OpenAI a introdus alinierea deliberativă, o metodologie menită să încorporeze raționamentul de siguranță în funcționarea sistemelor de inteligență artificială. Conceput pentru a aborda provocările persistente în domeniul siguranței AI, alinierea deliberativă permite modelelor AI să facă referire și să argumenteze în mod explicit politicile de siguranță definite de om în timpul interacțiunilor în timp real.
Conform OpenAI, abordarea reprezintă o evoluție majoră în instruirea în domeniul siguranței AI, trecând dincolo de dependența de seturi de date precodificate la sisteme care evaluează dinamic și răspund la solicitări cu decizii informate în context.
În sistemele tradiționale de inteligență artificială, mecanismele de siguranță sunt implementate în timpul fazelor de pre-formare și post-antrenament, bazându-se adesea pe seturi de date adnotate de om pentru a deduce comportamente ideale.
Legate: OpenAI dezvăluie noul model o3 cu Abilități de raționament îmbunătățite drastic
Aceste metode, deși sunt fundamentale, poate lăsa goluri atunci când modelele întâlnesc scenarii noi sau complexe care nu se încadrează în datele lor de antrenament. Alinierea deliberativă a OpenAI oferă o soluție prin echiparea sistemelor AI pentru a se implica în mod activ cu specificațiile de siguranță, asigurându-se că răspunsurile sunt calibrate la cerințele etice, legale și practice ale mediului lor.
Conform cercetătorilor OpenAI, „[Deliberative aliniere] este prima abordare care învață direct un model textul specificațiilor sale de siguranță și antrenează modelul să delibereze asupra acestor specificații la momentul deducerii.”
Învățarea sistemelor AI să se gândească la siguranță
metodologia de aliniere deliberativă implică un proces de instruire în două etape care combină ajustarea fină supravegheată (SFT) și învățare prin consolidare (RL), susținută de generarea de date sintetice Această abordare structurată învață nu numai conținutul politicilor de siguranță, ci și îi antrenează să aplice aceste linii directoare în mod dinamic în timpul funcționării lor.
În faza de reglare fină supravegheată (SFT), modelele AI sunt expuse la un set de date îngrijit de solicitări asociate cu răspunsuri detaliate care fac referire în mod explicit la specificațiile interne de siguranță ale OpenAI.
Aceste lanț de gândire ( Exemplele CoT) ilustrează modul în care modelele ar trebui să abordeze diverse scenarii, împărțind solicitările complexe în pași mai mici și gestionați, în timp ce fac referințe încrucișate la orientările de siguranță. Rezultatele sunt apoi evaluate de un sistem AI intern, denumit adesea „judecător”, care evaluează respectarea lor la standardele politicii.
Legate: CEO-ul OpenAI, Sam Altman, deținut și vândut Miza OpenAI necunoscută anterior
Faza de învățare de întărire îmbunătățește și mai mult capacitățile modelului prin ajustarea fină a procesului de raționament, folosind feedback-ul de la modelul judecătorului, sistemul în mod iterativ își îmbunătățește capacitatea de a raționa prin sugestii nuanțate sau ambigue, aliniindu-se mai strâns cu prioritățile etice și operaționale ale OpenAI.
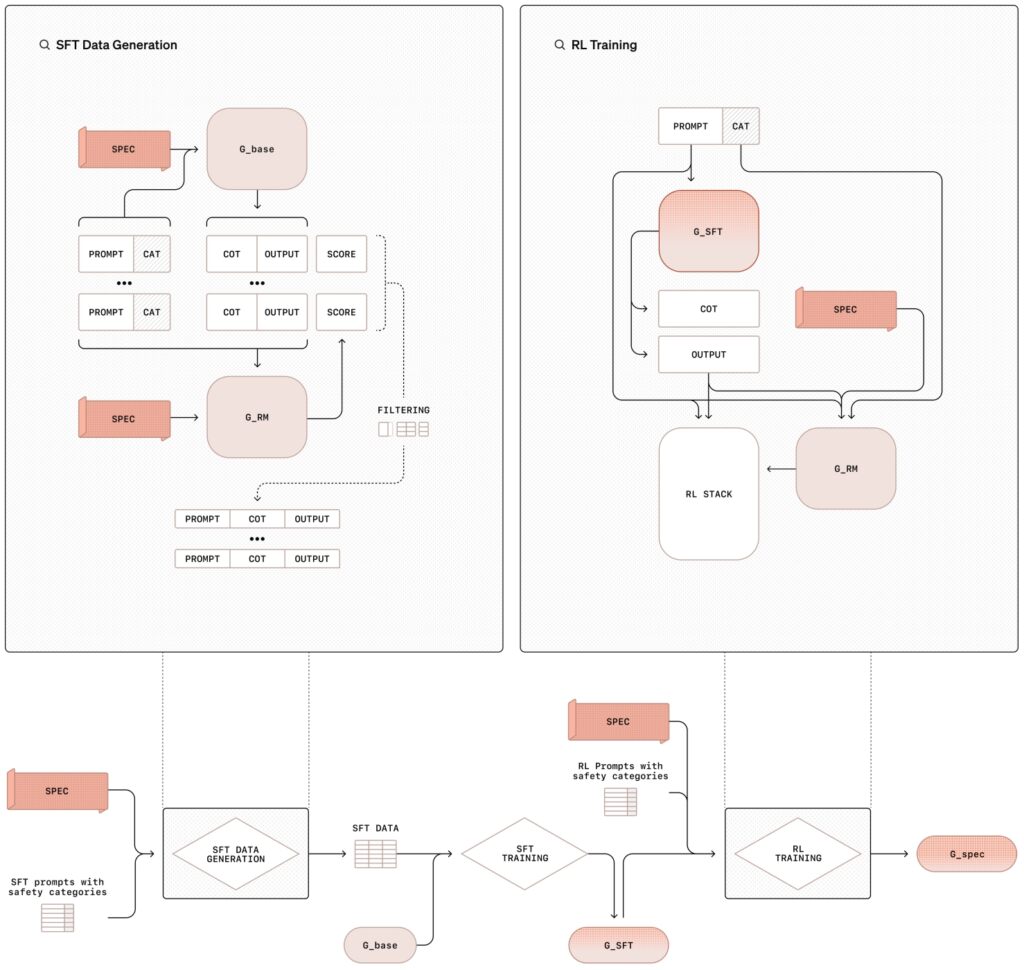 Ilustrarea metodologiei de aliniere deliberată cu supraveghere reglare fină (SFT) și învățare prin întărire (RL) (Imagine: OpenAI)
Ilustrarea metodologiei de aliniere deliberată cu supraveghere reglare fină (SFT) și învățare prin întărire (RL) (Imagine: OpenAI)
O inovație cheie în acest sens metodologia este utilizarea datelor sintetice-exemple generate de alte modele AI-care înlocuiește nevoia de seturi de date etichetate uman. Acest lucru nu numai că scala procesul de instruire, dar asigură și un nivel ridicat de precizie în alinierea comportamentelor modelului cu cerințele de siguranță.
Așa cum notează cercetătorii OpenAI, „Această metodă realizează o aderență foarte precisă a specificațiilor, bazându-se doar pe datele generate de model. Reprezintă o abordare scalabilă a alinierii.”
Abordarea jailbreak-urilor și a refuzurilor excesive
Două dintre cele mai persistente probleme în siguranța AI sunt vulnerabilitatea modelului la încercările de jailbreak. iar tendința sa de a refuza în mod excesiv solicitările benigne Jailbreak-urile implică solicitări adverse concepute pentru a ocoli garanțiile, adesea deghizate sau codificate în moduri care. își fac intenția mai puțin vizibilă. Cercetătorii au documentat recent cum chiar și modificări minore ale caracterelor utilizate pentru un prompt pot face jailbreak modelele de frontieră actuale.
Refuzurile excesive, pe de altă parte, apar atunci când modelele prea precaute blochează interogările inofensive. de o abundență de prudență, frustrând utilizatorii și limitând utilitatea sistemului.
Alinierea deliberativă este concepută special pentru a aborda aceste provocări prin echiparea modelelor cu capacitatea de a raționa prin intenția și contextul solicitărilor, metodologia le îmbunătățește capacitatea de a rezista atacurilor adverse, menținând în același timp receptivitatea la interogările legitime.
Legate: Rezultate AI Safety Index 2024: OpenAI, Google, Meta, xAI Fall Short; Antropic în vârf
De exemplu, atunci când i se prezintă o solicitare deghizată de a produce conținut dăunător, un model antrenat cu aliniere deliberativă poate decoda intrarea, poate face referire la politici de siguranță și poate oferi un refuz motivat.
În mod similar, atunci când este adresată o întrebare benignă despre subiecte controversate, cum ar fi istoria dezvoltării armelor nucleare, modelul poate oferi informații exacte fără a încălca regulile de siguranță.
În rezultatele cercetării lor, OpenAI a subliniat că modelele instruite cu aliniere deliberativă sunt capabile să identifice intenția din spatele prompturilor codificate sau deghizate, raționând prin politicile lor de siguranță pentru a asigura conformitatea.
OpenAI ilustrează implicațiile practice ale alinierii deliberative prin cazuri de utilizare din lumea reală. Într-un exemplu dat, un utilizator solicită unui sistem AI instrucțiuni detaliate despre falsificarea unui panou de parcare.
Modelul identifică intenția cererii ca fiind frauduloasă, face referire la politica OpenAI împotriva activării activității ilegale și refuză să se conformeze. Acest răspuns nu numai că previne utilizarea abuzivă, ci demonstrează și capacitatea sistemului de a contextualiza și a argumenta în mod dinamic politicile de siguranță.
Într-un alt scenariu, modelul se confruntă cu un prompt codificat care solicită sfaturi ilicite. Folosind capacitățile sale de raționament, sistemul decodifică intrarea, face referințe încrucișate la specificațiile sale de siguranță și determină că interogarea încalcă liniile directoare etice ale OpenAI. Modelul oferă apoi o explicație a refuzului său, consolidând transparența în procesul său de luare a deciziilor.
Exemplele evidențiază capacitatea de aliniere deliberativă de a echipa sistemele AI cu instrumentele necesare pentru a naviga în situații complexe și sensibile din punct de vedere etic, asigurând atât conformitatea cu politicile, cât și transparența utilizatorilor.
Legate: Meta îndeamnă blocarea juridică privind tranziția OpenAI către profit Entitatea
Extinderea domeniului de aplicare a alinierii deliberative
Alinierea deliberativă face mai mult decât atenuarea riscurilor; de asemenea, deschide ușa pentru ca sistemele AI să funcționeze cu o mai mare transparență și responsabilitate. Permițând modelelor să își articuleze în mod explicit raționamentul, OpenAI a introdus un cadru în care utilizatorii pot înțelege mai bine logica din spatele răspunsurilor unei AI.
Această transparență este deosebit de importantă în aplicațiile cu mize mari în care considerentele etice sau legale sunt primordiale, cum ar fi asistența medicală, finanțele și aplicarea legii.
De exemplu, atunci când utilizatorii interacționează cu modele antrenat sub aliniere deliberativă, raționamentul în lanț de gândire nu este doar intern, ci poate fi partajat ca parte a rezultatului modelului.
Un utilizator care caută clarificări cu privire la motivul pentru care un model a refuzat o solicitare poate primi o explicație care face referire la politici de siguranță specifice, împreună cu o detaliere pas cu pas a modului în care sistemul a ajuns la încheierea sa. Acest nivel de detaliu nu numai că creează încredere, ci și încurajează utilizarea responsabilă a tehnologiilor AI.
OpenAI subliniază că transparența în luarea deciziilor AI este esențială pentru construirea încrederii și asigurarea utilizării etice, cu alinierea deliberativă care să permită sistemelor de a explica comportamentul lor în mod clar.
Legate: Deep Dive: Cum noul model o1 al OpenAI înșală oamenii Strategic
Date sintetice: coloana vertebrală a siguranței AI scalabile
O componentă crucială a alinierii deliberative este utilizarea datelor sintetice, care înlocuiește tradiționale etichete umane seturi de date. Generarea de date de antrenament din sistemele AI, în loc să se bazeze pe adnotări umane, oferă mai multe avantaje, inclusiv scalabilitate, eficiență a costurilor și precizie.
Datele sintetice pot fi adaptate pentru a răspunde provocărilor specifice de siguranță, permițând OpenAI să creeze seturi de date care să se alinieze îndeaproape cu prioritățile sale operaționale.
Gauza de date sintetice a OpenAI implică generarea de exemple de solicitări și lanțul corespunzător-răspunsuri de gândire folosind un model AI de bază. Aceste exemple sunt apoi revizuite și filtrate de modelul „judecător” pentru a se asigura că îndeplinesc criteriile de calitate și aliniere dorite.
Odată aprobate, datele sunt utilizate în fazele de reglare fină supravegheată și de învățare de consolidare, unde antrenează modelul țintă să raționeze în mod explicit cu privire la politicile de siguranță.
„Generarea de date sintetice ne permite să extindem formarea în domeniul siguranței AI fără a compromite calitatea sau alinierea precizie”, au subliniat cercetătorii OpenAI. „Această abordare abordează unul dintre blocajele cheie ale metodologiilor tradiționale de siguranță, care se bazează adesea în mare măsură pe munca umană pentru adnotarea datelor”.
Această dependență de datele sintetice asigură, de asemenea, consecvența în pregătire. Adnotatorii umani pot introduce variabilitate din cauza la diferențe de interpretare, dar exemplele generate de IA oferă o bază standardizată. Această consecvență ajută modelele să se generalizeze mai bine într-o gamă largă de scenarii, de la verificări simple de siguranță dileme etice nuanțate.
Legate: Parteneriat OpenAI și Anduril Forge pentru apărarea militară a dronelor din SUA
Depășirea concurenților în parametri cheie
OpenAI a testat alinierea deliberativă față de standardele de siguranță de top. Rezultatele demonstrează că modelele antrenate cu alinierea deliberativă depășesc în mod constant concurenți, obținând scoruri ridicate atât la robustețe, cât și la capacitate de răspuns.
O1 și modelele asociate au fost testate riguros împotriva sistemelor competitive, inclusiv GPT-4o, Gemini 1.5 Pro și Claude 3.5 Sonnet, într-o varietate de sisteme de siguranță. metrici. Pe StrongREJECT, care măsoară rezistența unui model la jailbreak-uri adverse, modelele OpenAI o1 au obținut în mod constant scoruri mai mari, reflectând capacitatea lor avansată de a identifica și bloca solicitările dăunătoare.
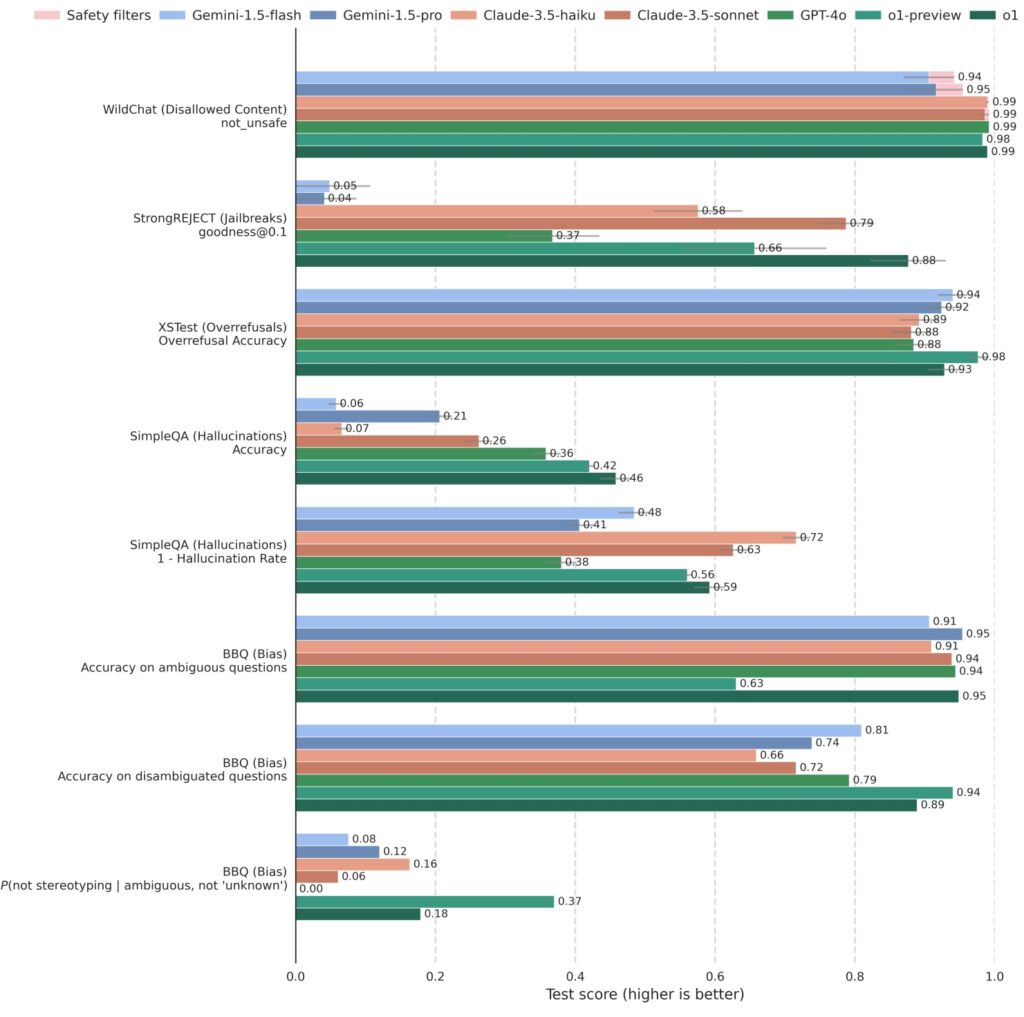 o1 este competitiv în comparație cu alte modele de top pe benchmark-uri care evaluează conținutul interzis (WildChat), jailbreak-urile (StrongREJECT), refuzuri excesive (XSTest), halucinații (SimpleQA) și părtinire (BBQ). Unele solicitări API au fost
o1 este competitiv în comparație cu alte modele de top pe benchmark-uri care evaluează conținutul interzis (WildChat), jailbreak-urile (StrongREJECT), refuzuri excesive (XSTest), halucinații (SimpleQA) și părtinire (BBQ). Unele solicitări API au fost
blocate din cauza naturii sensibile a conținutului. Aceste cazuri sunt înregistrate ca „Blocate de filtre de siguranță”
pe WildChat și excluse din alte benchmark-uri. Barele de eroare sunt estimate utilizând reeșantionarea bootstrap la
nivelul 0,95. (Sursa: OpenAI)
În plus, modelele o1 au excelat în echilibrarea siguranței cu capacitatea de răspuns. Pe XSTest, care evaluează refuzurile excesive, modelele au demonstrat o tendință redusă de a respinge solicitările benigne, menținând în același timp respectarea strictă a ghidurilor de siguranță să rămână utilă și accesibilă fără a compromite standardele etice.
OpenAI spune că alinierea deliberativă îmbunătățește siguranța AI prin reducerea rezultatelor dăunătoare, în timp ce crește acuratețea răspunsului la interacțiunile benigne.
Legate: Cum se poate neutraliza măsurile de protecție prin apăsarea butonului „Stop” în ChatGPT
Mai larg Implicații pentru dezvoltarea AI
Introducerea alinierii deliberative marchează un punct de cotitură în modul în care sistemele AI sunt antrenate și implementate la OpenAI și, probabil, de asemenea de către alții în viitor.
Prin integrarea unui raționament explicit privind siguranța în funcționalitatea de bază a modelelor sale, OpenAI a creat un cadru care nu numai că abordează provocările existente, ci și anticipează riscurile viitoare. Pe măsură ce sistemele AI devin mai capabile, potențialul de utilizare greșită sau consecințe neintenționate crește, ceea ce face ca măsurile de siguranță robuste să fie mai critice ca niciodată.
Alinierea deliberativă servește și ca model pentru comunitatea mai largă a AI. Baza sa pe tehnici scalabile precum datele sintetice și accentul pe transparență oferă un model pentru alte organizații care doresc să-și alinieze sistemele AI cu valorile etice și societale.