DeepSeek, chiński start-up zajmujący się sztuczną inteligencją, zajął w zeszły weekend pierwsze miejsce w amerykańskim sklepie Apple App Store, wyprzedzając ChatGPT OpenAI pod względem pobrań.
Kamieniem milowym było udostępnienie 20 stycznia flagowego modelu rozumowania DeepSeek, R1, który szybko zyskał uznanie dzięki swojej zdolności do konkurowania z zaawansowanymi systemami sztucznej inteligencji przy wykorzystaniu ułamka typowo wymaganych zasobów.
> 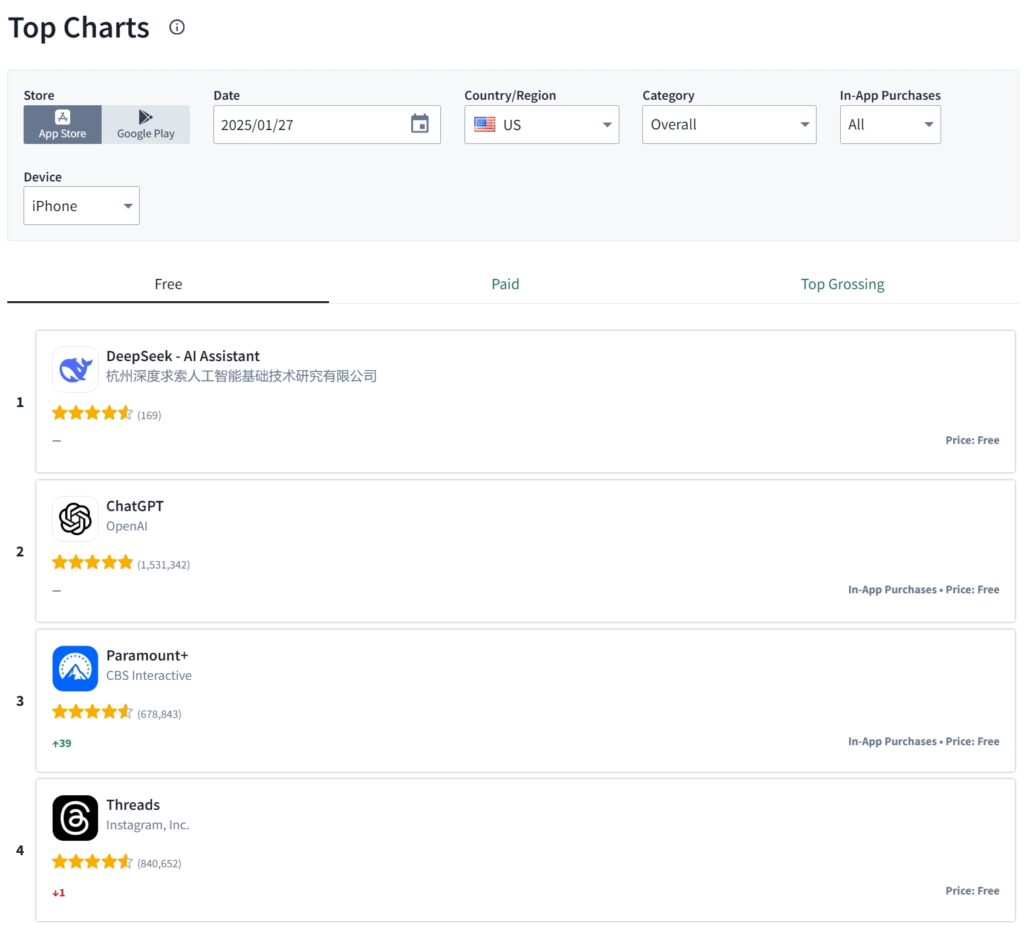 Źródło: Sensor Tower
Źródło: Sensor Tower
DeepSeek R1 zapewnia najnowocześniejszą wydajność, będąc jednocześnie cenzurowanym zgodnie z zasadami KPCh.
Szybki rozwój aplikacji opartej na R1 odzwierciedla innowacyjną inżynierię firmy DeepSeek i strategiczne wykorzystanie procesorów graficznych Nvidia H800, których eksport do Chin jest ograniczony ze względu na sankcje amerykańskie.
Powiązane: Dlaczego amerykańskie sankcje mogą utrudniać rozwój technologii w Chinach
Opracowując skuteczne metody szkoleniowe, firma z siedzibą w Hangzhou pokazała, że rozwój sztucznej inteligencji jest możliwe nawet przy ograniczeniach geopolitycznych. Rozwój ten podważa postrzeganie dominacji Stanów Zjednoczonych w dziedzinie sztucznej inteligencji i rodzi pytania o skuteczność ograniczeń eksportowych mających na celu ograniczenie możliwości technologicznych Chin.
Budowanie sztucznej inteligencji w warunkach ograniczeń: podejście oparte na zaradności
Z artykułu badawczego firmy wynika, że model R1 urządzenia DeepSeek został wytrenowany przy użyciu zaledwie 2048 procesorów graficznych Nvidia H800, a jego łączny koszt wyniósł niecałe 6 milionów dolarów wydany w grudniu 2024 r.
Te procesory graficzne to celowo dławione wersje układów H100 używanych przez amerykańskie firmy, takie jak OpenAI i Meta. Pomimo ograniczeń sprzętowych inżynierowie DeepSeek opracowali nowatorskie techniki optymalizacji, które pozwoliły R1 osiągnąć wyniki porównywalne z modelami trenowanymi na znacznie potężniejszej infrastrukturze.
Założyciel Liang Wenfeng, były zarządzający funduszem hedgingowym, wyjaśnił podejście firmy podczas wywiad z 36Kr. „Aby osiągnąć ten sam efekt, musimy zużywać cztery razy więcej mocy obliczeniowej”
Powiązane: DeepSeek AI Open Sources Seria VL2 modeli języka wizyjnego
Liang powiedział: „Musimy stale zmniejszać te luki”. Przezorność Lianga w gromadzeniu zapasów procesorów graficznych Nvidia przed wejściem w życie amerykańskich ograniczeń była kluczowym czynnikiem wpływającym na zdolność firmy do wprowadzania innowacji w trudnych warunkach.
Inżynierowie DeepSeek skupili się również na zmniejszeniu zużycia pamięci i narzutów obliczeniowych, zapewniając wysoką dokładność pomimo ograniczeń sprzętowych. Dimitris Papailiopoulos, główny badacz w laboratorium AI Frontiers firmy Microsoft, podkreślił wydajność projektu R1.
„Chcieliśmy uzyskać dokładne odpowiedzi, a nie szczegółowo opisywać każdy logiczny krok, co znacznie skróciło czas obliczeń przy jednoczesnym zachowaniu wysokiego poziomu efektywności” – powiedział MIT Technology Review.
Performance Testy porównawcze i uznanie w branży
Wyniki R1 były szczególnie dobre w testach technicznych, uzyskując wyniki 97,3% w MATH-500 i 79,8% w AIME 2024. Wyniki te plasują R1 obok serii o1 OpenAI, pokazując, że zasobooszczędny model DeepSeek może konkurować z liderami branży.
Oprócz swojego flagowego modelu, DeepSeek wypuścił także mniejsze wersje R1, które mogą działać na komputerach konsumenckich klasy sprzętowej. Ta dostępność zwiększyła atrakcyjność modelu wśród programistów, nauczycieli i hobbystów. W mediach społecznościowych użytkownicy udostępniali przykłady R1 obsługującego złożone zadania, takie jak tworzenie stron internetowych, kodowanie i zaawansowane rozwiązywanie problemów matematycznych.
Powiązane: Mistral AI debiutuje z Pixtral 12B do przetwarzania tekstu i obrazów
Osiągnięcia DeepSeek cieszą się uznaniem wybitnych osobistości ze sztucznej inteligencji pole. Yann LeCun, główny specjalista ds. sztucznej inteligencji w Meta, podkreślił rolę współpracy w zakresie open source w sukcesie DeepSeek. „„DeepSeek czerpie korzyści z otwartych badań i otwartego oprogramowania (np. PyTorch i Llama z Meta). Wpadli na nowe pomysły i opracowali je w oparciu o prace innych osób”. LeCun napisała na LinkedIn. Ponieważ ich prace są publikowane i mają otwarte oprogramowanie, każdy może z nich czerpać korzyści. Na tym polega siła otwartych badań i otwartego oprogramowania.”
Podobnie Marc Andreessen, współzałożyciel Andreessen Horowitz, opisał R1 jako „jedno z najbardziej niesamowitych przełomów, jakie kiedykolwiek widziałem”. Te rekomendacje podkreślają globalny wpływ pomysłowego podejścia DeepSeek do rozwoju sztucznej inteligencji.
Przystępność cenowa i etos otwartego oprogramowania
W przeciwieństwie do zastrzeżonych platform, takich jak ChatGPT OpenAI, firma DeepSeek przyjęła filozofię otwartego oprogramowania udostępnił publicznie ciężary, przepisy treningowe i dokumentację modelu R1, umożliwiając programistom na całym świecie powielanie jego pracy lub rozwijanie jej. Ta przejrzystość wyróżnia DeepSeek w branży często charakteryzującej się tajemnicą.
Przystępność również była kluczowym czynnikiem popularności R1. Korzystanie z aplikacji jest bezpłatne, a cena dostępu do interfejsu API jest znacznie niższa niż w przypadku ofert konkurencji. Te strategie cenowe w połączeniu z solidnymi możliwościami modelu uczyniły DeepSeek atrakcyjną opcją zarówno dla osób prywatnych, jak i firm.
Powiązane: LLaMA AI pod ostrzałem – czego meta nie mówi Ty o modelach „Open Source”
Geopolityczne implikacje sukcesu DeepSeek
Rozwój DeepSeek następuje w czasie wzmożonego napięcia geopolityczne między Stanami Zjednoczonymi a Chinami, szczególnie w obszarze sztucznej inteligencji
Od 2021 roku administracja Bidena rozszerzyła ograniczenia w eksporcie zaawansowanych chipów do Chin, mając na celu ograniczenie możliwości rozwoju kraju. konkurencyjne technologie AI, osiągnięcia DeepSeek sugerują jednak, że takie środki mogą nie całkowicie uniemożliwić innowacje.
Sukces firmy wywołał debaty w kręgach technologicznych w USA na temat niezamierzonych konsekwencji eksportu. Niektórzy menedżerowie twierdzą, że te ograniczenia mogą napędzać przedsiębiorcze innowacje wśród chińskich firm. Strategia Lianga polegająca na gromadzeniu zapasów procesorów graficznych i skupianiu się na wydajności udowodniła, że ograniczenia mogą pobudzić kreatywne rozwiązywanie problemów, a nie całkowicie je stłumić.
Powiązane: Nowe zasady eksportu chipów AI w USA spotykają się z ostrym sprzeciwem branży autorstwa Nvidia i inni
Szerszy ruch w chińskiej sztucznej inteligencji
Podejście DeepSeek do open source wpisuje się w szerszy trend w chińskim Sektor sztucznej inteligencji. Inne firmy, w tym Alibaba Cloud i 01.AI Kai-Fu Lee, również w ostatnich latach nadały priorytet inicjatywom związanym z oprogramowaniem open source. Liang opisał potrzebę zajęcia się, jak to nazywa, „luką w wydajności” między chińskimi i zachodnimi przedsięwzięciami w zakresie sztucznej inteligencji, wyjaśniając, że lokalne firmy często wymagają dwukrotnie większych zasobów, aby osiągnąć porównywalne wyniki.
Powiązane:
strong> Alibaba Qwen publikuje QVQ-72B-Preview wielomodalny model AI
W lipcu 2024 r. Liang stwierdził: „Szacujemy, że najlepsze modele krajowe i zagraniczne mogą mieć jednokrotną lukę w strukturze modelu i dynamika treningu Już z tego powodu musimy zużywać dwa razy więcej mocy obliczeniowej, aby osiągnąć ten sam efekt. Ponadto może wystąpić jednokrotna różnica w wydajności danych, to znaczy musimy zużywać dwukrotnie więcej dużo danych szkoleniowych i mocy obliczeniowej, aby osiągnąć ten sam efekt. Razem musimy zużywać czterokrotnie więcej mocy obliczeniowej. Musimy stale zmniejszać te luki.
Jego przywództwo zyskało uznanie DeepSeek zarówno w Chinach, jak i za granicą. W 2024 r. został zaproszony na spotkania wysokiego szczebla z chińskimi urzędnikami w celu omówienia strategii zwiększania zdolności kraju w zakresie sztucznej inteligencji.
Przyszłe wyzwania i możliwości
Jako DeepSeek nadal udoskonala swoje modele, firma stoi przed zarówno szansami, jak i wyzwaniami. Chociaż jego osiągnięcia udowodniły wykonalność zasobooszczędnej sztucznej inteligencji, pozostają pytania, czy takie podejście może być skalowane, aby konkurować z ogromnymi inwestycjami gigantów technologicznych, takich jak OpenAI i Meta.
W poście po wydaniu DeepSeek R1 , Mark Zuckerberg, dyrektor generalny Meta, podkreślił znaczenie inwestycji na dużą skalę w infrastrukturę sztucznej inteligencji, sying: „To będzie rok decydujący dla sztucznej inteligencji. Spodziewam się, że w 2025 roku Meta AI będzie wiodącym asystentem obsługującym ponad miliard ludzi, Llama 4 stanie się wiodącym, najnowocześniejszym modelem, a my zbudujemy inżyniera AI, który zacznie wnosić coraz większą ilość kodu do naszych wysiłków badawczo-rozwojowych. Aby to zapewnić, Meta buduje centrum danych o mocy ponad 2 GW, które jest tak duże, że obejmowałoby znaczną część Manhattanu.
W 25 roku udostępnimy online ~1 GW mocy obliczeniowej, a rok zakończymy z ponad 1,3 milionami procesorów graficznych. Planujemy zainwestować w tym roku 60–65 miliardów dolarów w nakłady inwestycyjne, jednocześnie znacznie powiększając nasze zespoły ds. sztucznej inteligencji i mamy kapitał, aby kontynuować inwestycje w nadchodzących latach. Jest to ogromny wysiłek, który w nadchodzących latach będzie napędzał nasze podstawowe produkty i działalność, odblokuje historyczne innowacje i wzmocni wiodącą pozycję Ameryki w technologii. Chodźmy budować!”
Na razie sukces DeepSeek z R1 pokazał, że innowacje nie są wyłącznie domeną najlepiej finansowanych graczy. Stawiając na pierwszym miejscu wydajność, przejrzystość i dostępność, firma osiągnęła trwały wpływ na światowy przemysł sztucznej inteligencji.