Mark Russinovich, dyrektor ds. technologii w Microsoft Azure, podkreślił rosnące obawy dotyczące bezpieczeństwa związane z generatywną sztuczną inteligencją. Przemawiając na konferencji Microsoft Build 2024 w Seattle Russinovich podkreślił różnorodne szereg zagrożeń, z którymi muszą się uporać dyrektorzy ds. bezpieczeństwa informacji (CISO) i programiści, integrując technologie generatywnej sztucznej inteligencji. Podkreślił konieczność multidyscyplinarnego podejścia do bezpieczeństwa sztucznej inteligencji, które obejmuje analizę zagrożeń pod różnymi kątami, takimi jak aplikacje AI, kod modelu bazowego, żądania API, dane szkoleniowe i potencjalne backdoory.
Zatruwanie danych i błędna klasyfikacja modelu
Jednym z głównych problemów poruszonych przez Russinovicha jest zatruwanie danych. Podczas tych ataków przeciwnicy manipulują zbiorami danych używanymi do uczenia modeli sztucznej inteligencji lub uczenia maszynowego, co prowadzi do uszkodzonych wyników. Zilustrował to przykładem, w którym szum cyfrowy dodany do obrazu spowodował, że sztuczna inteligencja błędnie zaklasyfikowała pandę jako małpę. Ten typ ataku może być szczególnie podstępny, ponieważ nawet niewielka zmiana, np. wstawienie backdoora, może znacząco wpłynąć na wydajność modelu.
Russinovich omówił także kwestię backdoory w modelach AI. Backdoory, choć często postrzegane jako luka w zabezpieczeniach, mogą również służyć do weryfikacji autentyczności i integralności modelu. Wyjaśnił, że backdoory można wykorzystać do pobrania odcisków palców modelu, co umożliwi oprogramowaniu sprawdzenie jego autentyczności. Wiąże się to z dodaniem do kodu unikalnych pytań, których prawdziwi użytkownicy raczej nie zadają, zapewniając w ten sposób integralność modelu.
Techniki szybkiego wstrzyknięcia
Kolejnym znaczącym zagrożeniem, na które zwrócił uwagę Russinovich, są techniki szybkiego wstrzyknięcia. Obejmują one wstawianie ukrytych tekstów do dialogów, co może prowadzić do wycieków danych lub wpływać na zachowanie sztucznej inteligencji wykraczające poza zamierzone działania. Widzieliśmy, jak GPT-4 V OpenAI jest podatny na tego typu ataki. Pokazał, w jaki sposób fragment ukrytego tekstu wstawiony do dialogu może spowodować wyciek prywatnych danych, co przypomina wykorzystanie skryptów krzyżowych w bezpieczeństwie sieci. Wymaga to wzajemnego izolowania użytkowników, sesji i treści, aby zapobiec takim atakom.
Głównym problemem Microsoftu są kwestie związane z ujawnianiem wrażliwych danych, technikami jailbreakowania w celu wyprzedzenia modeli sztucznej inteligencji i wymuszaniem-party aplikacje i wtyczki modelowe umożliwiające ominięcie filtrów bezpieczeństwa lub tworzenie treści objętych ograniczeniami. Russinovich wspomniał o konkretnej metodzie ataku, Crescendo, która może ominąć zabezpieczenia treści i nakłonić model do wygenerowania szkodliwych treści.
Holistyczne podejście do bezpieczeństwa sztucznej inteligencji
Russinovich porównał modele sztucznej inteligencji do „naprawdę inteligentnych, ale młodszych lub naiwnych pracowników”, którzy pomimo swojej inteligencji są podatni na manipulację i mogą działać wbrew zasadom organizacji bez ścisłego nadzoru. Podkreślił nieodłączne ryzyko bezpieczeństwa związane z dużymi modelami językowymi (LLM) oraz potrzeba rygorystycznych zabezpieczeń, aby złagodzić te luki.
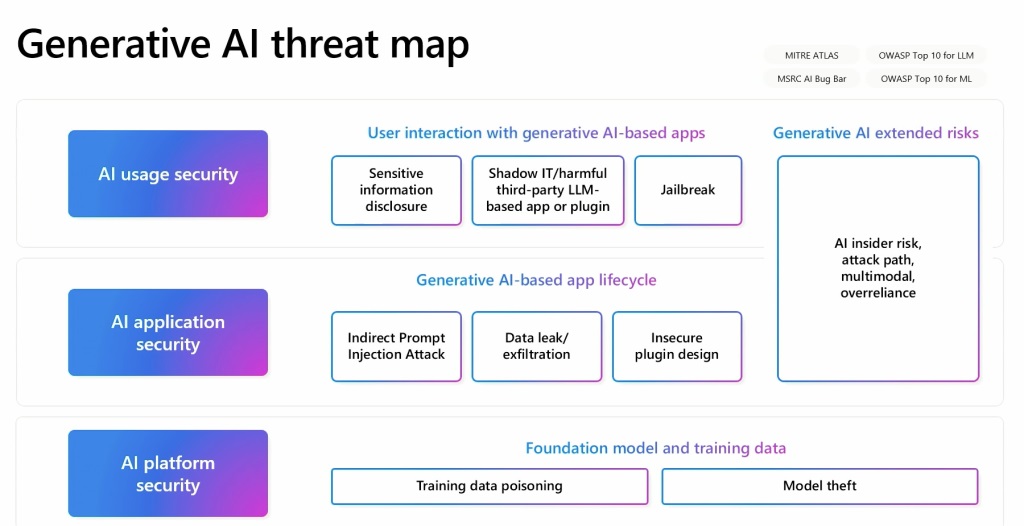
Russinovich opracował generatywną mapę zagrożeń AI, która przedstawia powiązania między tymi różnymi elementami. Mapa ta służy jako kluczowe narzędzie do zrozumienia wieloaspektowego charakteru bezpieczeństwa sztucznej inteligencji i rozwiązania problemu Podał przykład tego, jak umieszczenie zanieczyszczonych danych na stronie Wikipedii, o której wiadomo, że jest źródłem danych, może prowadzić do długoterminowych problemów, nawet jeśli dane zostaną później poprawione. To sprawia, że śledzenie zanieczyszczonych danych jest trudne, ponieważ już ich nie ma istnieje w oryginalnym źródle.