Chińskie laboratorium sztucznej inteligencji DeepSeek wprowadziło DeepSeek V3, swój kolejny model języka genopen source. Model obejmujący 671 miliardów parametrów wykorzystuje tak zwaną architekturę Mixture-of-Experts (MoE), aby połączyć wydajność obliczeniową z wysoką wydajnością.
Techniczne postępy DeepSeek V3 plasują go wśród najpotężniejszych systemów sztucznej inteligencji, mogących konkurować zarówno konkurencyjne rozwiązania typu open source, takie jak Meta Llama 3.1, jak i modele zastrzeżone, takie jak GPT-4o firmy OpenAI.
Ta publikacja podkreśla ważny moment w sztucznej inteligencji, pokazując, że systemy typu open source mogą konkurować z droższymi, zamkniętymi alternatywami, a w niektórych przypadkach przewyższać je.
Powiązane:
Chińskie cele modelu DeepSeek R1-Lite-Preview Lider OpenAI w dziedzinie automatycznego wnioskowania
Alibaba Qwen publikuje QVQ-72B-Preview wielomodalny model AI wnioskowania
Wydajna i innowacyjna architektura
Architektura DeepSeek V3 łączy w sobie dwa zaawansowane koncepcje umożliwiające osiągnięcie wyjątkowej wydajności i wydajności: wielogłowicowa uwaga utajona (MLA) i mieszanka ekspertów (MoE).
MLA zwiększa zdolność modelu do przetwarzania złożonych danych wejściowych, wykorzystując wiele głowic uwagi do skupiania się na różnych aspektach danych, wydobywając bogate i różnorodne informacje kontekstowe.
Z drugiej strony MoE aktywuje tylko podzbiór wszystkich 671 miliardów parametrów modelu — około 37 miliardów na zadanie — zapewniający efektywne wykorzystanie zasobów obliczeniowych bez utraty dokładności. Razem te mechanizmy umożliwiają DeepSeek V3 dostarczanie wysokiej jakości wyników przy jednoczesnym zmniejszeniu wymagań dotyczących infrastruktury.
Odpowiadając na typowe wyzwania w systemach MoE, takie jak nierówny rozkład obciążenia pomiędzy ekspertami, DeepSeek wprowadził pomocniczy, pozbawiony strat moduł obciążenia strategia równoważenia. Ta dynamiczna metoda przydziela zadania całej sieci ekspertów, zachowując spójność i maksymalizując dokładność zadań.
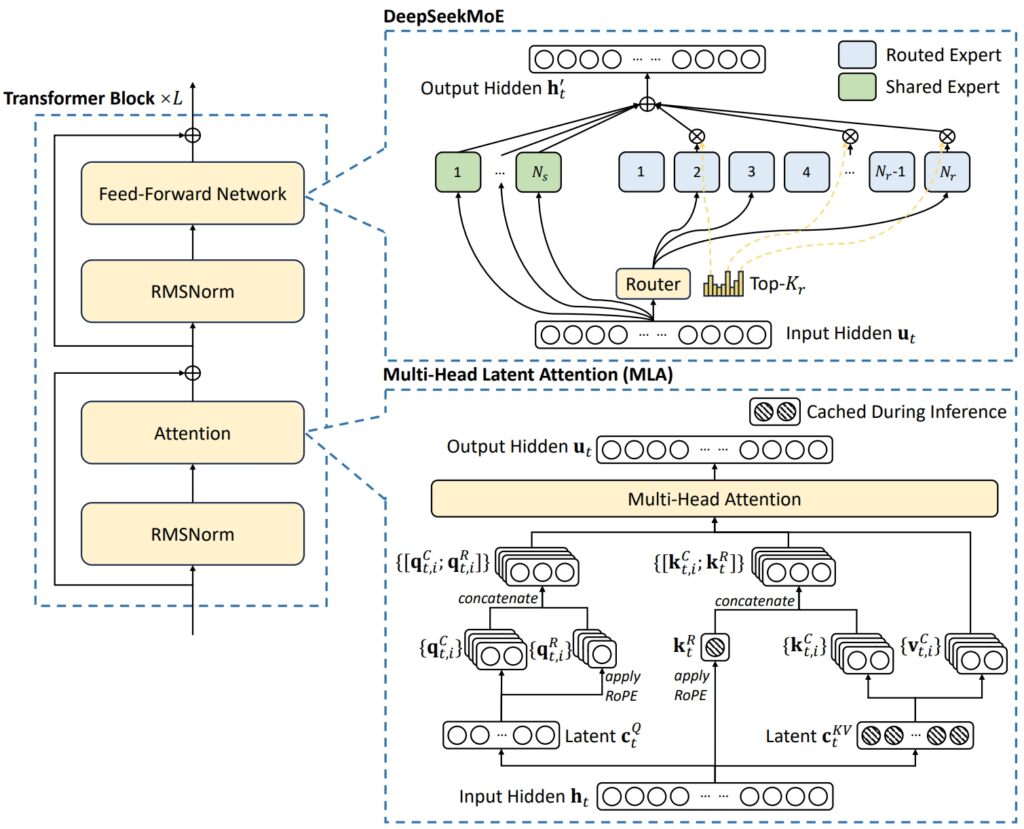 Ilustracja przedstawiająca podstawową architekturę DeepSeek-V3 (Zdjęcie: DeepSeek)
Ilustracja przedstawiająca podstawową architekturę DeepSeek-V3 (Zdjęcie: DeepSeek)
Aby jeszcze bardziej zwiększyć wydajność, DeepSeek V3 wykorzystuje Multi-Token Prediction (MTP), funkcja, która pozwala modelowi generować wiele tokenów jednocześnie, znacznie przyspieszając generowanie tekstu.
Ta funkcja nie tylko poprawia efektywność uczenia, ale także pozycjonuje model pod kątem szybszych zastosowań w świecie rzeczywistym , wzmacniając jej pozycję lidera w zakresie innowacji w zakresie sztucznej inteligencji typu open source.
Wydajność w testach porównawczych: lider w matematyce i kodowaniu
Pokaz wyników testów porównawczych DeepSeek V3 swoje wyjątkowe możliwości w szerokim spektrum zadań, umacniając swoją pozycję lidera wśród modeli sztucznej inteligencji typu open source.
Wykorzystując swoją zaawansowaną architekturę i obszerny zbiór danych szkoleniowych, model osiągnął najwyższą wydajność w testach matematycznych, kodowania i wielojęzycznych testach porównawczych, prezentując jednocześnie konkurencyjne wyniki w obszarach tradycyjnie zdominowanych przez modele o zamkniętym kodzie źródłowym, takie jak GPT OpenAI-4o i Anthropic Claude 3.5 Sonnet.
🚀 Przedstawiamy DeepSeek-V3!
Największy jeszcze krok do przodu:
⚡ 60 tokenów na sekundę (3 razy szybciej niż wersja 2!)
💪 Zwiększone możliwości
🛠 Zgodność z API nienaruszona
🌍 Modele i dokumenty w pełni open source🐋 1/n pic.twitter.com/p1dV9gJ2Sd
— DeepSeek (@deepseek_ai) 26 grudnia 2024
Matematyczne Rozumowanie
W sprawie Test Math-500, test porównawczy zaprojektowany do oceny umiejętności rozwiązywania problemów matematycznych, DeepSeek V3 uzyskał imponujący wynik 90,2. Wynik ten plasuje go przed wszystkimi konkurentami zajmującymi się oprogramowaniem open source, przy czym Qwen 2.5 uzyskał 80, a Llama 3.1 z wynikiem 73,8. Nawet GPT-4o, model o zamkniętym kodzie źródłowym, znany ze swoich ogólnych możliwości, uzyskał nieco niższy wynik i wyniósł 74,6. Ta wydajność podkreśla zaawansowane zdolności rozumowania DeepSeek V3, szczególnie w zadaniach wymagających intensywnych obliczeń, gdzie precyzja i logika mają kluczowe znaczenie.
Dodatkowo DeepSeek V3 wyróżniał się w innych testach specyficznych dla matematyki, takich jak:
MGSM (matematyka w szkole podstawowej): wynik 79,8, przewyższając Lamę 3,1 (69,9) i Qwen 2,5 (76,2). CMath (chińska matematyka): wynik 90,7, lepszy zarówno od Lamy 3.1 (77,3), jak i GPT-4o (84,5).
Te wyniki podkreślają nie tylko jego siłę w rozumowaniu matematycznym opartym na języku angielskim, ale także w zadaniach wymagających rozwiązywania problemów numerycznych specyficznych dla języka.
Powiązane: DeepSeek AI Open Sources Seria modeli języka wizyjnego VL2
Programowanie i kodowanie
DeepSeek V3 wykazał się niezwykłą biegłość w kodowaniu i testach porównawczych rozwiązywania problemów. Na Codeforces, konkurencyjnej platformie programistycznej, model osiągnął ranking na poziomie 51,6 percentyla, co odzwierciedla jego zdolność do obsługi złożonych zadań algorytmicznych. Ta wydajność znacznie przewyższa rywali z oprogramowaniem open source, takich jak Llama 3.1, który uzyskał zaledwie 25,3, a nawet rzuca wyzwanie Claude 3.5 Sonnet, który zarejestrował niższy percentyl. Sukces modelu został dodatkowo potwierdzony jego wysokimi wynikami w testach porównawczych dotyczących kodowania:
HumanEval-Mul: Uzyskał wynik 82,6, przewyższając Qwen 2,5 (77,3) i dorównując GPT-4o (80,5). LiveCodeBench (Pass@1): wynik 37,6, przed Lamą 3,1 (30,1) i Claudem 3,5 Sonnetem (32,8). CRUXEval-I: wynik 67,3, znacznie lepszy od Qwen 2,5 (59,1) i Lamy 3,1 (58,5).
Te wyniki podkreślają przydatność modelu do zastosowań w tworzeniu oprogramowania i rzeczywistych środowiskach kodowania, gdzie najważniejsze jest skuteczne rozwiązywanie problemów i generowanie kodu.
Zadania wielojęzyczne i inne niż angielski
strong>
DeepSeek V3 wyróżnia się także w wielojęzycznych testach porównawczych, pokazując swoją zdolność do przetwarzania i rozumienia szerokiej gamy języków. W teścieCMMLU (ang. Chinese Multilingual Language Understanding) model uzyskał wyjątkowy wynik 88,8, przewyższając Qwen 2,5 (89,5) i dominując Lama 3,1, która pozostała w tyle na poziomie 73,7. Podobnie w C-Eval, chińskim teście porównawczym, DeepSeek V3 uzyskał 90,1, znacznie wyprzedzając Llamę 3,1 (72,5).
W zadaniach wielojęzycznych w języku innym niż angielski:
Wartości porównawcze specyficzne dla języka angielskiego
Chociaż DeepSeek V3 przoduje w matematyce, kodowania i wydajności w wielu językach, jego wyniki w niektórych testach porównawczych specyficznych dla języka angielskiego odzwierciedlają pole do poprawy. Na przykład w teście porównawczym SimpleQA, który ocenia zdolność modelu do odpowiadania na proste pytania merytoryczne w języku angielskim, DeepSeek V3 uzyskał 24,9 , pozostając w tyle za GPT-4o, który osiągnął 38,2. Podobnie w FRAMES, benchmarku pozwalającym zrozumieć złożone struktury narracyjne, GPT-4o uzyskał 80,5 w porównaniu do 73,3 DeepSeek.
Pomimo tych luk wydajność modelu pozostaje bardzo konkurencyjna, szczególnie biorąc pod uwagę jego charakter open source i opłacalność. Nieznaczne słabsze wyniki w zadaniach specyficznych dla języka angielskiego są równoważone przez jego dominację w matematycznych i wielojęzycznych testach porównawczych, czyli obszarach, w których konsekwentnie rzuca wyzwanie, a często przewyższa rywali o zamkniętym kodzie źródłowym.
Wyniki testów porównawczych DeepSeek V3 nie tylko pokazują jego zaawansowanie techniczne, ale pozycjonuje go również jako wszechstronny model o wysokiej wydajności do szerokiego zakresu zadań. Jego wyższość w matematyce, kodowaniu i wielojęzycznych testach porównawczych podkreśla jego mocne strony, a konkurencyjne wyniki w zadaniach w języku angielskim pokazują, że może konkurować z liderami branży, takimi jak GPT-4o i Claude 3.5 Sonnet.
Udostępniając te wyniki za ułamek kosztów związanych z zastrzeżonymi systemami, DeepSeek V3 ilustruje potencjał sztucznej inteligencji o otwartym kodzie źródłowym do konkurowania – a w niektórych przypadkach przewyższania – alternatywnych rozwiązań o zamkniętym kodzie źródłowym.
Powiązane: Apple planuje wdrożenie sztucznej inteligencji w Chinach za pośrednictwem Tencent i ByteDance
Opłacalne szkolenie na dużą skalę
Jeden Jednym z wyjątkowych osiągnięć DeepSeek V3 jest ekonomiczny proces szkoleniowy. Model został wytrenowany na zestawie danych składającym się z 14,8 biliona tokenów przy użyciu procesorów graficznych Nvidia H800, a całkowity czas szkolenia wyniósł 2,788 miliona godzin GPU. Całkowity koszt wyniósł 5,576 miliona dolarów, co stanowi ułamek szacowanych 500 milionów dolarów potrzebnych do wyszkolenia Meta Llama 3.1.
Procesor graficzny NVIDIA H800 to zmodyfikowana wersja procesora graficznego H100 zaprojektowana na rynek chiński w celu spełnienia wymagań eksportowych regulamin. Obydwa procesory graficzne oparte są na architekturze Hopper firmy NVIDIA i są wykorzystywane głównie w aplikacjach AI i obliczeniach o wysokiej wydajności. Szybkość przesyłania danych między chipami w H800 została zmniejszona o około połowę w porównaniu z H100
W procesie szkoleniowym wykorzystano zaawansowane metodologie, w tym szkolenie o mieszanej precyzji w ramach 8PR. Takie podejście zmniejsza zużycie pamięci poprzez kodowanie danych w 8-bitowym formacie zmiennoprzecinkowym bez utraty dokładności. Dodatkowo algorytm DualPipe zoptymalizowany jest pod kątem równoległości potoków, zapewniając płynną koordynację pomiędzy klastrami GPU.
DeepSeek twierdzi, że wstępne szkolenie DeepSeek-V3 wymagało jedynie 180 000 godzin procesora graficznego H800 na bilion tokenów przy użyciu klastra 2048 procesorów graficznych.
Dostępność i wdrożenie
DeepSeek udostępnił V3 na licencji MIT, zapewniając programistom dostęp do modelu zarówno do celów badawczych, jak i komercyjnych aplikacje. Przedsiębiorstwa mogą zintegrować model za pośrednictwem platformy lub interfejsu API DeepSeek Chat, którego cena jest konkurencyjna – 0,27 USD za milion tokenów wejściowych i 1,10 USD za milion tokenów wyjściowych.
Wszechstronność modelu rozciąga się na jego kompatybilność z różnymi platformami sprzętowymi, w tym Procesory graficzne AMD i jednostki NPU Huawei Ascend. Zapewnia to szeroką dostępność dla badaczy i organizacji o zróżnicowanych potrzebach infrastrukturalnych.
DeepSeek podkreślił swoje skupienie na niezawodności i wydajności, stwierdzając: „Aby zapewnić zgodność z SLO i wysoką przepustowość, stosujemy strategię dynamicznej redundancji dla ekspertów na etapie wstępnego napełniania, podczas którego eksperci z dużym obciążeniem są okresowo duplikowani i przestawiani dla optymalnej wydajności.”
Szersze implikacje dla ekosystemu AI
Wydanie DeepSeek V3 podkreśla szerszy trend w kierunku demokratyzacja sztucznej inteligencji, dostarczając model o wysokiej wydajności za ułamek kosztów związanych z zastrzeżonymi systemami, DeepSeek rzuca wyzwanie dominacji graczy o zamkniętym kodzie źródłowym, takich jak OpenAI i Anthropic. Dostępność takich zaawansowanych narzędzi umożliwia szersze eksperymenty i innowacje branżach.
Potok DeepSeek obejmuje wzorce weryfikacji i refleksji z modelu R1 do DeepSeek-V3, poprawiając możliwości wnioskowania, zachowując jednocześnie kontrolę nad stylem i długością wyników.
Sukces DeepSeek V3 rodzi pytania o przyszłą równowagę sił w branży sztucznej inteligencji. Ponieważ modele open source w dalszym ciągu wypełniają lukę w stosunku do systemów zastrzeżonych, zapewniają organizacjom konkurencyjne alternatywy, w których priorytetem jest dostępność i efektywność kosztowa.