për marrjen e informacionit. Dokumentet ose fragmentet e tyre indeksohen bazuar në ngulitjet e tyre semantike, duke lejuar sistemin të përputhet me pyetjen e përdoruesit me hyrjet më të rëndësishme në kontekst. Kjo qasje siguron që LLM-të të gjenerojnë përgjigje të informuara nga të dhënat më të fundit dhe më përkatëse.
Efektshmëria e RAG varet shumë nga cilësia dhe organizimi i bazës së njohurive, si dhe nga saktësia e algoritmeve të marrjes. Ndërsa FACTS Grounding vlerëson aftësinë e një LLM për të qëndruar e ankoruar në një dokument konteksti të ofruar, RAG e plotëson këtë duke u mundësuar LLM-ve të zgjerojnë njohuritë e tyre në mënyrë dinamike, duke u mbështetur nga burime të jashtme për të rritur faktin dhe rëndësinë.
Distilimi i njohurive.
Distilimi i njohurive.
Distilimi i njohurive përfshin transferimin e aftësive të një modeli të madh, kompleks (të referuar si mësuesi) në një model më të vogël, specifik për detyrën ( studenti). Kjo metodë përmirëson efikasitetin duke ruajtur shumë nga saktësia e modelit origjinal. Dy qasje kryesore përdoren në distilimin e njohurive:
Distilimi i njohurive të bazuara në përgjigje: Përqendrohet në përsëritjen e rezultateve të modelit të mësuesit, duke siguruar që modeli i studentit të prodhojë rezultate të ngjashme për inputet e dhëna.
Distilimi i njohurive të bazuara në veçori: Nxjerrë paraqitjet dhe veçoritë e brendshme nga modeli i mësuesit, duke i lejuar modelit të nxënësit të përsëritni njohuri më të thella.
Duke rafinuar modele më të vogla, distilimi i njohurive mundëson vendosjen e LLM-ve në mjedise me burime të kufizuara pa humbje të konsiderueshme në performancë. Ndryshe nga FACTS Grounding, i cili vlerëson besnikërinë e tokëzimit, distilimi i njohurive ka të bëjë më shumë me shkallëzimin e aftësive LLM dhe optimizimin e tyre për detyra specifike.
Rregullimi i saktë me grupet e të dhënave të bazuara
Rregullimi i hollësishëm përfshin përshtatjen e LLM-ve të trajnuara paraprakisht në fusha ose detyra specifike duke i trajnuar ato në grupe të dhënash të kuruara me bazë faktike është kritike. Për shembull, grupet e të dhënave që përmbajnë literaturë shkencore ose regjistrime historike mund të përdoren për të përmirësuar aftësinë e modelit për të prodhuar rezultate të sakta dhe specifike për domenin. Kjo teknikë rrit performancën e LLM për aplikacione të specializuara, të tilla si analiza e dokumenteve mjekësore ose ligjore.
Megjithatë, rregullimi i imët kërkon burime intensive dhe rrezikon harresën katastrofike, ku modeli humbet njohuritë e fituara gjatë trajnimit fillestar. FAKTET Grounding fokusohet në testimin e fakteve në kontekste të izoluara, ndërsa rregullimi i saktë kërkon të përmirësojë performancën bazë të LLM-ve në fusha specifike.
Mësimi përforcues me reagime njerëzore (RLHF)
Mësimi përforcues me reagime njerëzore (RLHF) përfshin preferencat njerëzore në procesin e trajnimit të LLM. Duke e trajnuar në mënyrë të përsëritur modelin për të përafruar përgjigjet e tij me reagimet njerëzore, RLHF përmirëson cilësinë, faktin dhe dobinë e rezultateve. Vlerësuesit njerëzorë shënojnë rezultatet e LLM dhe këto rezultate përdoren si sinjale për të optimizuar modelin.
RLHF ka qenë veçanërisht i suksesshëm në rritjen e kënaqësisë së përdoruesit dhe sigurimin që përgjigjet e gjeneruara të jenë në përputhje me pritjet njerëzore. Ndërsa FACTS Grounding vlerëson bazat faktike kundrejt dokumenteve specifike, RLHF thekson përafrimin e rezultateve të LLM me vlerat dhe preferencat njerëzore.
Ndjekja e udhëzimeve dhe mësimi në kontekst
Ndjekja e udhëzimeve dhe të mësuarit në kontekst përfshin demonstrimin e bazës për LLM-të përmes shembujve të hartuar me kujdes brenda kërkesës së përdoruesit. Këto metoda mbështeten në aftësinë e modelit për të përgjithësuar nga një demonstrim me disa goditje. Ndërsa kjo qasje mund të sjellë përmirësime të shpejta, ajo mund të mos arrijë të njëjtin nivel të cilësisë së tokëzimit si metodat e rregullimit të imët ose të bazuara në rikthim.
Mjetet e jashtme dhe API-të
LLM-të mund të integrohen me mjete të jashtme dhe API për të ofruar qasje në kohë reale në të dhënat e jashtme, duke rritur ndjeshëm aftësitë e tyre të tokëzimit. Shembujt përfshijnë:
Aftësia e shfletimit: U mundëson LLM-ve të aksesojnë dhe të marrin informacion në kohë reale nga ueb-i për t’iu përgjigjur pyetjeve specifike ose për të përditësuar njohuritë e tyre.
Thirrjet API: Lejon LLM-të të ndërveprojnë me bazat e të dhënave ose shërbimet e strukturuara, duke pasuruar përgjigjet me informacione të sakta dhe të përditësuara.
Këto mjete zgjerojnë dobinë e LLM duke i lidhur ato me burimet e njohurive të botës reale, duke përmirësuar aftësinë e tyre për të gjeneruar rezultate të sakta dhe të bazuara. Ndërsa FACTS Grounding vlerëson besnikërinë e brendshme të tokëzimit, mjetet e jashtme ofrojnë një mjet alternativ për zgjerimin dhe verifikimin e faktit.
Open-Source Modeling Grounding Opsionet
Disponohen disa zbatime me burim të hapur për metodat alternative të tokëzimit të diskutuara më sipër:
MethodOpen-Source OptionsDescriptionRetrieval-Augmented Generation (RAG)LangChainSiguron një bazë gjithëpërfshirëse për ndërtimin e aplikacioneve me LLM, duke kombinuar një dizajn modular dhe fleksibël me një ndërfaqe të nivelit të lartë.LlamaIndexPërqendrohet në efikasitetin indeksimi dhe marrja nga grupe të dhënash masive duke përdorur teknika të avancuara si kërkimi i ngjashmërive vektoriale dhe indeksimi hierarkik.RAGFlowOfron një rrjedhë pune të efektshme RAG për bizneset e çdo shkalle , duke kombinuar LLM-të për të ofruar aftësi të vërteta për t’iu përgjigjur pyetjeve me citime nga të dhëna të ndryshme të formatuara komplekse.txtaiNjë motor kërkimi i fuqizuar nga AI që mundëson kërkimin semantik, përgjigjen e pyetjeve dhe përmbledhjen mbi burime të ndryshme të të dhënave.SWIRLNjë softuer i infrastrukturës së AI me burim të hapur që përmirëson tubacionet e AI duke mundësuar kërkime të shpejta dhe të sigurta nëpër burimet e të dhënave pa lëvizja ose kopjimi i të dhënave.CognitaNjë kornizë me burim të hapur për ndërtimin e sistemeve RAG modulare, të gatshme për prodhim, me një ndërfaqe për përdoruesit jo teknikë.LLM-WareNjë kuadër për ndërtimin e aplikacioneve të mbështetura nga LLM me fokus mbi modularitetin dhe shkallëzueshmërinë. Distilimi i njohuriveDistillersNjë platformë gjithëpërfshirëse zbatimi për metoda të ndryshme të distilimit të njohurive, duke përfshirë distilimin me konsistencë të pandryshueshme (ICD) dhe përfaqësimin relacional Distilimi (RRD).TextBrewerNjë paketë mjetesh distilimi me burim të hapur për përpunimin e gjuhës natyrore me mbështetje për metoda dhe konfigurime të ndryshme distilimi.KD-LibNjë bibliotekë me burim të hapur të bazuar në PyTorch me implementime modulare moderne të algoritmeve të distilimit të njohurive.knowledge-distillation-pytorchNjë zbatim i PyTorch për eksplorimin e eksperimenteve të distilimit të njohurive të thella dhe të cekëta me fleksibilitet. Rregullimi i imët me grupe të dhënash të bazuaraMM-Grounding-DINONjë burim i hapur, gjithëpërfshirës dhe miqësor për përdoruesit tubacion për modelet e zbulimit të objekteve të tokëzimit, i ndërtuar me kutinë e veglave MMDetection.LLaMA-FactoryNjë bibliotekë gjithëpërfshirëse për rregullimin e modeleve të gjuhës LLaMA, duke mbështetur qasje dhe teknika të ndryshme trajnimi.Saktonizimi i mirë i vetë-luajtjes (SPIN)Një kornizë me burim të hapur për akordimin e LLM-ve për gjenerimi i teksteve të bazuara me fokus në përmirësimin e koherencës dhe saktësisë faktike.
Ndikimet për aplikacionet me aksione të larta
Rëndësia e përgjigjeve të sakta dhe të bazuara në AI bëhet veçanërisht e veçantë. evidente në aplikimet me aksione të larta, të tilla si diagnostifikimi mjekësor, rishikimet ligjore dhe analizat financiare. Në këto kontekste, edhe pasaktësitë e vogla mund të çojnë në pasoja të rëndësishme, duke e bërë besueshmërinë e rezultateve të gjeneruara nga AI një kërkesë e panegociueshme.
FAKTE Theksi i Grounding mbi faktin dhe respektimin e materialit burimor siguron që modelet të testohen në kushte që pasqyrojnë nga afër kërkesat e botës reale.
Për shembull, në kontekstet mjekësore, një LLM e ngarkuar me detyrën me përmbledhja e të dhënave të pacientit duhet të shmangë paraqitjen e gabimeve që mund të keqinformojnë vendimet e trajtimit. Në mënyrë të ngjashme, në mjediset ligjore, gjenerimi i përmbledhjeve ose analizave të praktikës gjyqësore kërkon një bazë të saktë në dokumentet e ofruara.
FAKTET Grounding jo vetëm që vlerëson modelet mbi aftësinë e tyre për të përmbushur këto kërkesa të rrepta, por gjithashtu vendos një pikë referimi për zhvilluesit që të synojnë krijimin e sistemeve të përshtatshme për aplikacione të tilla.
Zgjerimi i tyre. grupi i të dhënave FACTS dhe drejtimet e së ardhmes
DeepMind e ka pozicionuar FACTS Grounding si një”etapë e gjallë”, një që do evoluon së bashku me përparimet në AI Përditësimet e ardhshme ka të ngjarë të zgjerojnë të dhënat e reja për të përfshirë domene dhe lloje të reja detyrash, duke siguruar rëndësinë e vazhdueshme ndërsa aftësitë e LLM rriten
Për më tepër, prezantimi i modeleve më të ndryshme të vlerësimit. qëndrueshmëria e procesit të vlerësimit, duke adresuar rastet e skajshme dhe duke reduktuar paragjykimet e mbetura.
Siç është. Ekipi hulumtues i DeepMind pranon se asnjë pikë referimi nuk mund të përmbledhë plotësisht kompleksitetin e aplikacioneve të botës reale, megjithatë, duke përsëritur mbi bazën e FACTS dhe duke angazhuar komunitetin më të gjerë të AI, projekti synon të ngrejë shiritin për faktin dhe bazën në sistemet e AI.
Siç pohon ekipi i DeepMind, “Faktualiteti dhe themelimi janë ndër faktorët kryesorë që do të formësojnë suksesin dhe dobinë e ardhshme të LLM-ve dhe sistemeve më të gjera të AI, dhe ne synojmë të rritemi dhe të përsërisim FACTS Grounding ndërsa fusha përparon. duke ngritur vazhdimisht shiritin.”
Ndikimet për aplikacionet me aksione të larta
Rëndësia e përgjigjeve të sakta dhe të bazuara në AI bëhet veçanërisht e veçantë. evidente në aplikimet me aksione të larta, të tilla si diagnostifikimi mjekësor, rishikimet ligjore dhe analizat financiare. Në këto kontekste, edhe pasaktësitë e vogla mund të çojnë në pasoja të rëndësishme, duke e bërë besueshmërinë e rezultateve të gjeneruara nga AI një kërkesë e panegociueshme.
FAKTE Theksi i Grounding mbi faktin dhe respektimin e materialit burimor siguron që modelet të testohen në kushte që pasqyrojnë nga afër kërkesat e botës reale.
Për shembull, në kontekstet mjekësore, një LLM e ngarkuar me detyrën me përmbledhja e të dhënave të pacientit duhet të shmangë paraqitjen e gabimeve që mund të keqinformojnë vendimet e trajtimit. Në mënyrë të ngjashme, në mjediset ligjore, gjenerimi i përmbledhjeve ose analizave të praktikës gjyqësore kërkon një bazë të saktë në dokumentet e ofruara.
FAKTET Grounding jo vetëm që vlerëson modelet mbi aftësinë e tyre për të përmbushur këto kërkesa të rrepta, por gjithashtu vendos një pikë referimi për zhvilluesit që të synojnë krijimin e sistemeve të përshtatshme për aplikacione të tilla.
Zgjerimi i tyre. grupi i të dhënave FACTS dhe drejtimet e së ardhmes
DeepMind e ka pozicionuar FACTS Grounding si një”etapë e gjallë”, një që do evoluon së bashku me përparimet në AI Përditësimet e ardhshme ka të ngjarë të zgjerojnë të dhënat e reja për të përfshirë domene dhe lloje të reja detyrash, duke siguruar rëndësinë e vazhdueshme ndërsa aftësitë e LLM rriten
Për më tepër, prezantimi i modeleve më të ndryshme të vlerësimit. qëndrueshmëria e procesit të vlerësimit, duke adresuar rastet e skajshme dhe duke reduktuar paragjykimet e mbetura.
Siç është. Ekipi hulumtues i DeepMind pranon se asnjë pikë referimi nuk mund të përmbledhë plotësisht kompleksitetin e aplikacioneve të botës reale, megjithatë, duke përsëritur mbi bazën e FACTS dhe duke angazhuar komunitetin më të gjerë të AI, projekti synon të ngrejë shiritin për faktin dhe bazën në sistemet e AI.
Siç pohon ekipi i DeepMind, “Faktualiteti dhe themelimi janë ndër faktorët kryesorë që do të formësojnë suksesin dhe dobinë e ardhshme të LLM-ve dhe sistemeve më të gjera të AI, dhe ne synojmë të rritemi dhe të përsërisim FACTS Grounding ndërsa fusha përparon. duke ngritur vazhdimisht shiritin.”