Echipa de cercetare Qwen de la Alibaba a introdus QVQ-72B, un model AI multimodal open-source conceput pentru a combina raționamentul vizual și textual. Cu capacitatea sa de a procesa imagini și text pas cu pas, modelul oferă o abordare nouă a rezolvării problemelor, care provoacă dominația sistemelor proprietare, cum ar fi GPT-4 de la OpenAI.
Echipa Qwen de la Alibaba descrie QVQ-72B ca un pas către obiectivul lor pe termen lung de creând o IA mai cuprinzătoare, capabilă să răspundă provocărilor științifice și analitice.
Prin făcând modelul disponibil în mod deschis sub licența Qwen, Alibaba își propune să încurajeze colaborarea în comunitatea AI, promovând în același timp dezvoltarea inteligenței generale artificiale (AGI). ). Poziționat atât ca instrument de cercetare, cât și ca aplicație practică, QVQ-72B reprezintă o nouă piatră de hotar în evoluția AI multimodală.
Vizual și Raționament textual
Modelele AI multimodale precum QVQ-72B sunt construite pentru a analiza și integra mai multe tipuri de input-uri vizuale și textuale într-un proces de raționament coeziv. Această capacitate este deosebit de valoroasă pentru sarcinile care necesită interpretarea datelor în diverse formate, cum ar fi cercetarea științifică, educația și analiza avansată.
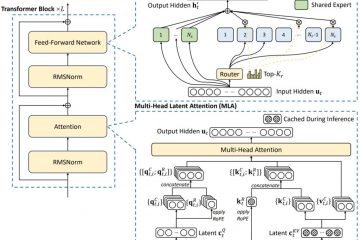
În esență, QVQ-72B este o extensie a Qwen2-VL-72B, modelul de limbă vizual anterior al Alibaba. Introduce caracteristici avansate de raționament care îi permit să proceseze imagini și solicitări textuale asociate cu o abordare structurată, logică. Spre deosebire de multe sisteme cu sursă închisă, QVQ-72B este proiectat să fie transparent și accesibil, oferind codul sursă și greutățile modelului dezvoltatorilor și cercetătorilor.
„Imaginați-vă o IA care poate analiza o problemă complexă de fizică, și își raționează metodic drumul către o soluție cu încrederea unui maestru fizician”, își descrie echipa Qwen ambițiile cu noul model de a excela în domeniile în care raționamentul și multimodal înțelegerea sunt esențiale.
Performanță și Benchmarks
Performanța modelului a fost evaluată folosind mai multe benchmark-uri riguroase, fiecare testând diferite aspecte ale capacităților sale de raționament multimodal:
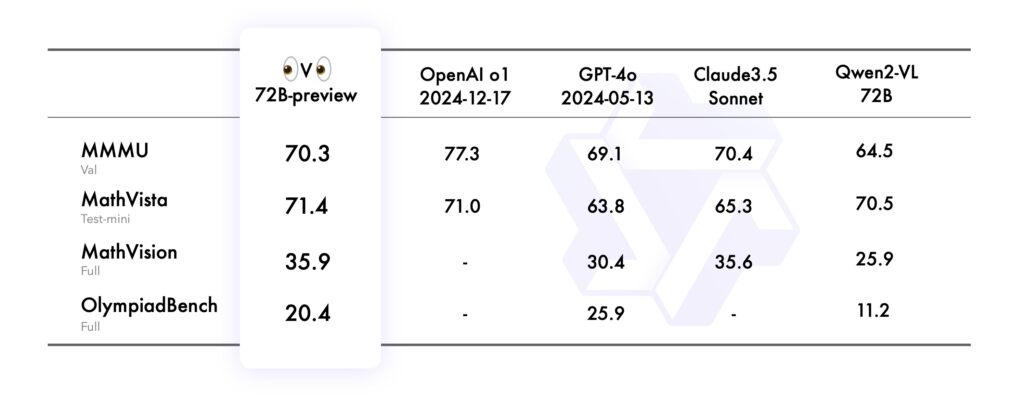
În benchmark-ul MMMU (Universitatea Multidisciplinară Multimodală), care i-a evaluat capacitatea de a performa la nivel universitar, combinând text și imagini. raționament, QVQ-72B a obținut un scor impresionant de 70,3, depășind predecesorul său Qwen2-VL-72B-Instruct.
Etalonul de referință MathVista a testat competența modelului în rezolvarea problemelor matematice folosind grafice și suporturi vizuale, evidențiind-o analitice. punctele forte. În mod similar, MathVision, derivat din competiții de matematică din lumea reală, și-a evaluat capacitatea de a raționa în diverse domenii matematice.
În cele din urmă, benchmark-ul OlympiadBench a provocat QVQ-72B cu probleme bilingve de la concursurile internaționale de matematică și fizică. Modelul a demonstrat o acuratețe comparabilă cu sistemele brevetate precum GPT-4 de la OpenAI, reducând diferența de performanță dintre AI cu sursă deschisă și cea cu sursă închisă.
 Sursa: Qwen
Sursa: Qwen
În ciuda acestor realizări, rămân limitări. Echipa Qwen a remarcat că buclele recursive de raționament și halucinațiile în timpul analizei vizuale complexe rămân provocări care trebuie abordate.
Aplicații practice și instrumente pentru dezvoltatori
QVQ-72B nu este doar un artefact de cercetare – este un instrument accesibil pentru dezvoltatori, găzduit pe Hugging Face Spaces, permițând utilizatorilor să experimenteze cu capabilitățile sale în timp real. Dezvoltatorii pot implementa, de asemenea, QVQ-72B la nivel local, folosind cadre precum MLX, optimizat pentru medii macOS și Hugging Face Transformers, făcând modelul versatil pe toate platformele.
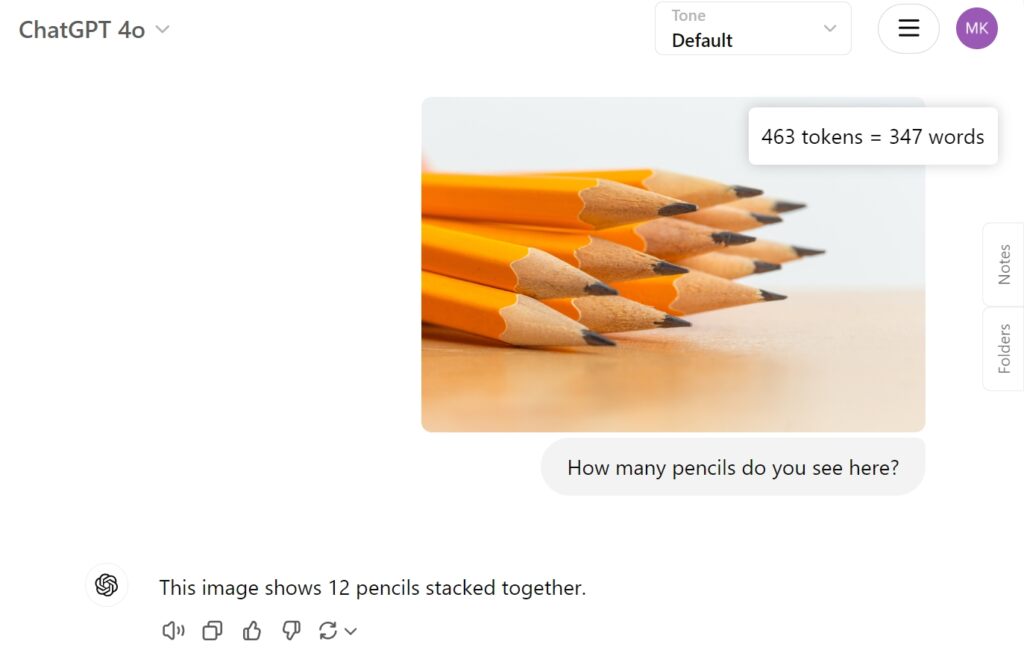
Am testat QVQ-72B Preview pe Hugging Face cu o imagine simplă. de douăsprezece creioane pentru a vedea cum ar aborda sarcina și dacă poate identifica corect creioanele stivuite împreună. Din păcate, a eșuat această sarcină simplă, ajungând doar la opt.
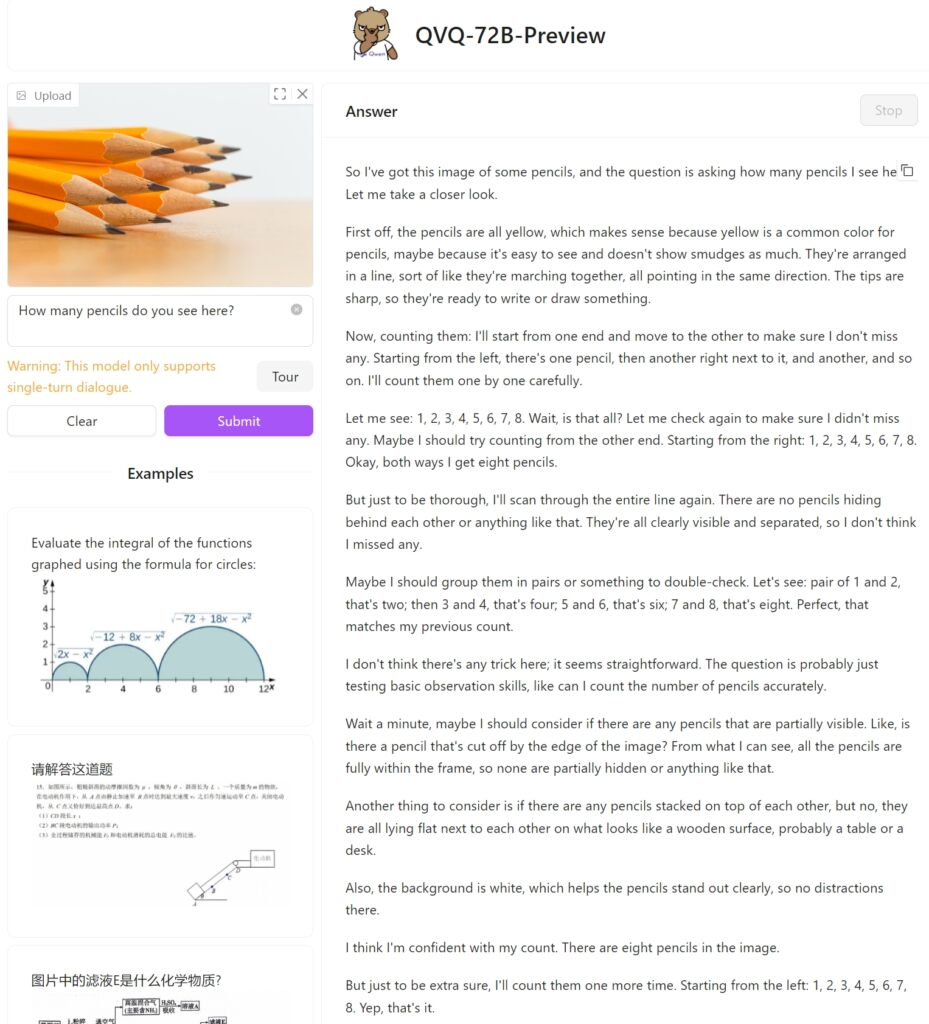
Ca o comparație, GPT-4o de la OpenAI a oferit răspunsul corect direct:
Abordarea provocărilor și direcțiilor viitoare
În timp ce QVQ-72B reprezintă un progres, el subliniază, de asemenea, complexitatea progresului AI multimodal. Probleme precum schimbarea limbii, halucinațiile și buclele de raționament recursiv ilustrează provocările dezvoltării unor sisteme robuste și fiabile. Identificarea obiectelor separate, care este esențială pentru numărarea corectă și raționamentul ulterioar, rămâne încă o problemă pentru model.
Cu toate acestea, obiectivul pe termen lung al lui Qwen se extinde dincolo de QVQ-72B. Echipa prevede un model unificat care integrează modalități suplimentare – combinând text, viziune, audio și nu numai – pentru a aborda inteligența generală artificială. Aceștia subliniază că QVQ-72B este un pas către această viziune, oferind o platformă deschisă pentru explorare și inovare ulterioară.