DeepSeek AI a lansat DeepSeek-VL2, o familie de modele Vision-Language (VLM) care sunt acum disponibile sub licențe open-source. Seria introduce trei variante — Tiny, Small și VL2 standard — cu dimensiuni ale parametrilor activați de 1,0 miliarde, 2,8 miliarde și, respectiv, 4,5 miliarde.
Modelele sunt accesibile prin GitHub și Față îmbrățișată. Ei promit să avanseze aplicațiile cheie AI, inclusiv răspunsul vizual la întrebări (VQA), recunoașterea optică a caracterelor (OCR) și analiza de înaltă rezoluție a documentelor și diagramelor.
Conform documentației oficiale GitHub, „DeepSeek-VL2 demonstrează capacități superioare în diverse sarcini, inclusiv, dar fără a se limita la răspunsuri vizuale la întrebări, înțelegerea documentelor/tabelului/diagramelor și fundamentarea vizuală.”
Momentul acestei lansări situează DeepSeek AI în concurență directă cu jucători importanți precum OpenAI și Google, ambii dominând domeniul AI în limbajul de viziune modele precum GPT-4V și Gemini-Exp
Accentul pus de DeepSeek pe colaborarea open-source, combinat cu caracteristicile tehnice avansate ale familiei VL2, îl poziționează ca o opțiune gratuită pentru cercetători.
Dynamic Tiling: Avansarea procesării imaginilor de înaltă rezoluție
Una dintre cele mai notabile progrese ale DeepSeek-VL2 este strategia sa dinamică de codificare a viziunii, care revoluționează modul în care modelele procesează date vizuale de înaltă rezoluție.
Spre deosebire de abordările tradiționale cu rezoluție fixă, placarea dinamică împarte imaginile în plăci mai mici, flexibile, care se adaptează la diferite raporturi de aspect. Această metodă asigură extragerea detaliată a caracteristicilor, menținând în același timp eficiența de calcul.
În depozitul său GitHub, DeepSeek descrie acest lucru ca pe o modalitate de „procesare eficientă a imaginilor de înaltă rezoluție cu diferite raporturi de aspect, evitând scalarea computațională asociată de obicei cu creșterea rezoluțiilor imaginii.”
Această capacitate îi permite lui DeepSeek-VL2 să exceleze în aplicații precum împământarea vizuală, unde precizia ridicată este esențială pentru identificarea obiectelor în imagini complexe și sarcini dense OCR, care necesită procesarea textului în documente sau diagrame detaliate
Prin ajustarea dinamică la diferite rezoluții de imagine și raporturi de aspect, modelele depășesc limitele metodelor de codificare statică, făcându-le potrivite pentru cazurile de utilizare care necesită atât flexibilitate, cât și precizie./p>
Amestec de experți și atenție latentă cu mai multe capete pentru eficiență
DeepSeek-VL2 Câștigurile de performanță sunt susținute în continuare de integrarea cadrului Mixture-of-Experts (MoE) și a mecanismului Multi-head Latent Attention (MLA)
Arhitectura MoE activează selectiv subseturi specifice, sau „experți”. în cadrul modelului pentru a gestiona sarcinile mai eficient. Acest design reduce cheltuielile de calcul prin angajarea numai a parametrilor necesari pentru fiecare operațiune, o caracteristică care este deosebit de utilă în mediile cu resurse limitate.
Mecanismul MLA completează cadrul MoE prin comprimarea memoriei cache-cheie-valoare în latentă. vectori în timpul inferenței. Această optimizare minimizează utilizarea memoriei și crește vitezele de procesare fără a sacrifica acuratețea modelului.
Conform documentației tehnice, „Arhitectura MoE, combinată cu MLA, permite DeepSeek-VL2 să atingă performanțe competitive sau mai bune decât modelele dense, cu mai puțini parametri activați.”
Three-Stage Training Pipeline
Dezvoltarea DeepSeek-VL2 a implicat o conductă riguroasă de antrenament în trei etape, concepută pentru a optimiza capacitățile multimodale ale modelului. Prima etapă s-a concentrat pe alinierea viziune-limbaj, în care modelele au fost instruite pentru a integra caracteristici vizuale cu informații textuale. alinierea inițială a fost a doua etapă a preîntâmpinării limbajului vizual, care a încorporat o gamă diversă de seturi de date, inclusiv WIT, WikiHow și OCR multilingv. date, pentru a îmbunătăți abilitățile de generalizare ale modelului în mai multe domenii
În cele din urmă, a treia etapă a constat în reglarea fină supravegheată (SFT), în care seturile de date specifice sarcinii au fost utilizate pentru a perfecționa performanța modelului în domenii precum cele vizuale. împământare, înțelegere a interfeței grafice cu utilizatorul (GUI) și subtitrări dense.
Aceste etape de instruire au permis lui DeepSeek-VL2 să construiască un sistem solid fundament pentru înțelegerea multimodală, permițând în același timp adaptarea modelelor la sarcini specializate. Încorporarea seturilor de date multilingve a îmbunătățit și mai mult aplicabilitatea modelelor în mediile industriale și de cercetare globale.
Legate: Modelul chinezesc DeepSeek R1-Lite-Preview vizează liderul OpenAI în raționamentul automatizat p>
Rezultatele benchmarking
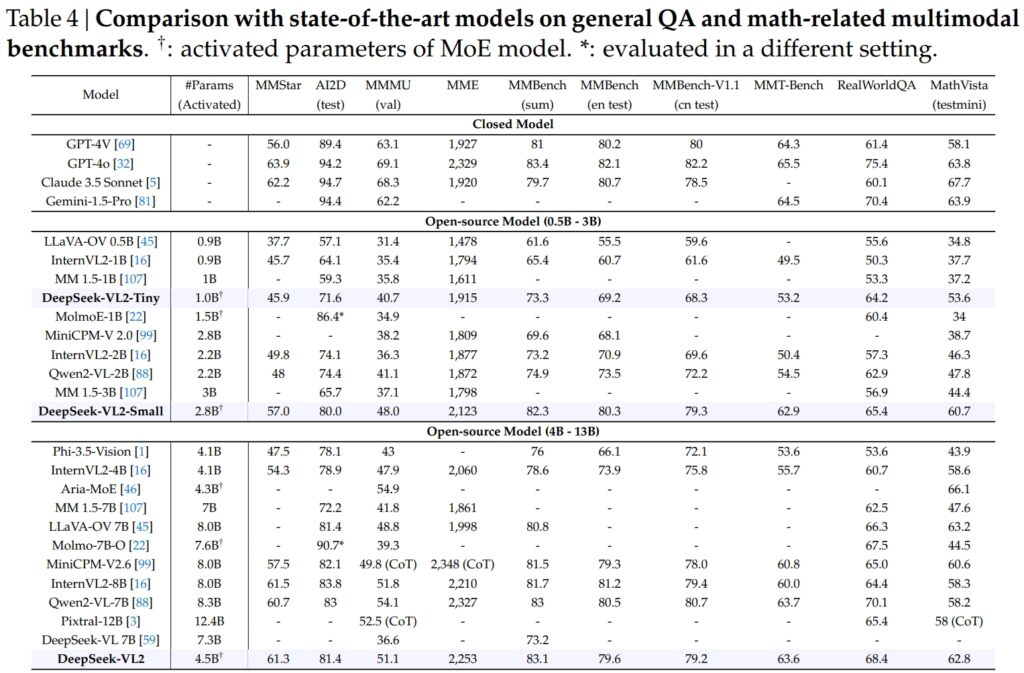
Modelele DeepSeek-VL2, inclusiv variantele Tiny, Small și standard, au excelat în benchmark-uri critice pentru întrebări generale-răspuns (QA) și sarcini multimodale legate de matematică.
DeepSeek-VL2-Small, cu 2,8 miliarde de parametri activați, a obținut un scor MMStar de 57,0 și a depășit modelele de dimensiuni similare precum InternVL2-2B (49,8) și Qwen2-VL-2B (48,0). De asemenea, a rivalizat îndeaproape cu modelele mult mai mari, cum ar fi 4.1B InternVL2-4B (54.3) și 8.3B Qwen2-VL-7B (60.7), demonstrându-și eficiența competitivă.
La testul AI2D pentru vizual. raționament, DeepSeek-VL2-Small a obținut un scor de 80,0, depășind InternVL2-2B (74,1) și MM 1,5-3B (neraportat). Chiar și față de concurenți la scară mai mare precum InternVL2-4B (78,9) și MiniCPM-V2.6 (82,1), DeepSeek-VL2 a demonstrat rezultate puternice cu mai puțini parametri activați.
 Sursa: DeepSeek
Sursa: DeepSeek
Nava amiral Modelul DeepSeek-VL2 (4,5 miliarde de parametri activați) a oferit rezultate excepționale, punctând 61,3 pe MMStar și 81,4 pe AI2D. A depășit concurenți precum Molmo-7B-O (7,6B parametri activați, 39,3) și MiniCPM-V2.6 (8,0B, 57,5), validând și mai mult superioritatea sa tehnică.
Excelență în OCR-Evalue de referință înrudite
Capacitățile lui DeepSeek-VL2 se extind în mod proeminent la OCR (caracter optic sarcini legate de recunoaștere), un domeniu crucial pentru înțelegerea documentelor și extragerea textului în IA. În testul DocVQA, DeepSeek-VL2-Small a obținut o precizie impresionantă de 92,3%, depășind toate celelalte modele open-source de o scară similară, inclusiv InternVL2-4B (89,2%) și MiniCPM-V2.6 (90,8%). Precizia sa a fost chiar în spatele modelelor închise precum GPT-4o (92,8) și Claude 3,5 Sonnet (95,2).
Modelul DeepSeek-VL2 a condus și el testul ChartQA cu un scor de 86,0, depășind InternVL2-4B (81.5) și MiniCPM-V2.6 (82.4). Acest rezultat reflectă capacitatea avansată a DeepSeek-VL2 de a procesa diagrame și de a extrage informații din date vizuale complexe.
Sursa: DeepSeek
În OCRBench, o companie extrem de competitivă pentru recunoașterea textului cu granulație fină, DeepSeek-VL2 a atins 811, depășind 7.6B Qwen2-VL-7B (845) și MiniCPM-V2.6 (852 cu CoT) și evidențiind puterea sa în sarcini dense OCR.
Comparație cu modelele de limbă vizuală de vârf
strong>
Când este plasat alături de lideri din industrie precum GPT-4V de la OpenAI și Gemini-1.5-Pro de la Google, Modelele DeepSeek-VL2 oferă un echilibru convingător între performanță și eficiență. De exemplu, GPT-4V a obținut un scor de 87,2 în DocVQA, ceea ce este doar marginal înaintea DeepSeek-VL2 (93,3), în ciuda faptului că acesta din urmă funcționează într-un cadru open-source cu mai puțini parametri activați.
Pe TextVQA, DeepSeek-VL2-Small a atins 83,4, depășind semnificativ modelele similare cu sursă deschisă precum InternVL2-2B (73.4) și MiniCPM-V2.0 (74.1). Chiar și mult mai mare MiniCPM-V2.6 (8.0B) a ajuns doar la 80,4, subliniind și mai mult scalabilitatea și eficiența arhitecturii DeepSeek-VL2.
Pentru ChartQA, scorul DeepSeek-VL2 de 86,0 l-a depășit pe cel al Pixtral-12B (81.8) și InternVL2-8B (83.3), demonstrându-și capacitatea de a excela în sarcini specializate care necesită o înțelegere vizuală-textuală precisă.
Legate: Mistral AI lansează Pixtral 12B pentru procesarea textului și a imaginilor
Extindere Aplicații: de la conversații bazate pe teme la povestirea vizuală
O caracteristică notabilă a modelelor DeepSeek-VL2 este capacitatea lor de a conduce conversații bazate pe pământ, unde modelul poate identifica obiectele din imagini și le poate integra în discuții contextuale.
De exemplu, folosind un simbol specializat, modelul poate oferi detalii specifice obiectului, cum ar fi locația și descrierea, pentru a răspunde la întrebările despre imagini. Acest lucru deschide posibilități pentru aplicații în robotică, realitate augmentată și asistenți digitali, unde este necesar un raționament vizual precis.
Un alt domeniu de aplicare este povestirea vizuală. DeepSeek-VL2 poate genera narațiuni coerente bazate pe o secvență de imagini, combinând recunoașterea vizuală avansată și capacitățile de limbaj.
Acest lucru este deosebit de valoros în domenii precum educația, media și divertismentul, unde crearea de conținut dinamic este o prioritate. Modelele profită de o înțelegere multimodală puternică pentru a crea povești detaliate și adecvate contextului, integrând elemente vizuale, cum ar fi repere și text, în narațiune fără probleme.
Capacitatea modelelor de fundamentare vizuală este la fel de puternică. În testele care implică imagini complexe, DeepSeek-VL2 a demonstrat capacitatea de a localiza și descrie cu precizie obiecte pe baza indicațiilor descriptive.
De exemplu, atunci când i se cere să identifice o „mașină parcată pe partea stângă a străzii”, modelul poate identifica exact obiectul din imagine și poate genera coordonatele casetei de delimitare pentru a ilustra răspunsul acesteia. Aceste caracteristici fac este foarte aplicabil pentru sisteme autonome și supraveghere, unde analiza vizuală detaliată este critică.
Accesibilitate și scalabilitate la sursă deschisă
Decizia DeepSeek AI de a lansarea DeepSeek-VL2 ca sursă deschisă contrastează puternic cu natura proprietară a concurenților precum GPT-4V de la OpenAI și Gemini-Exp de la Google, care sunt sisteme închise concepute pentru acces public limitat.
Conform documentației tehnice. , „Prin punerea la dispoziție publică a modelelor noastre pre-instruite și a codului, ne propunem să accelerăm progresul în modelarea viziune-limbaj și să promovăm inovarea colaborativă în comunitatea de cercetare.”
Scalabilitatea DeepSeek-VL2 sporește și mai mult atractivitatea acestora. Modelele sunt optimizate pentru implementare într-o gamă largă de configurații hardware, de la un singur GPU cu memorie de 10 GB până la setări cu mai multe GPU capabile să gestioneze sarcini de lucru la scară largă.
Această flexibilitate asigură că DeepSeek-VL2 poate fi utilizat de către organizații de toate dimensiunile, de la startup-uri la întreprinderi mari, fără a fi nevoie de infrastructură specializată.
Inovații în domeniul datelor și Antrenament
Un factor major din spatele succesului DeepSeek-VL2 îl reprezintă datele sale extinse și diverse de antrenament. Faza de preinstruire a inclus seturi de date precum WIT, WikiHow și OBELICS, care au furnizat un amestec de perechi imagine-text intercalate pentru generalizare.
Date suplimentare pentru sarcini specifice, cum ar fi OCR și răspunsul vizual la întrebări, au venit din surse precum LaTeX OCR și PubTabNet, asigurând că modelele pot gestiona atât sarcinile generale, cât și cele specializate cu o precizie ridicată.
Includerea seturilor de date multilingve reflectă, de asemenea, scopul DeepSeek AI de aplicabilitate globală. Seturi de date în limba chineză, precum Wanjuan, au fost integrate împreună cu seturile de date în limba engleză pentru a se asigura că modelele pot funcționa eficient în medii multilingve.
Această abordare îmbunătățește capacitatea de utilizare a DeepSeek-VL2 în regiunile în care domină datele non-engleze, extinzându-și în mod semnificativ baza potențială de utilizatori.
Faza de reglare fină supravegheată a perfecționat și mai mult modelele. capabilități prin concentrarea pe sarcini specifice, cum ar fi înțelegerea GUI și analiza diagramelor. Combinând seturi de date interne cu resurse open-source de înaltă calitate, DeepSeek-VL2 a atins performanțe de ultimă generație în mai multe puncte de referință, validând eficacitatea metodologiei sale de antrenament.
Gestionarea atentă a DeepSeek AI. de date și pipeline de instruire inovatoare au permis modelelor VL2 să exceleze într-o gamă largă de sarcini, menținând în același timp eficiența și scalabilitatea. Acești factori le fac un plus valoros în domeniul AI multimodal.
Abilitatea modelelor de a gestiona sarcini complexe de procesare a imaginilor, cum ar fi împământarea vizuală și OCR dens, le face ideale pentru industrii precum logistica și securitatea. În logistică, aceștia pot automatiza urmărirea stocurilor prin analizarea imaginilor stocurilor din depozit, identificarea articolelor și integrarea constatărilor în sistemele de gestionare a stocurilor.
În domeniul securității, DeepSeek-VL2 poate ajuta la supraveghere prin identificarea obiectelor sau a persoanelor în timp real, pe baza unor interogări descriptive și furnizarea de informații contextuale detaliate operatorilor.
DeepSeek-Capacitatea de conversație legată de VL2 oferă, de asemenea, posibilități în robotică și realitate augmentată. De exemplu, un robot echipat cu acest model ar putea să-și interpreteze vizual mediul înconjurător, să răspundă la întrebările umane despre anumite obiecte și să efectueze acțiuni bazate pe înțelegerea sa asupra inputului vizual.
În mod similar, dispozitivele cu realitate augmentată pot folosi funcțiile de fundamentare vizuală și de povestire ale modelului pentru a oferi experiențe interactive, captivante, cum ar fi tururi ghidate sau suprapuneri contextuale în medii în timp real.
Provocări și perspective de viitor
În ciuda numeroaselor sale puncte forte, DeepSeek-VL2 se confruntă cu mai multe provocări. O limitare cheie este dimensiunea ferestrei sale de context, care limitează în prezent numărul de imagini care pot fi procesate într-o singură interacțiune.
Extinderea acestei ferestre de context în iterațiile viitoare ar permite interacțiuni mai bogate, cu mai multe imagini și ar spori utilitatea modelului în sarcinile care necesită o înțelegere contextuală mai largă.
O altă provocare constă în gestionarea în afara domeniu sau intrări vizuale de calitate scăzută, cum ar fi imagini neclare sau obiecte care nu sunt prezente în datele sale de antrenament. În timp ce DeepSeek-VL2 a demonstrat capacități de generalizare remarcabile, îmbunătățirea robusteței împotriva unor astfel de intrări va crește și mai mult aplicabilitatea acestuia în scenariile din lumea reală.
Privind în perspectivă, DeepSeek AI intenționează să consolideze capacitățile de raționament ale modelelor sale, permițându-le să gestioneze sarcini multimodale din ce în ce mai complexe. Prin integrarea canalelor de instruire îmbunătățite și extinderea setului de date pentru a acoperi scenarii mai diverse, versiunile viitoare ale DeepSeek-VL2 ar putea stabili noi repere pentru performanța AI în limbajul vizual.