Cercetătorii de la Universitatea de Inteligență Artificială Mohamed bin Zayed (MBZUAI) din Abu Dhabi au a dezvăluit LlamaV-o1, un nou model AI multimodal care acordă prioritate transparenței și coerență logică în raționament.
Spre deosebire de alte modele de inteligență artificială rațională, care oferă adesea rezultate de tip cutie neagră, LlamaV-o1 își demonstrează procesul de rezolvare a problemelor pas cu pas, permițând utilizatorilor să urmărească fiecare etapă a logicii sale.
Împreună cu introducerea VRC-Bench, un nou punct de referință pentru evaluarea pașilor intermediari de raționament, LlamaV-o1 oferă o nouă perspectivă asupra interpretabilității și utilizării AI în diverse domenii, cum ar fi ca diagnostic medical, finanțe și cercetare științifică.
Lansarea acestui model și benchmark-ul reflectă cererea în creștere pentru sisteme AI care nu numai că oferă rezultate precise, ci și explică modul în care sunt acele rezultate. realizat.
Legate: OpenAI dezvăluie un nou model o3 cu abilități de raționament îmbunătățite drastic
VRC-Bench: un punct de referință conceput pentru un raționament transparent
Valorul de referință VRC-Bench este un element de bază al dezvoltării și evaluării LlamaV-o1. Benchmark-urile tradiționale AI se concentrează în primul rând pe acuratețea răspunsului final, neglijând adesea procesele logice care duc la acele răspunsuri.
VRC-Bench abordează această limitare evaluând calitatea pașilor de raționament prin valori precum Faithfulness-Step și Acoperirea semantică, care măsoară cât de bine se aliniază raționamentul unui model cu materialul sursă și consistența logică.
Legate: Noul model de gândire Flash Gemini 2.0 de la Google provoacă OpenAI o1 Pro cu performanțe excelente
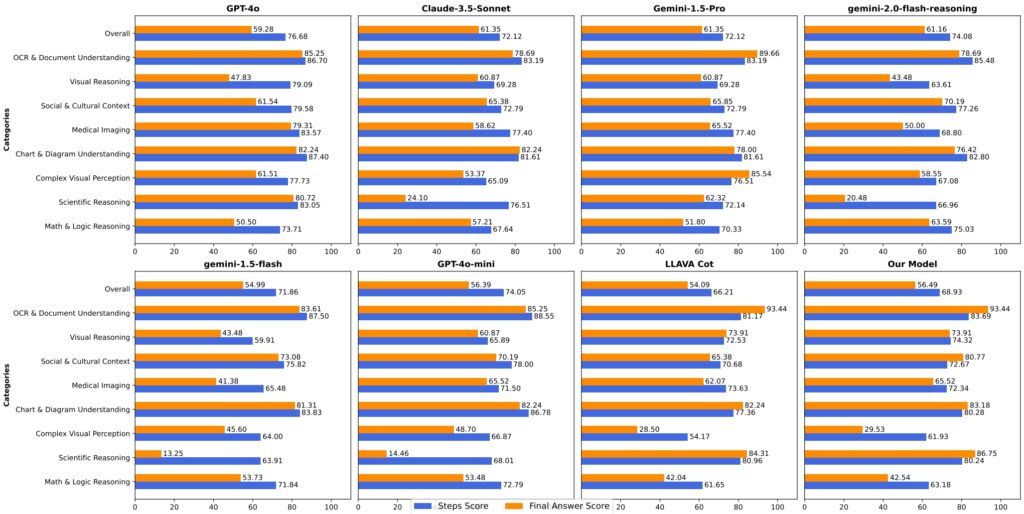
Acoperire peste 1.000 de sarcini din opt categorii, VRC-Bench include domenii precum raționamentul vizual, imagistica medicală și analiza contextului cultural. Aceste sarcini conțin mai mult de 4.000 de pași de raționament verificați manual, ceea ce face ca benchmarkul să fie unul dintre cei mai cuprinzătoare în evaluarea raționamentului pas cu pas.
Cercetătorii descriu importanța acesteia, afirmând: „Majoritatea criteriilor de referință se concentrează în primul rând pe acuratețea sarcinii finale, neglijând calitatea pașilor intermediari de raționament. VRC-Bench prezintă un set divers de provocări… permițând o evaluare robustă a coerenței logice și a corectitudinii raționamentului.”
Prin stabilirea unui nou standard pentru evaluarea AI multimodală, VRC-Bench asigură că modelele precum LlamaV-o1 sunt trase la răspundere pentru procesele lor de luare a deciziilor, oferind un nivel de transparență esențial pentru aplicațiile cu mize mari.
Performanță Metric: Cum se evidențiază LlamaV-o1
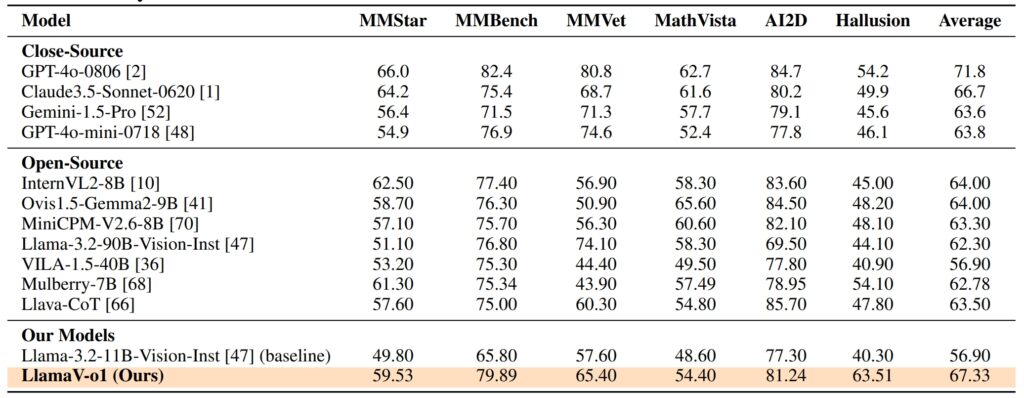
Performanța LlamaV-o1 pe VRC-Bench și alte benchmark-uri demonstrează priceperea sa tehnică. A obținut un scor de raționament de 68,93, depășind alte modele open-source LLava-CoT (66.21) și reducerea decalajului cu modele brevetate, cum ar fi GPT-4o, care a marcat 71.8
Pe lângă acuratețea sa, LlamaV-o1 a oferit viteze de inferență de cinci ori mai mari în comparație cu eficiența sa.
Pe șase benchmark-uri multimodale, inclusiv MathVista, AI2D și Haluzie-LlamaV-o1 a obținut un scor mediu de 67,33%. Această performanță subliniază capacitatea sa de a gestiona diverse raționamente sarcini, menținând în același timp coerența logică și transparența.
Training LlamaV-o1: The Synergy of Curriculum Learning and Beam Search
Succesul lui LlamaV-o1 își are rădăcinile în metodele sale inovatoare de antrenament. Cercetătorii au folosit învățarea curriculară, o tehnică inspirată din educația umană.
Această abordare începe cu sarcini mai simple și progresează treptat către altele mai complexe, permițând modelului să dezvolte abilități fundamentale de raționament înainte de a aborda provocările avansate.
Prin structurarea procesului de formare, învățarea curriculum-ului îmbunătățește capacitatea modelului de a se generaliza în diverse sarcini, de la OCR a documentelor până la raționamentul științific.
Legate: QwQ de la Alibaba-32B-Preview se alătură bătăliei de raționare a modelului AI cu OpenAI
Beam Search, un algoritm de optimizare, îmbunătățește această abordare de antrenament prin generarea mai multor căi de raționament în paralel și selectând cel mai logic. Această metodă nu numai că îmbunătățește acuratețea modelului, ci și reduce costurile de calcul, făcându-l mai eficient pentru aplicațiile din lumea reală.
Așa cum explică cercetătorii, „Prin valorificarea învățării curriculare și a Beam Search, modelul nostru dobândește treptat abilități… asigurând atât inferență optimizată, cât și capacități solide de raționament.”
Aplicații în medicină , Finance și Beyond
Capacitățile transparente de raționament ale LlamaV-o1 îl fac deosebit de potrivit pentru aplicațiile în care încrederea și interpretabilitatea sunt esențiale în domeniul medical imagistica, de exemplu, modelul poate oferi nu doar un diagnostic, ci și o explicație detaliată a modului în care a ajuns la această concluzie
Această caracteristică permite radiologilor și altor profesioniști din domeniul medical să valideze perspectivele bazate pe inteligență artificială, sporind încrederea și. acuratețe în luarea deciziilor critice.
În sectorul financiar, LlamaV-o1 excelează în interpretarea diagramelor și diagramelor complexe, oferind pas cu pas defalcări care oferă informații utile.
LlamaV-o1 reprezintă un progres semnificativ în IA multimodală, în special în capacitatea sa de a oferi un raționament transparent. Combinând învățarea curriculară și Beam Search cu metricile de evaluare robuste ale VRC-Bench, stabilește un nou punct de referință pentru interpretabilitate și eficiență.
Pe măsură ce sistemele AI devin din ce în ce mai integrate în industriile critice, nevoia de modele care să le explice procesele de raționament va crește doar.