Microsoft wprowadził rStar-Math, kontynuację i udoskonalenie wcześniejszej wersji framework rStar, pozwalający przesuwać granice małych modeli językowych (SLM) w rozumowaniu matematycznym.
Zaprojektowany, aby konkurować z większymi systemami, takimi jak wersja zapoznawcza OpenAI o1, rStar-Math osiąga niezwykłe standardy w rozwiązywaniu problemów, demonstrując jednocześnie, jak kompaktowe modele mogą działać na konkurencyjnym poziomie. Rozwój ten pokazuje zmianę priorytetów sztucznej inteligencji, przechodząc od skalowania do optymalizacji wydajności dla określonych zadań.
Przejście od rStar do rStar-Math
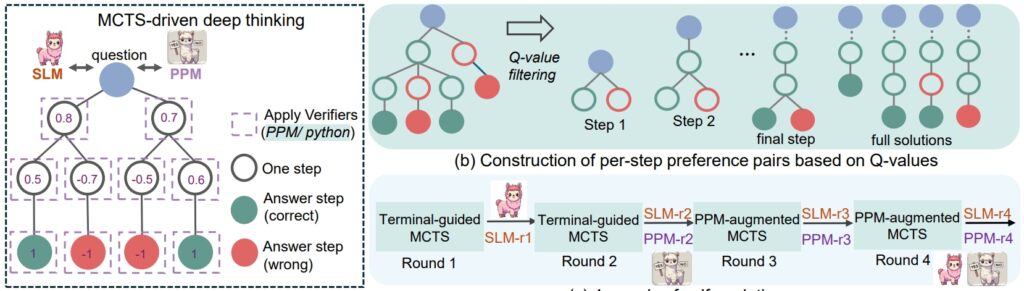
RStar ramy z zeszłego lata położyły podwaliny pod ulepszenie rozumowania SLM poprzez wyszukiwanie drzew Monte Carlo (MCTS), algorytm udoskonalający rozwiązania poprzez symulację i weryfikację wielu ścieżek.
rStar pokazał, że mniejsze modele mogą obsługiwać złożone zadania, ale jego zastosowanie pozostało ogólne. rStar-Math opiera się na tym fundamencie dzięki ukierunkowanym innowacjom dostosowanym do rozumowania matematycznego.
Głównym czynnikiem sukcesu rStar-Math jest oparta na kodzie metodologia łańcucha myślowego (CoT), w której model generuje rozwiązania w obu język naturalny i wykonywalny kod Pythona.
Ta struktura z dwoma wynikami zapewnia weryfikowalność pośrednich etapów rozumowania, co pozwala ograniczyć błędy i zachować spójność logiczną. Naukowcy podkreślili znaczenie tego podejścia, stwierdzając: „Wzajemna spójność odzwierciedla powszechną ludzką praktykę w przypadku braku nadzoru, gdzie zgoda między rówieśnikami co do uzyskanych odpowiedzi sugeruje większe prawdopodobieństwo poprawności”.
Powiązane: Chiński model DeepSeek R1-Lite-Preview jest liderem OpenAI w zakresie automatycznego rozumowania
Oprócz CoT, rStar-Math wprowadza model preferencji procesu (PPM), który ocenia i szereguje etapy pośrednie na podstawie jakości. W przeciwieństwie do tradycyjnych systemów nagradzania, które często opierają się na zaszumionych danych, PPM priorytetowo traktuje spójność logiczną i dokładność, co dodatkowo zwiększa niezawodność modelu:
„PPM wykorzystuje ten fakt , chociaż wartości Q w dalszym ciągu nie są wystarczająco dokładne, aby ocenić każdy etap rozumowania pomimo stosowania szeroko zakrojonych wdrożeń MCTS, wartości Q pozwalają niezawodnie odróżnić kroki pozytywne (poprawne) od kroków negatywnych (nieistotne/nieprawidłowe). jedynki.
W ten sposób metoda uczenia konstruuje pary preferencji dla każdego kroku w oparciu o wartości Q i wykorzystuje stratę rankingową w parach, aby zoptymalizować prognozę wyniku PPM dla każdego etapu wnioskowania, uzyskując niezawodne etykietowanie. W tym podejściu unika się konwencjonalnych metod, które bezpośrednio wykorzystują wartości Q jako etykiety nagród, co z natury jest hałaśliwe i nieprecyzyjne w przypadku stopniowego przypisywania nagród.”
Na koniec czterorundowy przepis na samoewolucję, który stopniowo buduje zarówno granicę, jak i model polityki i PPM od podstaw.
 Procedura wnioskowania rSTar-Math (Źródło: artykuł naukowy)
Procedura wnioskowania rSTar-Math (Źródło: artykuł naukowy)
Wydajność, która stanowi wyzwanie dla większych modeli
rStar-Math wyznacza nowe standardy w testach porównawczych rozumowania matematycznego, osiągając wyniki porównywalne, a w niektórych przypadkach przewyższające wyniki większych systemów sztucznej inteligencji.
W Zbiór danych GSM8K, test rozumowania matematycznego, po integracji dokładność modelu zawierającego 7 miliardów parametrów wzrosła z 12,51% do 63,91% rStar-Math. W American Invitational Mathematics Examination (AIME) model rozwiązał 53,3% problemów, plasując go wśród 20% najlepszych uczniów szkół średnich.
Wyniki zestawu danych MATH były równie imponujące, a rStar-Math osiągnął współczynnik dokładności na poziomie 90%, przewyższając wersję zapoznawczą OpenAI o1.
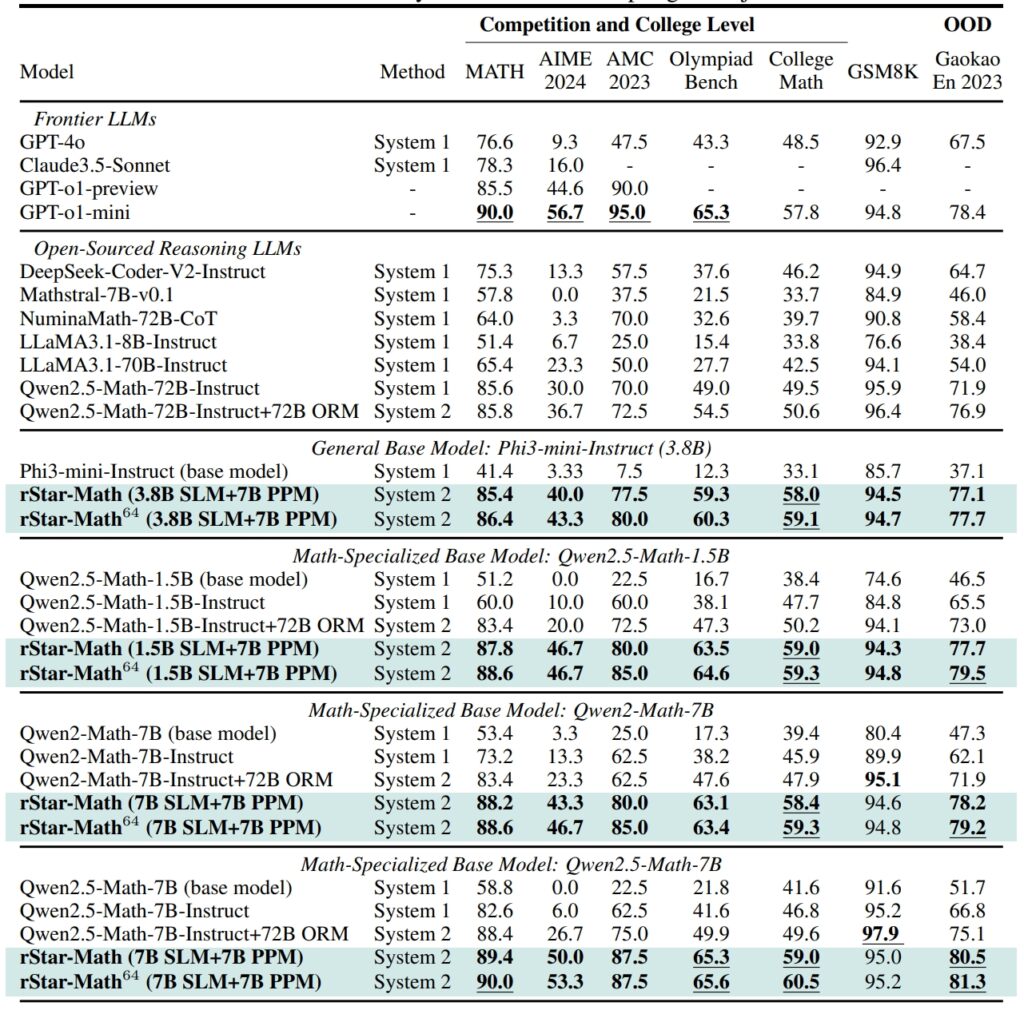 Wydajność rStar-Math i innych rozwiązań z pogranicza LLM w zakresie najbardziej wymagających testów matematycznych (źródło: artykuł badawczy)
Wydajność rStar-Math i innych rozwiązań z pogranicza LLM w zakresie najbardziej wymagających testów matematycznych (źródło: artykuł badawczy)
Te osiągnięcia podkreślają zdolność frameworka do umożliwienia SLM radzenia sobie z zadaniami, które wcześniej były zdominowane przez duże modele wymagające dużych zasobów. Kładąc nacisk na logiczną spójność i sprawdzalne etapy pośrednie, rStar-Math rozwiązuje jedno z najbardziej uporczywych wyzwań sztucznej inteligencji: zapewnienie niezawodnego rozumowania w złożonych przestrzeniach problemowych.
Innowacje techniczne napędzające rStar-Math
Ewolucja od rStar do rStar-Math wprowadza kilka kluczowych osiągnięć. Integracja MCTS pozostaje kluczowa dla ram, umożliwiając modelowi badanie różnych ścieżek rozumowania i ustalanie priorytetów dla najbardziej obiecujących.
Dodanie rozumowania CoT, skupiającego się na weryfikacji kodu, zapewnia, że wyniki są zarówno możliwe do zinterpretowania, jak i dokładne.
Powiązane: QwQ-32B firmy Alibaba-Preview dołącza do bitwy na rozumowanie modelu AI z OpenAI
Być może najbardziej transformacyjny jest samoewolucyjny proces szkoleniowy rStar-Math. W ciągu czterech rund iteracyjnych ramy udoskonalają swój model polityki i PPM, włączając na każdym etapie dane wyższej jakości.
To iteracyjne podejście pozwala na ciągłe doskonalenie modelu i osiąganie najnowocześniejszych wyników bez polegania na destylacji z większych modeli.
Porównanie rStar-Math do OpenAI o1
Podczas gdy Microsoft koncentruje się na optymalizacji mniejszych modeli, OpenAI w dalszym ciągu priorytetowo traktuje skalowanie swoich systemów.
Tryb o1 Pro, wprowadzony w grudniu 2024 r. w ramach planu ChatGPT Pro, oferuje zaawansowane możliwości wnioskowania dostosowane do zastosowań o wysokich stawkach, takich jak kodowanie i badania naukowe. OpenAI poinformowało, że tryb o1 Pro osiągnął 86% wskaźnik dokładności w AIME i 90% wskaźnik sukcesu w testach porównawczych kodowania, takich jak Codeforces.
rStar-Math reprezentuje zmianę w innowacjach AI, rzucając wyzwanie branży skupienie się na większych modelach jako główny sposób osiągnięcia zaawansowanego rozumowania. Udoskonalając SLM za pomocą optymalizacji specyficznych dla domeny, Microsoft oferuje zrównoważoną alternatywę, która zmniejsza koszty obliczeniowe i wpływ na środowisko.
Powiązane: Ujednolicenie przemyślane: strategia bezpieczeństwa OpenAI dla modeli myślenia o1 i o3
Sukces struktury w zakresie rozumowania matematycznego otwiera drzwi do szerszych zastosowań, od edukacji do badań naukowych.
Naukowcy planują udostępnić kod i dane rStar-Math w serwisie GitHub, torując drogę do dalszej współpracy i rozwoju. Ta przejrzystość odzwierciedla podejście firmy Microsoft do udostępniania wysokowydajnych narzędzi AI szerszemu gronu odbiorców, w tym instytucjom akademickim i organizacjom średniej wielkości.
Powiązane: Półanaliza: nie, skalowanie AI nie jest możliwe’t spowalnia
W miarę nasilenia się konkurencji między Microsoftem a OpenAI postępy wprowadzone przez rStar-Math podkreślają potencjał mniejszych modeli w zakresie kwestionowania dominacji większych systemów. Stawiając na pierwszym miejscu wydajność i dokładność, rStar-Math wyznacza nowy punkt odniesienia dla możliwości kompaktowych systemów AI.