Badacze z Sakana AI, startupu AI z siedzibą w Tokio, wprowadzili nowatorski system optymalizacji pamięci, który zwiększa wydajność modeli opartych na transformatorach, w tym duże modele językowe (LLM).
Metoda zwana modelami pamięci neuronowej (NAMM) jest dostępna w pełnym kodzie szkoleniowym na GitHub, zmniejsza zużycie pamięci nawet o 75%, poprawiając jednocześnie ogólną wydajność. Koncentrując się na kluczowych tokenach i usuwając zbędne informacje, NAMM rozwiązują jedno z wyzwań współczesnej sztucznej inteligencji wymagających największych zasobów: zarządzanie długimi oknami kontekstowymi.
Modele transformatorów, będące podstawą LLM, opierają się na „oknach kontekstowych”. do przetwarzania danych wejściowych. Te okna kontekstowe przechowują „pary klucz-wartość” (pamięć podręczna KV) dla każdego tokena w sekwencji wejściowej.
Wraz ze wzrostem długości okna – obecnie sięgającej setek tysięcy tokenów – koszty obliczeń gwałtownie rosną. Wcześniejsze rozwiązania próbowały zmniejszyć ten koszt poprzez ręczne czyszczenie tokenów lub strategie heurystyczne, ale często powodowały pogorszenie wydajności. Jednakże NAMM wykorzystują sieci neuronowe wyszkolone poprzez ewolucyjną optymalizację do automatyzacji i udoskonalenia procesu zarządzania pamięcią.
Optymalizacja pamięci za pomocą NAMM
NAMM analizują wartości uwagi generowane przez Transformers w celu określenia ważności tokenu. Przetwarzają te wartości w spektrogramy – reprezentacje oparte na częstotliwościach, powszechnie stosowane w przetwarzaniu dźwięku i sygnałów – w celu skompresowania i wyodrębnienia kluczowych cech wzorców uwagi.
Informacje te są następnie przekazywane przez lekką sieć neuronową, która przypisuje każdemu tokenowi ocenę, decydując, czy należy go zachować, czy odrzucić.
Sakana AI podkreśla, w jaki sposób algorytmy ewolucyjne napędzają NAMM sukces. W przeciwieństwie do tradycyjnych metod opartych na gradiencie, które są niezgodne z decyzjami binarnymi, takimi jak „zapamiętaj” czy „zapomnij”, optymalizacja ewolucyjna iteracyjnie testuje i udoskonala strategie pamięci, aby zmaksymalizować wydajność dalszej części procesu.
„Ewolucja z natury pokonuje niezróżnicowalność naszych operacji zarządzania pamięcią, które obejmują binarne wyniki „zapamiętaj” lub „zapomnij”” – wyjaśniają badacze.
Udowodnione wyniki w testach porównawczych
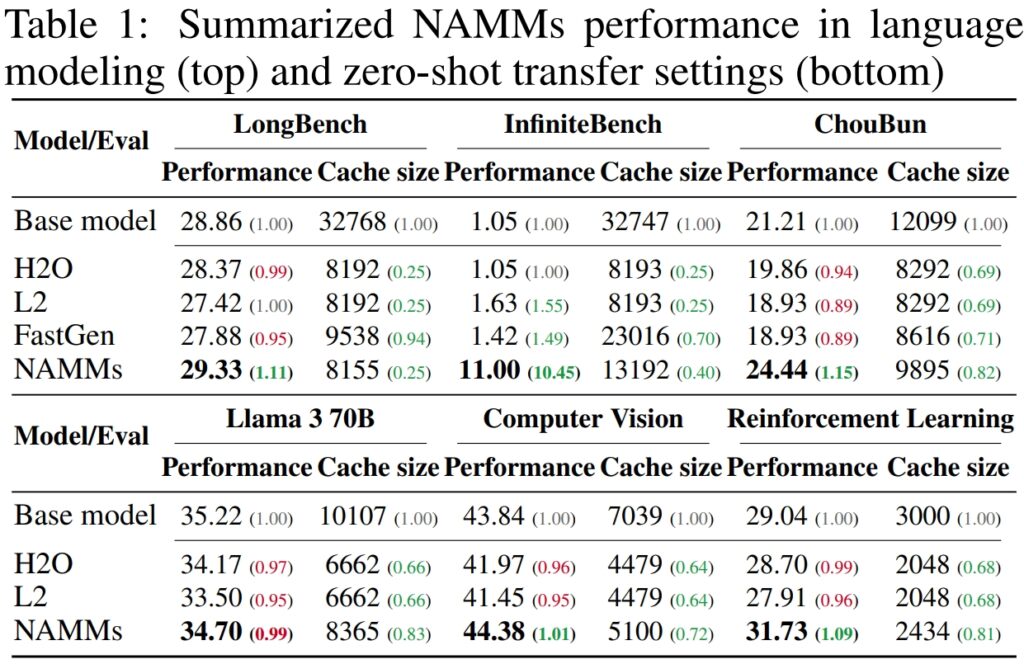
Aby zweryfikować wydajność i efektywność modeli neuronowej pamięci uwagi (NAMM), Sakana AI przeprowadziła szeroko zakrojone testy w wielu wiodących w branży testach porównawczych zaprojektowanych w celu oceny przetwarzania długotekstowego i możliwości wielozadaniowych. Wyniki znacząco podkreśliły zdolność NAMM poprawić wydajność, jednocześnie zmniejszając wymagania dotyczące pamięci, udowadniając swoją skuteczność w różnych ramach oceny.
W LongBench, benchmarku stworzone specjalnie do pomiaru wydajności modeli w zadaniach o długim kontekście, NAMM osiągnęły poprawę dokładności o 11% w porównaniu z pełnokontekstowym modelem bazowym. Poprawę tę osiągnięto przy jednoczesnym zmniejszeniu zużycia pamięci o 75%, co podkreśla skuteczność metody w zarządzaniu pamięcią podręczną typu klucz-wartość (KV).
Dzięki inteligentnemu czyszczeniu mniej istotnych tokenów NAMM umożliwiły modelowi skupienie się na krytycznym kontekście bez poświęcania wyników, co czyni go idealnym rozwiązaniem w przypadku scenariuszy wymagających rozszerzonych danych wejściowych, takich jak analiza dokumentów lub odpowiadanie na pytania w dłuższej formie.
p>
W przypadku InfiniteBench test porównawczy, który wypycha modele do ich limity z wyjątkowo długimi sekwencjami – niektóre przekraczające 200 000 tokenów – NAMM wykazały zdolność do skutecznego skalowania.
Podczas gdy modele bazowe borykały się z wymaganiami obliczeniowymi związanymi z tak długimi danymi wejściowymi, NAMM osiągnęły dramatyczny wzrost wydajności, zwiększając dokładność z 1,05% do 11,00%.
Wynik ten jest szczególnie godny uwagi, ponieważ pokazuje zdolność NAMM do obsługi bardzo długich kontekstów, co staje się coraz bardziej istotne w zastosowaniach takich jak przetwarzanie literatury naukowej, dokumentów prawnych lub dużych repozytoriów kodu, w których rozmiary danych wejściowych tokenów są ogromne.
Na podstawie testu porównawczego ChouBun opracowanego przez Sakana AI, który ocenia rozumowanie długokontekstowe dla języka japońskiego zadań, NAMM zapewniły poprawę o 15% w stosunku do wartości wyjściowych. ChouBun wypełnia lukę w istniejących testach porównawczych, które zwykle koncentrują się na językach angielskim i chińskim, testując modele na rozszerzonym wprowadzanym tekście japońskim.
Sukces NAMM w ChouBun podkreśla ich wszechstronność w różnych językach i dowodzi ich solidności w obsłudze danych wejściowych w języku innym niż angielski – kluczowa cecha w globalnych zastosowaniach sztucznej inteligencji. NAMM były w stanie skutecznie zachować treść kontekstową, odrzucając jednocześnie powtórzenia gramatyczne i mniej znaczące tokeny, dzięki czemu model mógł skuteczniej wykonywać zadania, takie jak długotrwałe podsumowywanie i zrozumienie w języku japońskim.
 Źródło: Sakana AI
Źródło: Sakana AI
The Wyniki łącznie pokazują, że NAMM przodują w optymalizacji wykorzystania pamięci bez utraty dokładności. Niezależnie od tego, czy oceniane są na podstawie zadań wymagających wyjątkowo długich sekwencji, czy w kontekście języka innego niż angielski, NAMM stale przewyższają modele bazowe, osiągając zarówno wydajność obliczeniową, jak i lepsze wyniki.
To połączenie oszczędności pamięci i wzrostu dokładności sprawia, że NAMM jest wielkim postępem w systemach sztucznej inteligencji dla przedsiębiorstw, których zadaniem jest obsługa ogromnych i złożonych danych wejściowych.
Wyniki są szczególnie godne uwagi w porównaniu z wcześniejszymi metodami, takimi jak H₂O i L2, który poświęcił wydajność na rzecz wydajności. Z drugiej strony NAMM zapewniają jedno i drugie.
„Nasze wyniki pokazują, że NAMM skutecznie zapewniają stałą poprawę zarówno pod względem wydajności, jak i wydajności w porównaniu z podstawowymi transformatorami” – stwierdzają badacze.
Zastosowania międzymodalne: poza językiem
Jednym z najbardziej imponujących odkryć była zdolność NAMM do przenoszenia zero-shot na inne zadania i sposoby wprowadzania danych
Jeden z najbardziej niezwykłymi aspektami modeli pamięci neuronowej (NAMM) jest ich zdolność do płynnego przenoszenia między różnymi zadaniami i sposobami wprowadzania danych — wykraczając poza tradycyjne aplikacje oparte na języku.
W przeciwieństwie do innych metod optymalizacji pamięci, które często wymagają ponownego szkolenia dostrajając każdą dziedzinę, NAMM utrzymują korzyści w zakresie wydajności i wydajności bez dodatkowych dostosowań. Eksperymenty Sakana AI wykazały tę wszechstronność w dwóch kluczowych obszarach: widzenie komputerowe i uczenie się przez wzmacnianie, które stanowią wyjątkowe wyzwania. dla modeli z transformatorem.
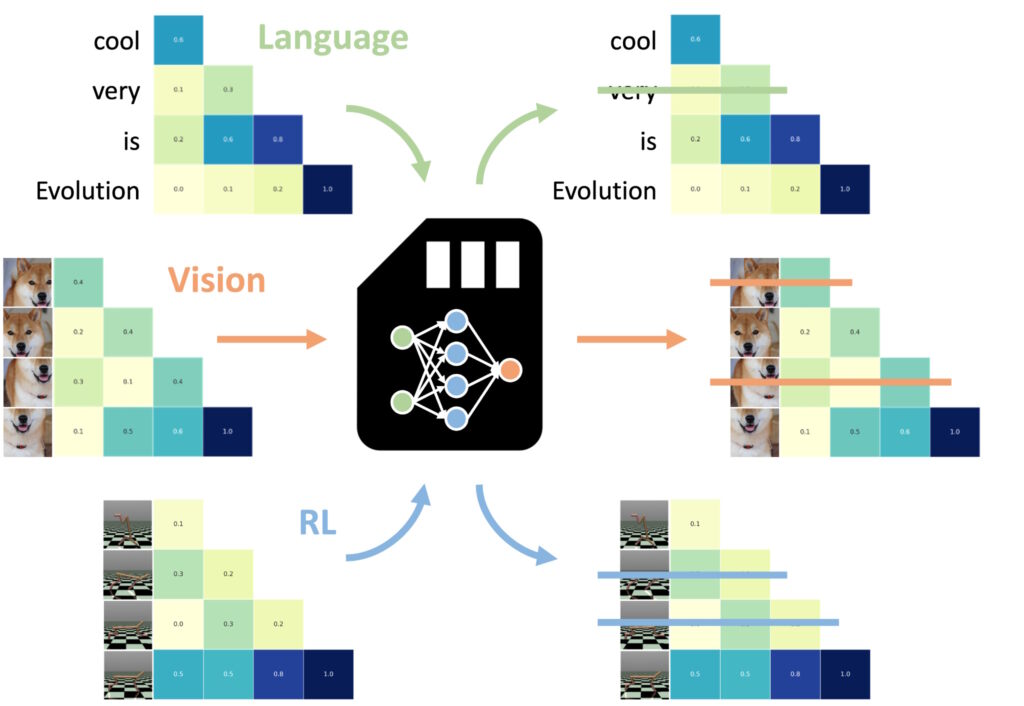 NAMM przeszkolone w zakresie języka mogą wynosić zero-strzał przeniesiony do innych transformatorów w różnych modalnościach wejściowych i domenach zadań. (Zdj.: Sakana AI)
NAMM przeszkolone w zakresie języka mogą wynosić zero-strzał przeniesiony do innych transformatorów w różnych modalnościach wejściowych i domenach zadań. (Zdj.: Sakana AI)
W wizji komputerowej NAMM oceniano przy użyciu modelu Llava Next Video, Transformator przeznaczony do przetwarzania długich sekwencji wideo. Filmy z natury zawierają ogromne ilości zbędnych danych, takich jak powtarzające się klatki lub drobne różnice, które dostarczają niewiele dodatkowych informacji.
NAMM automatycznie identyfikowały i odrzucały te zbędne klatki podczas wnioskowania, skutecznie kompresując okno kontekstowe bez pogarszania zdolności modelu do interpretacji treści wideo.
Na przykład NAMM zachowywały klatki z kluczowymi szczegółami wizualnymi – takimi jak zmiany akcji, interakcje obiektów lub zdarzenia krytyczne – usuwając klatki powtarzalne lub statyczne. Spowodowało to poprawę wydajności przetwarzania, umożliwiając skupienie modelu na najbardziej istotnych elementach wizualnych, zachowując w ten sposób dokładność przy jednoczesnym obniżeniu kosztów obliczeniowych.
W uczeniu się przez wzmacnianie zastosowano NAMM do Decision Transformer, model zaprojektowany do przetwarzania sekwencji działań, obserwacji i nagród w celu optymalizacji zadania decyzyjne. Zadania polegające na uczeniu się przez wzmacnianie często obejmują długie sekwencje danych wejściowych o różnym poziomie istotności, w przypadku których nieoptymalne lub zbędne działania mogą utrudniać wykonanie.
NAMM poradziły sobie z tym wyzwaniem, selektywnie usuwając tokeny odpowiadające nieefektywnym działaniom i informacjom o niskiej wartości, zachowując jednocześnie te, które są kluczowe dla osiągnięcia lepszych wyników.
Na przykład w zadaniach takich jak Hopper i Walker2d — które polegają na kontrolowaniu wirtualnych agentów w ciągłym ruchu — NAMM poprawiły wydajność o ponad 9%. Odfiltrowując nieoptymalne ruchy lub niepotrzebne szczegóły, Transformator Decyzji osiągnął bardziej wydajne i efektywne uczenie się, koncentrując swoją moc obliczeniową na decyzjach, które zmaksymalizowały sukces w zadaniu.
Wyniki te podkreślają zdolność adaptacji NAMM w bardzo różnych dziedzinach. Niezależnie od tego, czy przetwarzają klatki wideo w modelach wizyjnych, czy optymalizują sekwencje działań w procesie uczenia się przez wzmacnianie, NAMM wykazały zdolność do zwiększania wydajności, zmniejszania zużycia zasobów i utrzymywania dokładności modelu – a wszystko to bez konieczności ponownego szkolenia.
NAMM uczą się zapominać prawie wyłącznie części redundantnych klatek wideo zamiast znaczników językowych opisujących końcowy komunikat, zauważa artykuł, podkreślając możliwości adaptacji NAMM.
Podstawy techniczne NAMM
Wydajność i skuteczność modeli pamięci uwagi neuronowej (NAMM) leży w ich usprawnionym i systematycznym procesie wykonywania, który umożliwia precyzyjne czyszczenie tokenów bez ręcznej interwencji. Proces ten opiera się na trzech podstawowych komponentach: spektrogramach uwagi, kompresji cech i automatycznej punktacji.
NAMM dynamicznie dostosowują swoje zachowanie w zależności od wymagań zadania i głębokości warstwy Transformatora. Wczesne warstwy traktują priorytetowo „globalny” kontekst, taki jak opisy zadań, podczas gdy głębsze warstwy zachowują „lokalne” szczegóły specyficzne dla zadania. Na przykład w zadaniach związanych z kodowaniem NAMM odrzuciły komentarze i szablonowy kod; w zadaniach związanych z językiem naturalnym wyeliminowały powtórzenia gramatyczne, zachowując jednocześnie kluczową treść.
Ta adaptacyjna retencja tokenów zapewnia, że modele pozostają skupione na istotnych informacjach podczas całego przetwarzania, co poprawia szybkość i dokładność.
Pierwszy krok polega na wygenerowaniu spektrogramów uwagi. Transformatory obliczają „wartości uwagi” w każdej warstwie, aby określić względne znaczenie każdego tokenu w oknie kontekstowym. NAMM przekształcają te wartości uwagi w reprezentacje oparte na częstotliwości przy użyciu krótkoczasowej transformaty Fouriera (STFT).
STFT to szeroko stosowana technika przetwarzania sygnału, która rozkłada sekwencję na zlokalizowane składowe częstotliwości w czasie, zapewniając zwartą, ale szczegółową reprezentację ważności tokenu poprzez zastosowanie STFT, NAMM konwertuje surowe sekwencje uwagi na dane przypominające spektrogram, umożliwiając wyraźniejszą analizę tego, które tokeny w znaczący sposób przyczyniają się do wyników modelu.
Następnie stosowana jest Kompresja funkcji w celu zmniejszenia wymiarowość danych spektrogramu przy jednoczesnym zachowaniu ich zasadniczych właściwości. Osiąga się to za pomocą wykładniczej średniej kroczącej (EMA), metody matematycznej, która kompresuje historyczne wzorce uwagi w zwarte podsumowanie o stałym rozmiarze. EMA zapewnia, że reprezentacje pozostają lekkie i łatwe w zarządzaniu, umożliwiając NAMM wydajną analizę długich sekwencji uwagi przy jednoczesnej minimalizacji narzutu obliczeniowego.
Ostatnim krokiem jest Ocenianie i czyszczenie, podczas którego NAMM korzystają z lekkiego klasyfikator sieci neuronowej do oceny skompresowanych reprezentacji tokenów i przypisywania ocen na podstawie ich ważności. Tokeny z wynikami poniżej określonego progu są usuwane z okna kontekstowego, skutecznie „zapominając” nieprzydatne lub zbędne szczegóły. Ten mechanizm punktacji umożliwia NAMM nadawanie priorytetów krytycznym tokenom, które mają wpływ na proces decyzyjny modelu, jednocześnie odrzucając mniej istotne dane.
To, co czyni NAMM szczególnie skutecznymi, to ich poleganie na optymalizacji ewolucyjnej w celu udoskonalenia tego procesu Tradycyjne metody optymalizacji, takie jak metoda gradientowa, borykają się z problemem nieróżniczkowalnym zadania — takie jak podjęcie decyzji, czy token należy zachować, czy odrzucić.
Zamiast tego NAMM korzystają z iteracyjnego algorytmu ewolucyjnego, inspirowanego doborem naturalnym, w celu „mutowania” i „wyboru” najskuteczniejszych strategii zarządzania pamięcią. czasie Dzięki wielokrotnym próbom system ewoluuje, aby automatycznie ustalać priorytety najważniejszych tokenów, osiągając równowagę między wydajnością a wydajnością pamięci bez konieczności ręcznego dostrajania.
To usprawnione wykonanie — połączenie oparte na spektrogramie. analiza tokenów, wydajna kompresja i automatyczne czyszczenie — umożliwiają NAMM zapewnienie zarówno znacznych oszczędności pamięci, jak i wzrostu wydajności w różnorodnych zadaniach opartych na transformatorach. Zmniejszając wymagania obliczeniowe przy jednoczesnym zachowaniu lub poprawie dokładności, NAMM wyznaczają nowy punkt odniesienia w zakresie wydajnego zarządzania pamięcią w nowoczesnych modelach sztucznej inteligencji.
Co dalej z transformatorami?
Sakana AI wierzy, że NAMM to dopiero początek. Chociaż obecne prace skupiają się na optymalizacji wstępnie wytrenowanych modeli na etapie wnioskowania, przyszłe badania mogą włączyć NAMM do samego procesu uczenia. Może to umożliwić modelom natywne uczenie się strategii zarządzania pamięcią, dalsze wydłużanie okien kontekstowych i zwiększanie wydajności w różnych domenach.
„Te prace dopiero rozpoczęły się od eksploracji przestrzeni projektowej naszych modeli pamięci, co jak przewidujemy może zaoferować wiele nowych możliwości udoskonalenia przyszłych generacji transformatorów” – podsumowuje zespół.
Udowodniona zdolność NAMM do skalowania wydajności, obniżania kosztów i dostosowywania się do różnych modalności wyznacza nowy standard wydajności wielkoskalowych Modele sztucznej inteligencji.