Noul model de raționament al DeepSeek numit R1 provoacă performanța ChatGPT o1 de la OpenAI – chiar dacă se bazează pe GPU-uri accelerate și un buget relativ mic.
Într-un mediu modelat de controalele exporturilor din SUA care restricționează cipurile avansate, startup-ul chinez de inteligență artificială fondat de managerul fondurilor speculative Liang Wenfeng, a arătat cum eficiența și partajarea resurselor pot propulsa dezvoltarea AI.
Avântul companiei a captat atenția cercurilor tehnologice atât din China, cât și din Statele Unite.
Legate: De ce pot aplica sancțiunile SUA Luptă pentru a reduce creșterea tehnologică a Chinei
Creșterea rapidă a DeepSeek
Călătoria lui DeepSeek a început în 2021, când Liang, cel mai cunoscut pentru fondul de tranzacționare quant High-Flyer, a început să cumpere mii de Nvidia GPU-uri.
La momentul respectiv, această mișcare părea neobișnuită. După cum unul dintre partenerii de afaceri ai lui Liang, a spus Financial Times: „Când l-am întâlnit prima dată, era un tip foarte tocilar cu o coafură groaznică care vorbea despre construirea unui grup de 10.000 de cipuri pentru a-și antrena propriile modele. Nu l-am luat în serios.”
Potrivit aceleiași surse, „Nu și-a putut articula viziunea decât să spună: vreau să construiesc asta și va fi o schimbare a jocului. Ne-am gândit acest lucru a fost posibil doar de la giganți precum ByteDance și Alibaba”.
În ciuda scepticismului inițial, Liang a rămas concentrat pe pregătirea pentru eventualele controale ale exporturilor din SUA. Această previziune i-a permis DeepSeek să asigure o aprovizionare mare de hardware Nvidia, inclusiv GPU-uri A100 și H800, înainte ca restricțiile generale să intre în vigoare.
Legate: DeepSeek AI Open Sources VL2 Series of Vision Language Modele
DeepSeek a făcut titluri de ziare dezvăluind că și-a antrenat modelul R1 cu 671 de miliarde de parametri pentru doar 5,6 milioane USD folosind 2.048 de GPU-uri Nvidia H800.
Deși performanța H800 este limitată în mod deliberat pentru piața chineză, inginerii DeepSeek au optimizat procedura de instruire pentru a obține rezultate de nivel înalt la o fracțiune din costul asociat în mod obișnuit cu modele de limbaj la scară largă.
Într-un interviu publicat de MIT Technology Review, Zihan Wang, un fost cercetător DeepSeek, descrie modul în care echipa a reușit să reducă utilizarea memoriei și cheltuielile de calcul, păstrând în același timp precizie.
El a spus că limitările tehnice i-au împins să exploreze noi strategii de inginerie, ajutându-i în cele din urmă să rămână competitivi față de laboratoarele tehnologice mai bine finanțate din SUA.
Legate: China. DeepSeek R1 Reasoning Model și OpenAI o1 Contender sunt puternic cenzurate
Rezultate excepționale la matematică și codare Benchmarks
R1 demonstrează capacități excelente în diferite benchmark-uri matematice și de codare. DeepSeek a dezvăluit că R1 a obținut 97,3% (Pass@1) la MATH-500 și 79,8% la AIME 2024.
Aceste numere rivalizează cu seria OpenAI o1, arătând modul în care optimizarea deliberată poate provoca modelele antrenate pe cipuri mai puternice.
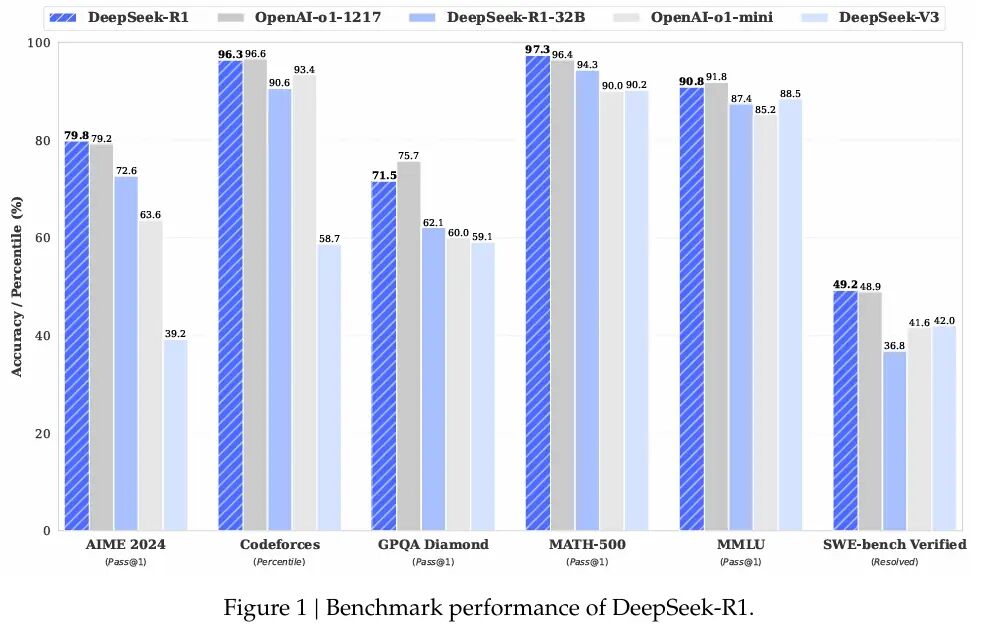
Dimitris Papailiopoulos, cercetător principal la laboratorul Microsoft AI Frontiers, a declarat pentru MIT Technology Review: „DeepSeek a urmărit mai degrabă răspunsuri precise decât să detalieze fiecare pas logic, reducând semnificativ timpul de calcul, menținând în același timp un nivel ridicat de eficacitate.”
Dincolo de modelul principal, DeepSeek a lansat versiuni mai mici ale R1 care pot rula pe hardware de calitate pentru consumatori. Aravind Srinivas, CEO al Perplexity, a scris pe Twitter în referire la variantele compacte, „DeepSeek a replicat în mare măsură o1-mini și l-a creat cu sursă deschisă.”
DeepSeek a a replicat în mare măsură o1-mini și l-a creat cu sursă deschisă. pic.twitter.com/2TbQ5p5l2c
— Aravind Srinivas (@AravSrinivas) Ianuarie 20, 2025
Raționamentul în lanț de gândire și R1-Zero
Pe lângă antrenamentul standard al lui R1, DeepSeek s-a aventurat în consolidarea pură învăţarea cu o variantă numită R1-Zero. Această abordare, detaliată în documentația de cercetare a companiei, renunță la reglarea fină supravegheată în favoarea optimizării politicilor relative de grup (GRPO).
Înlăturând un model critic separat și bazându-se pe scorurile de referință grupate, R1-Zero a afișat raționament în lanț de gândire și comportamente de auto-reflecție. Cu toate acestea, echipa a recunoscut că R1-Zero a produs rezultate repetitive sau în limbi mixte, indicând necesitatea unei supravegheri parțiale înainte de a putea fi utilizat în aplicațiile de zi cu zi.
Etosul open-source din spatele DeepSeek îl deosebește de multe laboratoare proprietare. În timp ce companiile din SUA precum OpenAI, Meta și Google DeepMind își păstrează adesea metodele de antrenament ascunse, DeepSeek își pune la dispoziție codul, greutățile modelului și rețetele de antrenament.
Legate: Mistral AI lansează Pixtral 12B pentru procesarea textului și a imaginilor
Conform lui Liang, această abordare provine din dorința de a construi o cultură de cercetare care să favorizeze transparență și progres colectiv. Într-un interviu cu instituția media chinezească 36Kr, el a explicat că multe întreprinderi chineze de inteligență artificială se luptă cu eficiența în comparație cu colegii lor occidentali, și că ameliorarea acestei decalaje necesită colaborare atât în ceea ce privește hardware-ul, cât și strategiile de formare.
Punctul său de vedere se aliniază cu alții din scena AI din China, unde lansările open-source sunt în creștere. Alibaba Cloud a introdus peste 100 de modele open-source, iar 01.AI, fondată de Kai-Fu Lee, a încheiat recent un parteneriat cu Alibaba Cloud pentru a înființa un laborator industrial de inteligență artificială.
Comunitatea tehnologică globală a răspuns cu un amestec de uimire și precauție. La X, Marc Andreessen, co-inventatorul browserului web Mosaic și acum un investitor principal la Andreessen Horowitz, a scris: „Deepseek R1 este una dintre cele mai uimitoare și impresionante descoperiri pe care le-am văzut vreodată – și, ca sursă deschisă, o sursă profundă. cadou lumii.”
Deepseek R1 este una dintre cele mai uimitoare și impresionante descoperiri pe care le-am văzut vreodată-și, așa cum open source, un cadou profund pentru lume 🤖🫡
— Marc Andreessen 🇺🇸 (@pmarca) 24 ianuarie 2025
Yann LeCun, om de știință șef AI la Meta, a remarcat pe LinkedIn că, în timp ce realizarea DeepSeek ar putea părea să indice că China depășește Statele Unite, ar fi mai corect să spunem că modelele open-source, în mod colectiv, ating alternativele proprietare.
„DeepSeek a profitat de pe urma cercetării deschise și open source (de exemplu, PyTorch și Llama de la Meta)”, a explicat el. „Au venit cu idei noi și le-au construit pe deasupra muncii altora. Deoarece munca lor este publicată și open source, toată lumea poate profita de pe urma ei. Aceasta este puterea cercetării deschise și a surselor deschise.”
Vizualizați pe fire
Chiar și Mark Zuckerberg, fondatorul și CEO-ul Meta, a sugerat o altă cale de urmat, anunțând investiții masive în centre de date și Infrastructura GPU
Pe Facebook, el a scris: „Acesta va fi un an definitoriu pentru AI. Model de vârf și vom construi un inginer AI care va începe să contribuie cu cantități tot mai mari de cod la eforturile noastre de cercetare și dezvoltare. Pentru a alimenta acest lucru, Meta construiește un 2GW+ un centru de date atât de mare încât ar acoperi o parte semnificativă din Manhattan
Vom pune online ~1 GW de calcul în’25 și vom încheia anul cu peste 1,3 milioane de GPU intenționăm să investim 60-65 de miliarde de dolari în investiții în acest an, în timp ce ne creștem semnificativ echipele AI și avem capitalul necesar pentru a continua să investim în anii următori. Acesta este un efort masiv și, în următorii ani, va conduce produsele și afacerile noastre de bază, va debloca inovația istorică și va extinde liderul tehnologic american. Haideți să construim!”
Remarcile lui Zuckerberg sugerează că strategiile care folosesc intensiv resurse rămân o forță majoră în modelarea sectorului AI.
Legate: LLaMA AI Under Fire – Ce nu vă spune Meta despre modelele „Open Source”
Extinderea impactului și perspectivelor de viitor
Pentru DeepSeek, combinația dintre talentul local, stocarea timpurie a GPU-ului și accent pe metodele open-source l-au propulsat într-un reflector rezervat de obicei marilor giganți ai tehnologiei. În iulie 2024, Liang a declarat că echipa sa și-a propus să abordeze ceea ce el a numit un decalaj de eficiență în IA chineză.
El a descris multe companii locale de inteligență artificială care necesită o putere de calcul dublă pentru a se potrivi cu rezultatele de peste mări, ceea ce agravează și mai mult atunci când se ia în considerare utilizarea datelor. permițând lui Liang și inginerilor săi să se concentreze asupra priorităților de cercetare. Liang a spus:
„Estimăm că cele mai bune modele interne și străine pot avea un decalaj de o singură parte în structura modelului și dinamica antrenamentului. Numai din acest motiv, trebuie să consumăm de două ori mai multă putere de calcul pentru a obține același efect.
În plus, poate exista și un decalaj de o singură dată în ceea ce privește eficiența datelor, adică trebuie să consumăm de două ori mai multe date de antrenament și putere de calcul pentru a obține același efect. Împreună, trebuie să consumăm de patru ori mai multă putere de calcul. Ceea ce trebuie să facem este să reducem în mod continuu aceste decalaje.”
Reputația DeepSeek în China a primit, de asemenea, un impuls atunci când Liang a devenit singurul lider AI invitat la o întâlnire de mare profil cu Li Qiang, al doilea lider din țară. cel mai puternic oficial, unde a fost îndemnat să se concentreze pe construirea tehnologiilor de bază
Analiștii văd acest lucru ca un alt semnal că Beijingul pariază puternic pe mai mici. inovatori autohtoni să depășească limitele AI sub restricții hardware.
În timp ce viitorul rămâne incert – mai ales că restricțiile din SUA se pot înăspri și mai mult – DeepSeek se remarcă prin abordarea provocărilor în moduri care transformă constrângerile în căi de rezolvare rapidă a problemelor.
Prin publicitatea descoperirilor sale și oferind tehnici de formare la scară mai mică, startup-ul a motivat discuții mai ample despre dacă eficiența resurselor poate rivaliza în mod serios cu clusterele masive de supercomputing
Pe măsură ce DeepSeek continuă să perfecționeze R1, inginerii și factorii de decizie de pe ambele maluri ale Pacificului urmăresc îndeaproape dacă realizările acestui model pot deschide o cale durabilă. AI progresează într-o eră a restricțiilor în continuă evoluție.