Zespół Meta zajmujący się sztuczną inteligencją znajduje się pod dużą presją po wypuszczeniu na rynek modelu R1 firmy DeepSeek, który rzucił wyzwanie branży sztucznej inteligencji swoją niespotykaną wydajnością i wydajnością.
Anonimowe posty na profesjonalnej platformie sieciowej Blind ujawniają zamieszanie w szeregach Meta, a inżynierowie opisują gorączkowe wysiłki mające na celu zrozumienie i powtórzenie sukcesu DeepSeek, zmagając się jednocześnie z wewnętrznymi brakami wydajności i błędami przywództwa.
Blind to anonimowa profesjonalna platforma sieciowa gdzie pracownicy mogą dzielić się informacjami, omawiać problemy w miejscu pracy i nawiązywać kontakty z kolegami z tej samej lub różnych branż. Posiada system weryfikacji zapewniający, że użytkownicy są rzeczywistymi pracownikami firm, dla których rzekomo pracują, i jest popularny przede wszystkim wśród profesjonalistów z branży technologicznej.
Powiązane: Jak DeepSeek R1 przewyższa ChatGPT o1 objęty sankcjami, redefiniuje wydajność sztucznej inteligencji przy użyciu zaledwie 2048 procesorów graficznych
Jeden anonimowy pracownik Meta, post pod nazwą „ngi” podsumował nastroje w dziale GenAI firmy Meta:
„Zaczęło się od DeepSeek V3 [model DeepSeek wydany w grudniu 2024 r.], w wyniku którego Llama 4 już wypada w wynikach testów porównawczych. Dodatkową obrazę dołożyła „nieznana chińska firma z budżetem szkoleniowym wynoszącym 5,5 miliona”. gorączkowo analizujemy DeepSeek i kopiujemy z niego wszystko, co się da.
Nawet nie przesadzam. Kierownictwo martwi się uzasadnieniem ogromnych kosztów organizacji GenAI. Jak poradziliby sobie z przywództwem, skoro każdy „lider” organizacji GenAI zarabia więcej, niż kosztuje całkowite przeszkolenie DeepSeek V3, a mamy dziesiątki takich „liderów”. DeepSeek R1 sprawił, że sytuacja była jeszcze bardziej przerażająca. Nie mogę ujawnić poufnych informacji, ale i tak wkrótce zostaną one upublicznione.
Powinna to być mała organizacja skupiająca się na inżynierii, ale ponieważ grupa ludzi chciała przyłączyć się do tej akcji i sztucznie zawyżać zatrudnienie w org, wszyscy tracą.”
Komentarze pracowników podkreślają wewnętrzne niezadowolenie z podejścia Meta do rozwoju sztucznej inteligencji, które wielu określa jako nadmiernie biurokratyczne, wymagające dużych zasobów i oparte na powierzchownych wskaźnikach, a nie na znaczących innowacja
Wydanie DeepSeek R1 ujawniło te niedociągnięcia i zmusiło jednego z największych graczy w branży AI do rozliczenia.
Powiązane: LLaMA AI Under Ogień – czego meta nie mówi o modelach „open source”
DeepSeek R1 wywołuje falę uderzeniową w amerykańskim sektorze technologicznym
Model R1 firmy DeepSeek, wydany 10 stycznia 2025 r., wywrócił do góry nogami globalny krajobraz sztucznej inteligencji, pokazując, że modele o wysokiej wydajności można opracować za ułamek kosztów typowych dla takich projektów.
Jak wynika z artykułu badawczego opublikowanego w grudniu 2024 r., korzystając z procesorów graficznych Nvidia H800 – układów niższej klasy objętych ograniczeniami kontroli eksportu w USA – inżynierowie DeepSeek wytrenowali ten model za mniej niż 6 milionów dolarów.
Te Procesory graficzne, celowo ograniczane w celu zachowania zgodności z amerykańskimi sankcjami, stwarzały wyjątkowe wyzwania, ale techniki optymalizacji DeepSeek pozwoliły zespołowi osiągnąć wydajność porównywalną z wiodącymi w branży modelami.
W testach porównawczych R1 obejmuje wynik 97,3% w MATH-500 i wynik 79,8% w AIME 2024, co plasuje go wśród najpotężniejszych systemów sztucznej inteligencji na świecie.
Wydajność DeepSeek R1, który również częściowo przewyższa model o1 OpenAI, nie tylko zachwiał zaufaniem do amerykańskich gigantów technologicznych, takich jak Meta, ale także wywołał znaczące reakcje rynku.
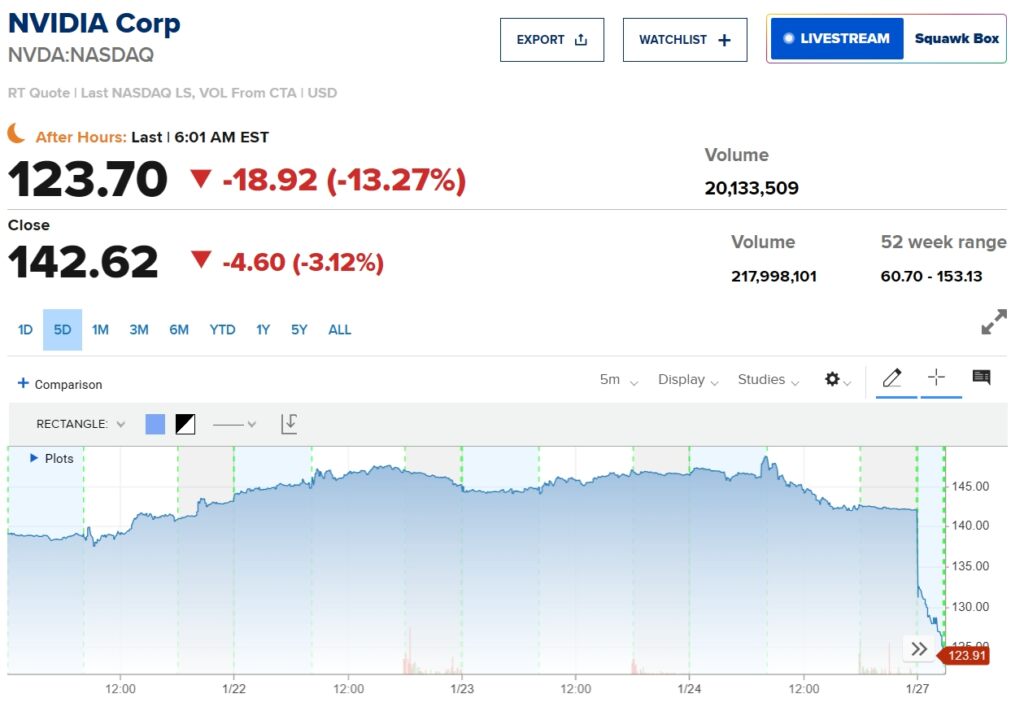
Po wprowadzeniu modelu na rynek akcje Nvidii spadły o ponad 13% w notowaniach przed otwarciem sesji, a kontrakty terminowe Nasdaq 100 spadły o ponad 5%. Tymczasem DeepSeek wspiął się na pierwsze miejsce w amerykańskim sklepie Apple App Store, przewyższając ChatGPT OpenAI pod względem pobrań.
Inżynierowie meta kwestionują poleganie na kosztownych szkoleniach z zakresu obliczeniowej sztucznej inteligencji
W Meta inżynierowie skrytykowali poleganie firmy na brutalnych mocy obliczeniowej, zamiast dążyć do innowacji opartych na wydajności.
Jeden z pracowników zauważył na temat Blind: Duża część kierownictwa dosłownie nie ma pojęcia (nawet dużo inżynierii) o leżącej u jego podstaw technologii i ciągle sprzedają kierownictwu zasadę „więcej procesorów graficznych=wygrana”. frustracja związana z kulturą „pogoni za wpływem”, opisującą ją jako wyścig o awanse, a nie zaangażowanie w znaczący postęp.
Wysiłki Meta w zakresie sztucznej inteligencji również zostały poddane analizie pod kątem braku zwinności w porównaniu z konkurencją. Model R1 firmy DeepSeek jest nie tylko ekonomiczny, ale także open source, co pozwala programistom na całym świecie badać i rozwijać jego architekturę.
Dyskusje The Blind ujawniają także szersze obawy branży. Pracownicy Google docenili destrukcyjny wpływ DeepSeek i dodali jedną uwagę: „To naprawdę szalone, co robi DeepSeek. To nie tylko Meta, oni rozpalają ogień pod tyłkiem OpenAI, Google i Anthropic. To dobrze, bo w czasie rzeczywistym widzimy, jak skuteczna jest otwarta konkurencja w zakresie innowacji”.
To nastawienie odzwierciedla rosnące przekonanie, że tradycyjne strategie wymagające dużych zasobów mogą nie gwarantować już dominacji w rozwoju sztucznej inteligencji.
Ta przejrzystość spotkała się z uznaniem liderów branży, w tym głównego specjalisty ds. sztucznej inteligencji firmy Meta, Yanna LeCuna, który napisał na LinkedIn: „DeepSeek czerpie korzyści z otwartych badań i otwartego oprogramowania (np. PyTorch i Llama z Meta). Wymyślili nowe pomysły i opracowali je w oparciu o pracę innych osób.”
Mark Zuckerberg podwaja inwestycje w infrastrukturę AI
W przeciwieństwie do tego Meta skupiła się na inwestycjach infrastrukturalnych na dużą skalę. Dyrektor generalny Mark Zuckerberg ogłosił niedawno plany wdrożenia ponad 1,3 miliona procesorów graficznych w 2025 roku i zainwestowania 60–65 miliardów dolarów w rozwój sztucznej inteligencji.
„To ogromny wysiłek, który w nadchodzących latach będzie napędzał nasze podstawowe produkty i działalność, odblokuje historyczne innowacje i umocni amerykańską wiodącą pozycję w dziedzinie technologii” – powiedział Zuckerberg w publicznym oświadczeniu na początku tego roku. Jednak plany te wydają się obecnie coraz bardziej sprzeczne z oszczędnym podejściem DeepSeek, stawiającym na wydajność.
Rozwój DeepSeek ponownie wywołał debaty na temat amerykańskich ograniczeń eksportu technologii związanych ze sztuczną inteligencją do Chin W 2021 r. administracja Bidena wdrożyła środki mające na celu ograniczenie dostępu Chin do zaawansowanych chipów, w tym procesorów graficznych Nvidia H100
Jednak zdolność DeepSeek do osiągania światowej klasy wyników przy ograniczonym sprzęcie podkreśla ograniczenia tej polityki poprzez gromadzenie zapasów Procesory graficzne H800, zanim sankcje weszły w życie w pełni i skupiając się na wydajności, firma DeepSeek zamieniła ograniczenia w zalety
Założyciel Liang Wenfeng, były menadżer funduszy hedgingowych, tak opisał strategię firmy: „Szacujemy, że najlepsze modele krajowe i zagraniczne mogą mieć jednokrotną lukę w strukturze modeli i dynamice szkolenia. Z tego powodu, aby osiągnąć ten sam efekt, musimy zużyć czterokrotnie większą moc obliczeniową. Musimy stale zmniejszać te luki”.
W miarę jak branża sztucznej inteligencji zmaga się z konsekwencjami sukcesu DeepSeek, Meta stoi przed pilną potrzebą dostosowania się. Pracownicy firmy jasno wyrazili swoje frustracje, wzywając do przejście w kierunku bardziej wydajnych strategii opartych na innowacjach Na razie model R1 firmy DeepSeek stanowi potężną demonstrację pomysłowej inżynierii, zmieniającej dynamikę konkurencyjności globalnego rozwoju sztucznej inteligencji.