Google DeepMind uruchomiło FACTS Grounding, nowy test porównawczy przeznaczony do testowania dużych modeli językowych (LLM) pod kątem ich zdolności do generowania zgodnych z faktami odpowiedzi opartych na dokumentach.
Benchmark, hostowany w Kaggle, ma na celu zmierzenie się z jednym z najpilniejszych wyzwań w sztuczna inteligencja: zapewnienie, że wyniki AI opierają się na dostarczanych im danych, zamiast polegać na wiedzy zewnętrznej lub wprowadzać halucynacje – wiarygodne, ale nieprawidłowe informacje.
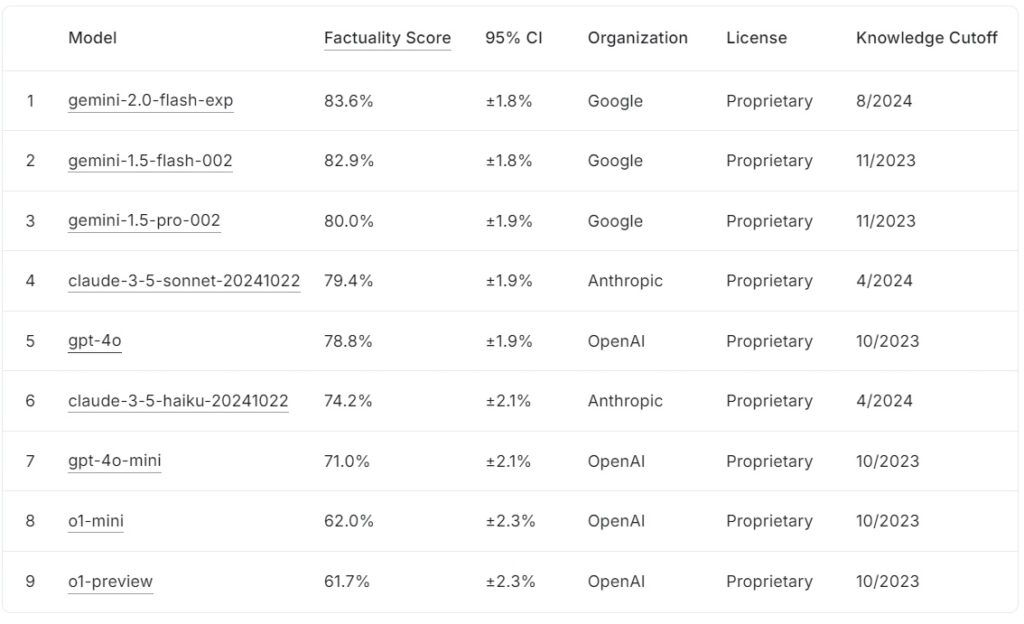
Obecny tabela liderów FACTS Grounding klasyfikuje duże modele językowe na podstawie ich wyników rzeczowości, przy czym Google gemini-2.0-flash-exp prowadzi na poziomie 83,6%, a tuż za nim znajduje się gemini-1.5-flash-002 na poziomie 82,9%, a gemini-1,5-pro-002 przy 80,0%.
Anthropic claude-3.5-sonnet-20241022 zajmuje czwarte miejsce z 79,4%, podczas gdy OpenAI gpt-4o osiąga 78,8%, co plasuje go na piątym miejscu. Niżej na liście znajduje się Anthropic claude-3.5-haiku-20241022 z wynikiem 74,2%, a za nim plasuje się gpt-4o-mini z 71,0%.
Mniejsze modele OpenAI, o1-mini i o1-preview, uzupełniają tabelę wyników z wynikami 62,0% i 61,7%.
 Źródło: Kaggle
Źródło: Kaggle
FAKTY Ugruntowanie wyróżnia się tym, że wymaga długich odpowiedzi, które syntetyzują szczegółowe dokumenty wejściowe, dzięki czemu jest to jeden z najbardziej rygorystycznych jak dotąd punktów odniesienia dla rzeczowości sztucznej inteligencji.
FAKTY Uziemienie stanowi kluczowy krok w rozwoju branży sztucznej inteligencji, szczególnie w zastosowaniach, w których kluczowe znaczenie ma zaufanie i dokładność. Oceniając LLM w dziedzinach takich jak medycyna, prawo, finanse, handel detaliczny i technologia, punkt odniesienia przygotowuje grunt pod poprawę niezawodności sztucznej inteligencji w rzeczywistych scenariuszach.
Według zespołu badawczego DeepMind „benchmark mierzy zdolność LLM do generowania odpowiedzi opartych wyłącznie na podanym kontekście… nawet jeśli kontekst jest sprzeczny z wiedzą przedszkoleniową.”
Zbiór danych dotyczący złożoności świata rzeczywistego
FAKTY Uziemienie składa się z 1719 przykładów wybranych przez ludzkich adnotatorów w celu zapewnienia trafności i różnorodności. Te przykłady są zaczerpnięte ze szczegółowych dokumentów obejmujących do 32 000 tokenów, co odpowiada około 20 000 słów.
Każde zadanie wymaga od LLM przeprowadzenia podsumowania, wygenerowania pytań i odpowiedzi lub przepisania treści, ze ścisłymi instrukcjami dotyczącymi odwoływania się wyłącznie do dostarczonych danych W benchmarku unika się zadań wymagających kreatywności, rozumowania matematycznego lub fachowej interpretacji, skupiając się zamiast tego na testowaniu zdolności modelu do syntezy i artykułowania złożonych informacji.
Aby zachować przejrzystość i zapobiegać nadmiernego dopasowania, DeepMind podzielił zbiór danych na dwa segmenty: 860 przykładów publicznych dostępnych do użytku zewnętrznego i 859 przykładów prywatnych zarezerwowanych do oceny rankingów.
Ta podwójna struktura zapewnia integralność testu porównawczego, jednocześnie zachęcając do współpracy twórców sztucznej inteligencji na całym świecie. „Rygorystycznie oceniamy nasze automatyczne osoby oceniające na podstawie dostępnych danych testowych, aby potwierdzić ich skuteczność w realizacji naszego zadania” – zauważa zespół badawczy, podkreślając staranny projekt leżący u podstaw FACTS Grounding.
Ocenianie dokładności wspólnie z innymi osobami Modele AI
W przeciwieństwie do konwencjonalnych testów porównawczych, FACTS Grounding wykorzystuje proces wzajemnej oceny obejmujący trzy zaawansowane LLM: Gemini 1.5 Pro, GPT-4o i Claude 3.5 Sonnet Modele te oceniają odpowiedzi, oceniając je na podstawie dwóch kluczowych kryteriów: kwalifikowalności i zgodności z faktami.
Odpowiedzi muszą najpierw przejść kontrolę kwalifikowalności, aby potwierdzić, że odpowiadają na pytanie użytkownika następnie oceniane pod kątem oparcia w materiale źródłowym, a wyniki sumowane dla trzech modeli w celu zminimalizowania błędu systematycznego.
Badacze DeepMind podkreślają znaczenie tej wielowarstwowej oceny, stwierdzając: „Metryki które skupiają się na ocenie faktów wygenerowanego tekstu… można obejść, ignorując intencje stojące za żądaniem użytkownika. Udzielając krótszych odpowiedzi, które nie zawierają wyczerpujących informacji… można uzyskać wysoki wynik za rzeczowość, nie udzielając jednocześnie pomocnej odpowiedzi.”
Korzystanie z wielu szablonów punktacji, w tym podejść opartych na poziomie zakresu i JSON , dodatkowo zapewnia zgodność z ludzką oceną i zdolność przystosowania się do różnorodnych zadań.
Radzenie sobie z wyzwaniem, jakim są halucynacje AI
Halucynacje AI są jedną z najważniejszych przeszkód w powszechnym przyjęcie LLM w kluczowych obszarach Błędy te, w przypadku których modele generują wyniki, które wydają się wiarygodne, ale są błędne w rzeczywistości, stwarzają poważne ryzyko w takich dziedzinach, jak opieka zdrowotna, analiza prawna i sprawozdawczość finansowa.
FAKTY Uziemienie bezpośrednio rozwiązuje ten problem poprzez egzekwowanie ścisłego przestrzegania dostarczonych danych wejściowych. Podejście to nie tylko ocenia zdolność modelu do unikania wprowadzania fałszu, ale także zapewnia, że dane wyjściowe pozostają zgodne z intencjami użytkownika.
W przeciwieństwie do wzorców takich jak benchmarki. Narzędzie SimpleQA OpenAI, które mierzy faktyczność podczas wyszukiwania danych szkoleniowych, FACTS Grounding sprawdza, jak dobrze modele syntetyzują nowe informacje.
Artykuł badawczy podkreśla to rozróżnienie: „Zapewnienie dokładności opartej na faktach podczas generowania odpowiedzi LLM jest wyzwaniem. Główne wyzwania związane z faktografią LLM to modelowanie (tj. architektura, szkolenie i wnioskowanie) oraz pomiary (tj. metodologia oceny, dane i metryki).”.
Wyzwania techniczne i projektowanie testów porównawczych
Złożoność długotrwałych danych wejściowych stwarza wyjątkowe wyzwania techniczne, szczególnie przy projektowaniu zautomatyzowanych metod oceny, które umożliwiają dokładną ocenę takich odpowiedzi.
FAKTY Zależność od uziemienia na wymagających obliczeniowo procesach walidacji odpowiedzi, stosując rygorystyczne kryteria w celu zapewnienia wiarygodności. Uwzględnienie modeli wielu sędziów łagodzi potencjalne błędy systematyczne i wzmacnia ogólne ramy oceny.
Zespół badawczy podkreśla znaczenie dyskwalifikacji niejasnych lub nieistotnych odpowiedzi. , zauważając, że „dyskwalifikacja niekwalifikujących się odpowiedzi prowadzi do redukcji… ponieważ odpowiedzi te są traktowane jako niedokładne”. To ścisłe egzekwowanie istotności gwarantuje, że modele nie będą nagradzane za obejście ducha zadania.
Zachęcanie do współpracy poprzez przejrzystość
Decyzja DeepMind o zorganizowaniu konferencji FACTS Grounding na Kaggle odzwierciedla jego zaangażowanie we wspieranie współpracy w branży sztucznej inteligencji. Udostępniając publiczny segment zbioru danych, projekt zachęca badaczy i programistów zajmujących się sztuczną inteligencją do oceny swoich modeli pod kątem solidnych standardów i przyczynienia się do udoskonalenia wskaźników faktograficznych.
To podejście jest zgodne z szerszymi celami przejrzystości i wspólnego postępu w sztucznej inteligencji, zapewniając, że ulepszenia w zakresie dokładności i podstaw nie ograniczają się do jednej organizacji.
Wyróżnienie się od innych Benchmarki
FAKTY Grounding odróżnia się od innych benchmarków tym, że skupia się na ugruntowaniu nowo wprowadzonych danych wejściowych, a nie na wcześniej wyszkolonej wiedzy.
Podczas gdy testy porównawcze, takie jak SimpleQA OpenAI, oceniają, jak dobrze model wyszukuje i wykorzystuje informacje ze swojego korpusu szkoleniowego, FACTS Grounding ocenia modele pod kątem ich zdolności do syntezy i artykułowania odpowiedzi wyłącznie na podstawie dostarczonych danych.
To rozróżnienie ma kluczowe znaczenie w stawianiu czoła wyzwaniom wynikającym z uprzedzeń dotyczących modeli lub nieodłącznych uprzedzeń. Izolując zadanie przetwarzania danych wejściowych z zewnątrz, FACTS Grounding zapewnia, że metryki wydajności odzwierciedlają zdolność modelu do działania w dynamicznych, rzeczywistych scenariuszach, a nie po prostu powtarzanie wcześniej wyuczonych informacji.
Jak wyjaśnia DeepMind w swoim artykule badawczym, test porównawczy ma na celu ocenę LLM pod kątem ich zdolności do zarządzania złożonymi, długimi zapytaniami w oparciu o fakty, symulując zadania istotne dla rzeczywistych aplikacji.
Alternatywne metody uziemiania LLM
Kilka metod oferuje podobne funkcje uziemienia do uziemienia FACTS, każda ma swoje mocne i słabe strony. Metody te mają na celu zwiększenie wyników LLM poprzez poprawę dostępu do dokładnych informacji lub udoskonalenie procesów szkolenia i dostosowania.
Generacja wspomagana wyszukiwaniem (RAG)
generowanie rozszerzone wyszukiwania (RAG) zwiększa dokładność wyników LLM poprzez dynamiczne pobieranie istotnych informacji z zewnętrznych baz wiedzy lub baz danych i włączenie ich do odpowiedzi modelu. Zamiast przekwalifikowywać cały LLM, RAG przechwytuje podpowiedzi użytkowników i wzbogaca je aktualnymi informacjami.
Zaawansowane wdrożenia RAG często wykorzystują wyszukiwanie oparte na encjach, gdzie dane powiązane z konkretnymi encjami są ujednolicane w celu zapewniają bardzo odpowiedni kontekst dla odpowiedzi LLM.
RAG zazwyczaj wykorzystuje techniki wyszukiwania semantycznego do wyszukiwania informacji. Dokumenty lub ich fragmenty są indeksowane na podstawie ich osadzania semantycznego, dzięki czemu system może dopasować zapytanie użytkownika do najbardziej odpowiednich kontekstowo wpisów. Takie podejście zapewnia, że LLM generują odpowiedzi oparte na najnowszych i najbardziej istotnych danych.
Skuteczność RAG zależy w dużym stopniu od jakości i organizacji bazy wiedzy, a także precyzji algorytmów wyszukiwania. Podczas gdy FACTS Grounding ocenia zdolność LLM do pozostania zakotwiczonym w dostarczonym dokumencie kontekstowym, RAG uzupełnia to, umożliwiając LLM dynamiczne poszerzanie swojej wiedzy, czerpiąc ze źródeł zewnętrznych w celu zwiększenia rzeczowości i przydatności.
Destylacja wiedzy
Destylacja wiedzy polega na przekazywaniu możliwości dużego, złożonego modelu (zwanego nauczycielem) do mniejszego modelu zadaniowego (ucznia). Metoda ta zwiększa wydajność, zachowując dużą część dokładności oryginalnego modelu. W destylacji wiedzy stosowane są dwa główne podejścia:
Destylacja wiedzy oparta na odpowiedziach: Koncentruje się na replikowaniu wyników modelu nauczyciela, upewniając się, że model ucznia daje podobne wyniki przy danych danych wejściowych.
Destylacja wiedzy oparta na funkcjach: wyodrębnia wewnętrzne reprezentacje i funkcje z modelu nauczyciela, umożliwiając modelowi ucznia replikację głębszych spostrzeżeń.
Poprzez udoskonalanie mniejszych modeli , destylacja wiedzy umożliwia wdrażanie LLM w środowiskach o ograniczonych zasobach bez znaczących strat w wydajności. W przeciwieństwie do FACTS Grounding, który ocenia wierność uziemienia, destylacja wiedzy koncentruje się bardziej na skalowaniu możliwości LLM i optymalizacji ich pod kątem konkretnych zadań.
Dostrajanie za pomocą ugruntowanych zbiorów danych
Dostrajanie polega na dostosowaniu wcześniej wyszkolonych LLM do konkretnych dziedzin lub zadań poprzez szkolenie ich na wybranych zbiorach danych, gdzie kluczowe znaczenie ma podstawa faktyczna. Na przykład zbiory danych obejmujące literaturę naukową lub zapisy historyczne można wykorzystać do poprawy zdolności modelu do generowania dokładnych wyników specyficznych dla danej dziedziny. Technika ta zwiększa wydajność LLM w przypadku specjalistycznych zastosowań, takich jak analiza dokumentów medycznych lub prawnych.
Jednak dostrajanie wymaga dużych zasobów i wiąże się z ryzykiem katastrofalnego w skutkach zapomnienia, w wyniku którego model traci wiedzę zdobytą podczas wstępnego szkolenia. FACTS Grounding koncentruje się na testowaniu faktów w izolowanych kontekstach, podczas gdy dostrajanie ma na celu poprawę podstawowej wydajności LLM w określonych obszarach.
Uczenie się przez wzmacnianie za pomocą informacji zwrotnej od ludzi (RLHF)
Uczenie się ze wzmocnieniem przy użyciu informacji zwrotnej od człowieka (RLHF) uwzględnia ludzkie preferencje w procesie szkoleniowym LLM. Dzięki iteracyjnemu szkoleniu modelu w celu dostosowania jego reakcji do informacji zwrotnych od ludzi, RLHF udoskonala jakość, faktyczność i użyteczność wyników. Osoby oceniające oceniają wyniki LLM, a wyniki te służą jako sygnały do optymalizacji modelu.
RLHF odniósł szczególny sukces w zwiększaniu zadowolenia użytkowników i zapewnianiu, że wygenerowane odpowiedzi są zgodne z ludzkimi oczekiwaniami. Podczas gdy FACTS Grounding ocenia oparcie faktów w konkretnych dokumentach, RLHF kładzie nacisk na dostosowanie wyników LLM do ludzkich wartości i preferencji.
Przestrzeganie instrukcji i uczenie się w kontekście
Przestrzeganie instrukcji i uczenie się w kontekście obejmują wykazanie się uziemieniem do LLM poprzez starannie opracowane przykłady w podpowiedziach użytkownika. Metody te opierają się na zdolności modelu do uogólniania na podstawie kilkukrotnej demonstracji. Chociaż takie podejście może zapewnić szybkie ulepszenia, może nie osiągnąć tego samego poziomu podstawowej jakości, co metody dostrajania lub oparte na wyszukiwaniu.
Narzędzia zewnętrzne i interfejsy API
LLM można zintegrować z zewnętrznymi narzędziami i interfejsami API, aby zapewnić dostęp do danych zewnętrznych w czasie rzeczywistym, znacznie zwiększając ich możliwości uziemienia. Przykłady obejmują:
Możliwość przeglądania: umożliwia LLM dostęp do informacji w Internecie i pobieranie ich w czasie rzeczywistym w celu udzielenia odpowiedzi na konkretne pytania lub aktualizacji wiedzy.
Wywołania API: umożliwiają LLM interakcję z ustrukturyzowanymi bazami danych lub usługami, wzbogacając odpowiedzi precyzyjnymi i aktualnymi informacjami.
Te narzędzia zwiększają użyteczność LLM, łącząc je z rzeczywistymi-wiedza o świecie źródeł, poprawiając ich zdolność do generowania dokładnych i uziemionych wyników. Podczas gdy FACTS Grounding ocenia wierność uziemienia wewnętrznego, narzędzia zewnętrzne zapewniają alternatywny sposób rozszerzania i weryfikowania faktów.
Uziemienie modelu typu open source Opcje
Dostępnych jest kilka implementacji typu open source dla alternatywnych metod uziemiania omówionych powyżej:
Konsekwencje dla zastosowań o dużej stawce
Znaczenie dokładnych i uzasadnionych reakcji sztucznej inteligencji staje się szczególnie widoczne w zastosowaniach o dużej stawce, takich jak diagnostyka medyczna, opinie prawne i analizy finansowe. W takich kontekstach nawet drobne niedokładności mogą prowadzić do znaczących konsekwencji, co sprawia, że niezawodność wyników generowanych przez sztuczną inteligencję jest wymogiem niepodlegającym negocjacjom.
FAKTY Nacisk, jaki w uziemieniu położony jest na fakty i trzymanie się materiału źródłowego, gwarantuje, że modele są testowane w warunkach ściśle odzwierciedlających wymagania świata rzeczywistego.
Na przykład w kontekście medycznym osoba LLM, której zadaniem jest podsumowując dokumentację pacjenta, należy unikać wprowadzania błędów, które mogłyby wprowadzić w błąd decyzje dotyczące leczenia. Podobnie w kontekście prawnym generowanie podsumowań czy analiz orzecznictwa wymaga precyzyjnego oparcia się na dostarczonych dokumentach.
FAKTY Grounding nie tylko ocenia modele pod kątem ich zdolności do spełnienia tych rygorystycznych wymagań, ale także ustanawia punkt odniesienia dla programistów, do którego powinni dążyć przy tworzeniu systemów odpowiednich do takich zastosowań.
Rozszerzanie zbiór danych FACTS i przyszłe kierunki
DeepMind umieścił FACTS Grounding jako „żywy punkt odniesienia”, który będzie ewoluował wraz z postępem w sztucznej inteligencji. Przyszłe aktualizacje prawdopodobnie rozszerzą zbiór danych do obejmować nowe domeny i typy zadań, zapewniając ich ciągłą przydatność w miarę wzrostu możliwości LLM.
Dodatkowo wprowadzenie bardziej zróżnicowanych szablonów oceny mogłoby jeszcze bardziej zwiększyć solidność procesu punktacji, eliminując przypadki skrajne i ograniczając pozostałe błędy.
Jak przyznaje zespół badawczy DeepMind, żaden test porównawczy nie jest w stanie w pełni ująć złożoności aplikacji w świecie rzeczywistym. Jednakże celem projektu jest podniesienie poziomu FACTS Grounding i zaangażowanie szerszej społeczności AI poprzeczka w zakresie rzeczowości i ugruntowania systemów sztucznej inteligencji.
Jak stwierdza zespół DeepMind: „Fakty i podstawy należą do kluczowych czynników, które będą kształtować przyszły sukces i użyteczność LLM oraz szerszych systemów sztucznej inteligencji, a naszym celem jest rozwój i udoskonalanie FACTS Grounding w miarę postępu w tej dziedzinie, stale podnosimy poprzeczkę.”