Cercetătorii de la Sakana AI, un startup AI cu sediul în Tokyo, au introdus un nou sistem de optimizare a memoriei care îmbunătățește eficiența modelelor bazate pe Transformer, inclusiv modele de limbaj mari (LLM).
Metoda, numită Neural Attention Memory Models (NAMMs), disponibilă prin codul de antrenament complet pe GitHub, reduce utilizarea memoriei cu până la 75%, îmbunătățind în același timp performanța generală. Concentrându-se pe token-urile esențiale și eliminând informațiile redundante, NAMM-urile abordează una dintre cele mai mari provocări în IA modernă: gestionarea ferestrelor de context lungi.
Modelele transformatoare, coloana vertebrală a LLM-urilor, se bazează pe „ferestre de context”. pentru a procesa datele de intrare. Aceste ferestre de context stochează „perechi cheie-valoare” (cache KV) pentru fiecare token din secvența de intrare.
Pe măsură ce lungimea ferestrei crește, ajungând acum la sute de mii de jetoane, costul de calcul crește vertiginos. Soluțiile anterioare au încercat să reducă acest cost prin tăierea manuală a jetoanelor sau prin strategii euristice, dar deseori au degradat performanța. Cu toate acestea, NAMM-urile folosesc rețele neuronale antrenate prin optimizarea evolutivă pentru a automatiza și rafina procesul de gestionare a memoriei.
Optimizarea memoriei cu NAMM-uri
NAMM-urile analizează valorile atenției generate de Transformers pentru a determina importanța simbolului. Ei procesează aceste valori în spectrograme-reprezentări bazate pe frecvență utilizate în mod obișnuit în procesarea audio și a semnalului-pentru a comprima și extrage caracteristicile cheie ale tiparelor de atenție.
Această informație este apoi transmisă printr-o rețea neuronală ușoară care atribuie un scor fiecărui jeton, hotărând dacă ar trebui să fie reținută sau eliminată.
Sakana AI evidențiază modul în care algoritmii evoluționari conduc NAMM-urile. succes. Spre deosebire de metodele tradiționale bazate pe gradienți, care sunt incompatibile cu decizii binare precum „amintiți-vă” sau „uita”, optimizarea evolutivă testează și perfecționează iterativ strategiile de memorie pentru a maximiza performanța în aval.
„Evoluția depășește în mod inerent nediferențiabilitatea. a operațiunilor noastre de gestionare a memoriei, care implică rezultate binare de „amintiți-vă” sau „uitați””, explică cercetătorii.
Rezultate dovedite în cadrul benchmark-urilor
Pentru a valida performanța și eficiența modelelor de memorie de atenție neuronală (NAMM), Sakana AI a efectuat teste extinse pe mai multe benchmark-uri de vârf concepute pentru a evalua procesarea în context lung și capabilitățile multi-task Rezultatele au subliniat capacitatea NAMM-urilor de a îmbunătăți semnificativ performanța, reducând în același timp cerințele de memorie, dovedind eficacitatea acestora în diverse evaluări. framework-uri.
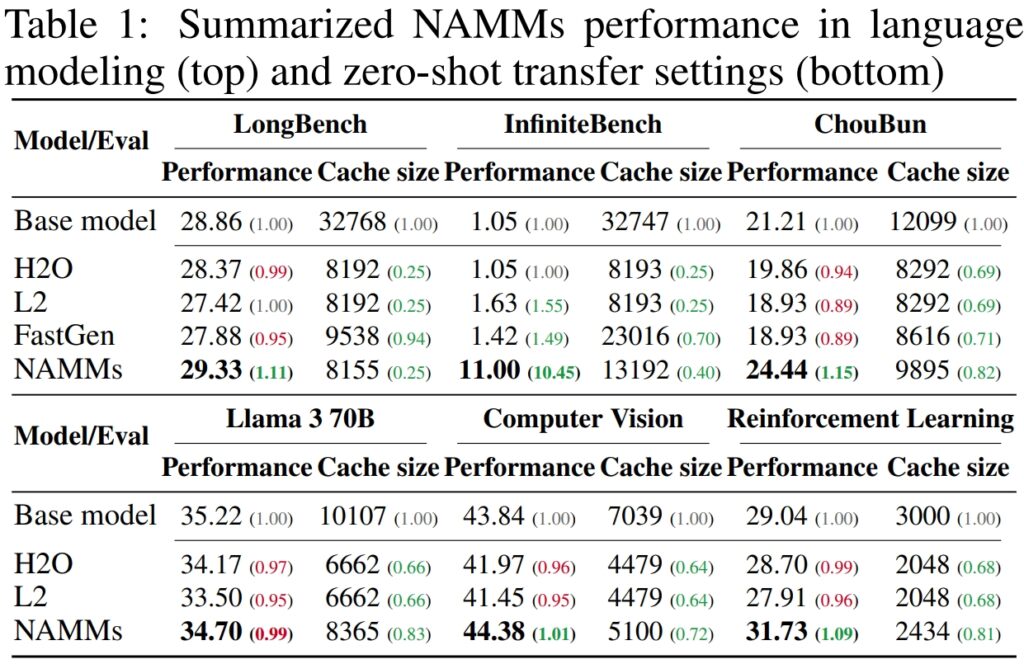
Pe LongBench, un benchmark creat special pentru a măsura performanța modelelor în sarcinile cu context lung , NAMM-urile au obținut o îmbunătățire cu 11% a preciziei în comparație cu modelul de bază în context complet. Această îmbunătățire a fost realizată în același timp cu reducerea utilizării memoriei cu 75%, evidențiind eficiența metodei în gestionarea memoriei cache-cheie-valoare (KV).
Prin tăierea inteligentă a jetoanelor mai puțin relevante, NAMM-urile au permis modelului să se concentreze pe contextul critic fără a sacrifica rezultatele, făcându-l ideal pentru scenarii care necesită intrări extinse, cum ar fi analiza documentelor sau răspunsuri lungi la întrebări.
Pentru InfiniteBench, un benchmark care împinge modelele la nivelul lor limite cu secvențe extrem de lungi—unele depășind 200.000 de jetoane—NAMM-urile și-au demonstrat capacitatea de a se scala în mod eficient.
În timp ce modelele de bază s-au luptat cu cerințele de calcul ale intrărilor atât de lungi, NAMM-urile au obținut o creștere dramatică a performanței, crescând precizia de la 1,05% la 11,00%.
Acest rezultat este deosebit de remarcabil deoarece prezintă capacitatea NAMM-urilor de a gestiona contexte ultra-lungi, o capacitate din ce în ce mai esențială pentru aplicații precum procesarea literaturii științifice, documentelor juridice sau depozitelor mari de coduri în care dimensiunile introduse de token sunt imense.
Pe propriul benchmark ChouBun al Sakana AI, care evaluează raționamentul în context lung pentru sarcinile în limba japoneză, NAMM-urile au oferit o îmbunătățire cu 15% față de linia de bază. ChouBun abordează o lacună în benchmark-urile existente, care tind să se concentreze pe limbile engleză și chineză, testând modele pe introduceri de text extinse în japoneză.
Succesul NAMM-urilor pe ChouBun evidențiază versatilitatea lor în diferite limbi și dovedește robustețea lor în manipularea intrărilor care nu sunt în limba engleză-o caracteristică cheie pentru aplicațiile AI globale. NAMM-urile au reușit să rețină în mod eficient conținutul specific contextului, în timp ce elimină redundanțele gramaticale și simbolurile mai puțin semnificative, permițând modelului să funcționeze mai eficient în sarcini precum rezumarea și înțelegerea în formă lungă în japoneză.
 Sursa: Sakana AI
Sursa: Sakana AI
The rezultatele demonstrează împreună că NAMM-urile excelează la optimizarea utilizării memoriei fără a compromite acuratețea. Indiferent dacă sunt evaluate pe sarcini care necesită secvențe extrem de lungi sau în contexte de limbă non-engleză, NAMM-urile depășesc în mod constant modelele de bază, obținând atât eficiență computațională, cât și rezultate îmbunătățite.
Această combinație de economisire a memoriei și câștiguri de precizie poziționează NAMM-urile drept un mare progres pentru sistemele AI ale întreprinderilor însărcinate cu gestionarea intrărilor vaste și complexe.
Rezultatele sunt deosebit de remarcabile în comparație cu metodele anterioare precum H₂O și L2, care a sacrificat performanța pentru eficiență. NAMM-urile, pe de altă parte, le realizează pe ambele.
„Rezultatele noastre demonstrează că NAMM-urile oferă cu succes îmbunătățiri consistente în ambele axe de performanță și eficiență în raport cu transformatoarele de bază”, declară cercetătorii.
Aplicații intermodale: dincolo de limbaj
Una dintre cele mai impresionante descoperiri a fost capacitatea NAMM-urilor de a transfera zero-shot la alte sarcini și input modalități
Unul dintre cele mai remarcabile aspecte ale modelelor de memorie de atenție neuronală (NAMM) este capacitatea lor de a se transfera fără probleme între diferite sarcini și modalități de introducere, dincolo de aplicațiile tradiționale bazate pe limbaj Spre deosebire de alte metode de optimizare a memoriei, care necesită adesea reinstruire sau reglare fină pentru fiecare domeniu, NAMM-urile își mențin beneficiile de eficiență și performanță fără ajustări suplimentare experimentele au demonstrat această versatilitate în două domenii cheie: viziunea computerizată și învățarea prin întărire, ambele prezentând provocări unice pentru modelele bazate pe transformatoare.
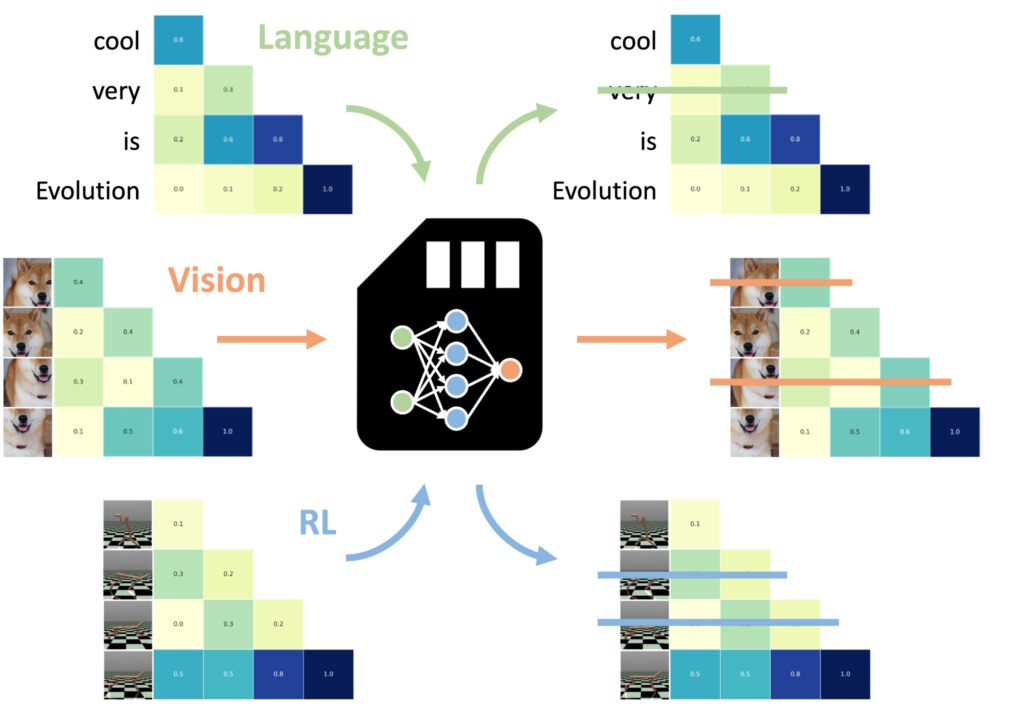 NAMMs instruiți pe limbajul poate fi transferat cu zero-shot la alte transformatoare prin modalități de intrare și domenii de activitate. (Imagine: Sakana AI)
NAMMs instruiți pe limbajul poate fi transferat cu zero-shot la alte transformatoare prin modalități de intrare și domenii de activitate. (Imagine: Sakana AI)
În viziunea computerizată, NAMM-urile au fost evaluate folosind modelul Llava Next Video, un Transformator conceput pentru procesarea secvențelor video lungi. Videoclipurile conțin în mod inerent cantități mari de date redundante, cum ar fi cadre repetate sau variații minore care oferă puține informații suplimentare.
NAMM-urile au identificat și au eliminat automat aceste cadre redundante în timpul inferenței, comprimând eficient fereastra de context fără a compromite capacitatea modelului de a interpreta conținutul video.
De exemplu, NAMM-urile au păstrat cadre cu detalii vizuale cheie-cum ar fi schimbări de acțiune, interacțiuni cu obiecte sau evenimente critice-în timp ce elimină cadre repetitive sau statice. Acest lucru a dus la o eficiență îmbunătățită a procesării, permițând modelului să se concentreze pe cele mai relevante elemente vizuale, menținând astfel acuratețea, reducând în același timp costurile de calcul.
În învățarea prin consolidare, NAMM-urile au fost aplicate la Decision Transformer, un model conceput pentru a procesa secvențe de acțiuni, observații și recompense pentru a optimiza sarcinile de luare a deciziilor. Sarcinile de învățare prin consolidare implică adesea secvențe lungi de intrări cu diferite niveluri de relevanță, unde acțiunile suboptime sau redundante pot împiedica performanța.
NAMM-urile au abordat această provocare prin eliminarea selectivă a jetoanelor corespunzătoare acțiunilor ineficiente și a informațiilor de valoare scăzută, păstrând în același timp pe cele esențiale pentru obținerea unor rezultate mai bune.
De exemplu, în activități precum Hopper și Walker2d—care implică controlul agenților virtuali în mișcare continuă—NAMM-urile au îmbunătățit performanța cu peste 9%. Prin filtrarea mișcărilor suboptime sau a detaliilor inutile, Decision Transformer a obținut o învățare mai eficientă și mai eficientă, concentrându-și puterea de calcul asupra deciziilor care au maximizat succesul în sarcină.
Aceste rezultate evidențiază adaptabilitatea NAMM-urilor în domenii foarte diferite. Fie că procesează cadre video în modele de viziune sau optimizează secvențe de acțiuni în învățarea prin întărire, NAMM-urile și-au demonstrat capacitatea de a îmbunătăți performanța, de a reduce utilizarea resurselor și de a menține acuratețea modelului — totul fără a se reinstrui.
NAMM-urile învață să uite aproape exclusiv părți. de cadre video redundante, mai degrabă decât simbolurile de limbă care descriu promptul final, notează lucrarea, evidențiind adaptabilitatea NAMM-urilor.
Basele tehnice ale NAMM-urilor
Eficiența și eficacitatea modelelor de memorie de atenție neuronală (NAMM) constă în procesul lor de execuție simplificat și sistematic, care permite tăierea precisă a token-ului fără intervenție manuală. Acest proces este construit pe trei componente de bază: spectrograme de atenție, compresie de caracteristici și scor automat.
NAMM-urile își ajustează dinamic comportamentul în funcție de cerințele sarcinii și de adâncimea stratului Transformer. Straturile timpurii acordă prioritate contextului „global”, cum ar fi descrierile sarcinilor, în timp ce straturile mai profunde păstrează detaliile „locale” specifice sarcinii. În sarcinile de codificare, de exemplu, NAMM-urile au eliminat comentariile și codul standard; în sarcinile de limbaj natural, au eliminat redundanțele gramaticale, păstrând în același timp conținutul cheie.
Această reținere adaptivă a simbolurilor asigură că modelele rămân concentrate pe informațiile relevante pe parcursul procesării, îmbunătățind viteza și acuratețea.
Primul pasul implică generarea de spectrograme de atenție. Transformatoarele calculează „valorile atenției” la fiecare strat pentru a determina importanța relativă a fiecărui simbol în fereastra de context. NAMM-urile transformă aceste valori de atenție în reprezentări bazate pe frecvență folosind Short-Time Fourier Transform (STFT)
STFT este o tehnică de procesare a semnalului utilizată pe scară largă care descompune o secvență în componente de frecvență localizate, oferind o reprezentare compactă, dar detaliată, prin aplicarea STFT. NAMM-urile convertesc secvențele de atenție brute în date asemănătoare spectrogramelor, permițând o analiză mai clară a jetoanelor care contribuie semnificativ la rezultatul modelului.
În continuare, Feature Compression este aplicată pentru a reduce dimensionalitatea datelor spectrogramei, păstrând în același timp caracteristicile esențiale. Acest lucru se realizează folosind o medie mobilă exponențială (EMA), o metodă matematică care comprimă modelele de atenție istorice într-o formă compactă, fixă.-rezumatul dimensiunilor. EMA asigură că reprezentările rămân ușoare și ușor de gestionat, permițând NAMM-urilor să analizeze eficient secvențele lungi de atenție, minimizând în același timp supraîncărcarea de calcul.
Pasul final este Scoring and Tuning, unde NAMM-urile folosesc un instrument ușor. clasificator de rețele neuronale pentru a evalua reprezentările token-urilor comprimate și a atribui scoruri în funcție de importanța acestora. Token-urile cu scoruri sub un prag definit sunt tăiate din fereastra de context, „uitând” efectiv detaliile inutile sau redundante. Acest mecanism de scor permite NAMM-urilor să prioritizeze jetoanele critice care contribuie la procesul decizional al modelului, eliminând în același timp datele mai puțin relevante.
Ceea ce face ca NAMM-urile să fie deosebit de eficiente este dependența lor de optimizarea evolutivă pentru a perfecționa acest proces. Metodele tradiționale de optimizare, cum ar fi coborârea gradientului, se luptă cu sarcini nediferențiabile, cum ar fi să decidă dacă un jeton ar trebui să fie reținut sau aruncat
În schimb, NAMM-urile folosesc un algoritm evolutiv iterativ, inspirat de selecția naturală, pentru a „muta”. și „selectați” cele mai eficiente strategii de gestionare a memoriei de-a lungul timpului. Prin încercări repetate, sistemul evoluează pentru a prioritiza automat token-urile esențiale, atingerea unui echilibru între performanță și eficiența memoriei fără a necesita o reglare fină manuală.
Această execuție simplificată — care combină analiza jetoanelor bazată pe spectrograme, compresia eficientă și tăierea automată — permite NAMM-urilor să ofere atât economii semnificative de memorie, cât și performanță. câștiguri în diverse sarcini bazate pe Transformer. Prin reducerea cerințelor de calcul în același timp menținând sau îmbunătățind acuratețea, NAMM-urile stabilesc un nou punct de referință pentru gestionarea eficientă a memoriei în modelele moderne de AI.
Ce urmează pentru Transformers?
Sakana AI crede că NAMM-urile sunt doar începutul. În timp ce munca actuală se concentrează pe optimizarea modelelor pre-antrenate la inferență, cercetările viitoare pot integra NAMM-urile în procesul de formare în sine. Acest lucru ar putea permite modelelor să învețe strategii de gestionare a memoriei în mod nativ, extinzând și mai mult lungimea ferestrelor de context și sporind eficiența în toate domeniile.
„Această activitate abia a început să exploreze spațiul de proiectare al modelelor noastre de memorie, pe care îl anticipăm. poate oferi multe oportunități noi de a avansa generațiile viitoare de transformatoare”, conchide echipa.
Capacitatea dovedită a NAMM-urilor de a scala performanța, de a reduce costurile și de a se adapta la diferite modalități stabilește un nou standard pentru eficiența modelelor AI la scară largă.