DeepSeek AI wypuściło DeepSeek-VL2, rodzinę modeli języka wizyjnego (VLM), które są teraz dostępne na licencjach typu open source. Seria wprowadza trzy warianty – Tiny, Small i standard VL2 – charakteryzujące się aktywowanymi parametrami o rozmiarach odpowiednio 1,0 miliarda, 2,8 miliarda i 4,5 miliarda.
Modele są dostępne w GitHub iPrzytulająca twarz. Obiecują rozwój kluczowych zastosowań sztucznej inteligencji, w tym wizualnego odpowiadania na pytania (VQA), optycznego rozpoznawania znaków (OCR) oraz analizy dokumentów i wykresów w wysokiej rozdzielczości.
Według oficjalnej dokumentacji GitHub „DeepSeek-VL2 wykazuje doskonałe możliwości w przypadku różnych zadań, w tym między innymi wizualnego odpowiadania na pytania, zrozumienia dokumentów/tabel/wykresów i uziemienia wizualnego.”
Moment wydania tej wersji stawia DeepSeek AI w bezpośredniej konkurencji z głównymi graczami, takimi jak OpenAI i Google, z których oba dominują w domenie sztucznej inteligencji opartej na wizji dzięki zastrzeżonym modele takie jak GPT-4V i Gemini-Exp
DeepSeek nacisk na współpracę typu open source w połączeniu z zaawansowanymi funkcjami technicznymi rodziny VL2 sprawia, że jest to bezpłatna opcja dla badaczy.
Dynamiczne kafelkowanie: zaawansowane przetwarzanie obrazu w wysokiej rozdzielczości
Jednym z najbardziej znaczących osiągnięć w DeepSeek-VL2 jest strategia dynamicznego kodowania obrazu metodą kafelkowania, która rewolucjonizuje sposób, w jaki modele przetwarzają dane wizualne o wysokiej rozdzielczości.
W przeciwieństwie do tradycyjnych W podejściu opartym na stałej rozdzielczości dynamiczne kafelkowanie dzieli obrazy na mniejsze, elastyczne kafelki, które dostosowują się do różnych współczynników proporcji. Metoda ta zapewnia szczegółową ekstrakcję cech przy zachowaniu wydajności obliczeniowej.
W swoim repozytorium GitHub firma DeepSeek opisuje to jako sposób „efektywnego przetwarzania obrazów o wysokiej rozdzielczości i różnych proporcjach, unikając skalowania obliczeniowego zwykle związanego ze wzrostem rozdzielczości obrazów”.
Dzięki tej możliwości DeepSeek-VL2 doskonale sprawdza się w zastosowaniach takich jak uziemienie wizualne, gdzie wysoka precyzja jest niezbędna do identyfikacji obiektów na złożonych obrazach, oraz gęste zadania OCR, które wymagają przetwarzania tekstu w szczegółowych dokumentach lub wykresach
Dzięki dynamicznemu dostosowywaniu się do różnych rozdzielczości obrazu i współczynników proporcji modele pokonują ograniczenia metod kodowania statycznego, dzięki czemu nadają się do zastosowań wymagających zarówno elastyczności, jak i dokładności.
Mieszanka-Eksperci i wielogłowicowi ukryci uwaga na wydajność
Wzrost wydajności DeepSeek-VL2 jest dodatkowo wspierany przez integrację Struktura Mixture-of-Experts (MoE) i mechanizm wielogłowicowej uwagi utajonej (MLA).
Architektura MoE selektywnie aktywuje określone podzbiory, czyli „ekspertów” w modelu, aby efektywniej wykonywać zadania. Konstrukcja ta zmniejsza narzut obliczeniowy, angażując tylko niezbędne parametry dla każdej operacji, co jest funkcją szczególnie przydatną w środowiskach o ograniczonych zasobach.
Mechanizm MLA uzupełnia strukturę MoE poprzez kompresję pamięci podręcznej klucz-wartość do postaci ukrytej wektory podczas wnioskowania. Ta optymalizacja minimalizuje zużycie pamięci i zwiększa prędkość przetwarzania bez utraty dokładności modelu.
Zgodnie z dokumentacją techniczną „Architektura MoE w połączeniu z MLA pozwala DeepSeek-VL2 osiągnąć konkurencyjną lub lepszą wydajność niż gęste modele z mniejszą liczbą aktywowanych parametrów.”
Trzyetapowy proces szkolenia
Rozwój DeepSeek-VL2 obejmował rygorystyczny, trzyetapowy proces szkolenia, którego celem było zoptymalizowanie multimodalnych możliwości modelu. Pierwszy etap skupiał się na nim dopasowanie obrazu do języka, w ramach którego modele zostały przeszkolone w zakresie integrowania cech wizualnych z informacjami tekstowymi
Uzyskano to przy użyciu zbiorów danych takich jak ShareGPT4V, które dostarczają sparowanych przykładów obrazu i tekstu do wstępnego dopasowania. wstępne szkolenie językowe, które obejmowało różnorodny zakres zbiorów danych, w tym dane WIT, WikiHow i wielojęzyczne dane OCR, w celu zwiększenia możliwości generalizacji modelu w wielu domenach.
Na koniec trzeci etap obejmował nadzorowane dostrajanie (SFT), podczas którego zestawy danych specyficzne dla zadania zostały wykorzystane do udoskonalenia wydajności modelu w takich obszarach, jak podstawy wizualne, zrozumienie graficznego interfejsu użytkownika (GUI) i gęste napisy.
Te etapy szkoleniowe pozwoliły DeepSeek-VL2 zbudować solidne podstawy do zrozumienia multimodalności, umożliwiając jednocześnie dostosowanie modeli do specjalistycznych zadań. Włączenie wielojęzycznych zbiorów danych jeszcze bardziej zwiększyło zastosowanie modeli w globalnych badaniach i warunkach przemysłowych.
Powiązane: Chiński model DeepSeek R1-Lite w wersji zapoznawczej jest liderem OpenAI w zakresie automatycznego wnioskowania
Wyniki testów porównawczych
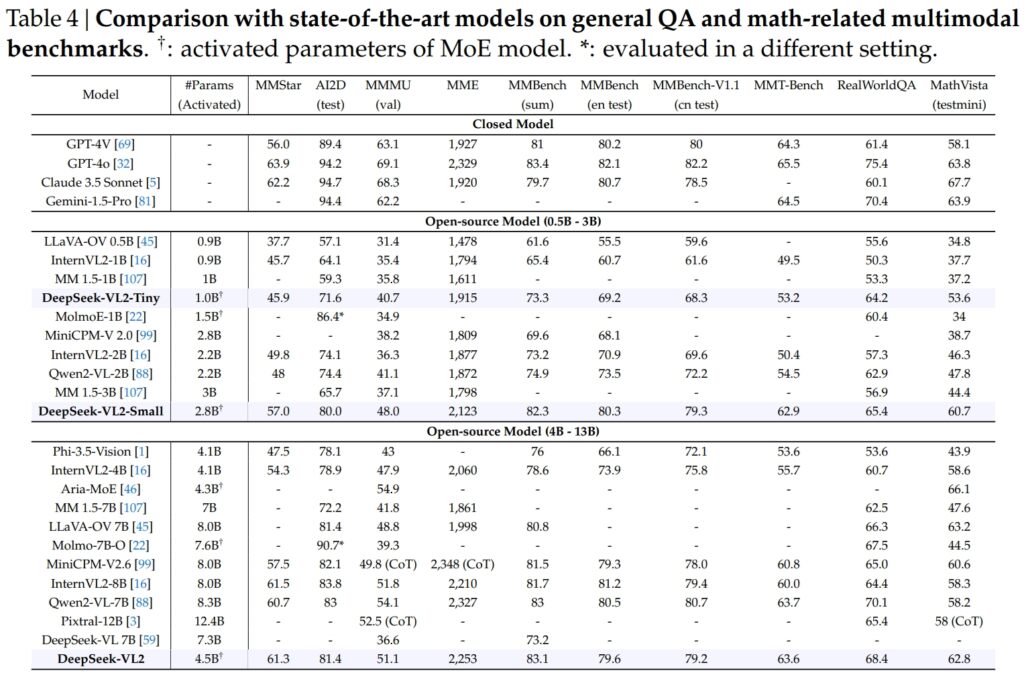
Modele DeepSeek-VL2, w tym warianty Tiny, Small i standardowe, wyróżniały się pod względem krytyczne punkty odniesienia dla ogólnych zadań związanych z odpowiadaniem na pytania (QA) i zadań multimodalnych związanych z matematyką.
DeepSeek-VL2-Small, dzięki 2,8 miliardom aktywowanych parametrów, uzyskał wynik MMStar na poziomie 57,0 i uzyskał lepsze wyniki niż modele o podobnej wielkości, takie jak InternVL2-2B (49,8) i Qwen2-VL-2B (48,0). Ściśle rywalizował także ze znacznie większymi modelami, takimi jak 4.1B InternVL2-4B (54,3) i 8.3B Qwen2-VL-7B (60,7), demonstrując swoją konkurencyjną wydajność.
W teście AI2D pod kątem obrazu rozumując, DeepSeek-VL2-Small uzyskał wynik 80,0, przewyższając InternVL2-2B (74,1) i MM 1,5-3B (nie podano). Nawet w porównaniu z większymi konkurentami, takimi jak InternVL2-4B (78,9) i MiniCPM-V2.6 (82,1), DeepSeek-VL2 wykazał dobre wyniki przy mniejszej liczbie aktywowanych parametrów.
 Źródło: DeepSeek
Źródło: DeepSeek
Okręt flagowy Model DeepSeek-VL2 (4,5 miliarda aktywowanych parametrów) zapewnił wyjątkowe wyniki, zdobywając 61,3 punktów w MMStar i 81,4 na AI2D. Przewyższył konkurentów, takich jak Molmo-7B-O (parametry aktywowane 7,6B, 39,3) i MiniCPM-V2.6 (8,0B, 57,5), jeszcze bardziej potwierdzając swoją wyższość techniczną.
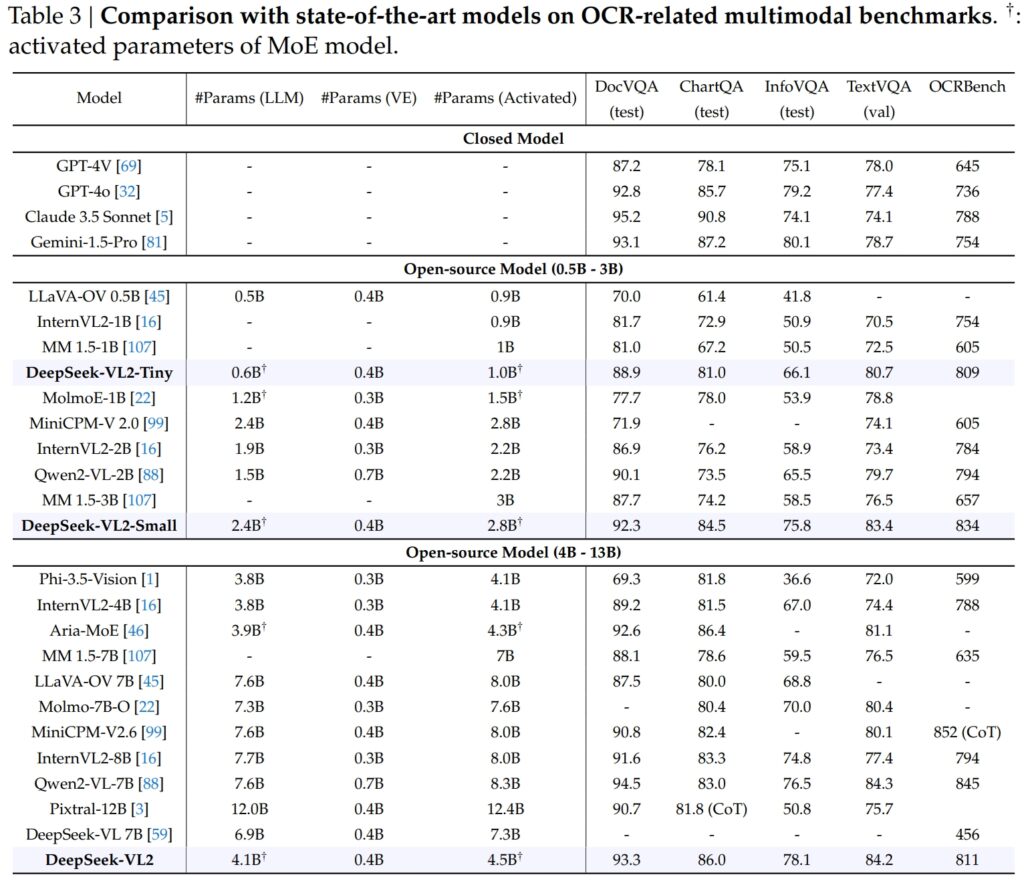
Doskonałość w OCR-Powiązane testy porównawcze
Możliwości DeepSeek-VL2 obejmują przede wszystkim funkcje OCR (optyczne rozpoznawanie znaków) zadań, co stanowi kluczowy obszar rozumienia dokumentów i ekstrakcji tekstu w sztucznej inteligencji. W teście DocVQA DeepSeek-VL2-Small osiągnął imponującą dokładność 92,3%, przewyższając wszystkie inne modele open source o podobnej skali, w tym InternVL2-4B (89,2%) i MiniCPM-V2.6 (90,8%). Jego dokładność była tuż za modelami zamkniętymi, takimi jak GPT-4o (92,8) i Claude 3,5 Sonnet (95,2).
Model DeepSeek-VL2 również zwyciężył w teście ChartQA z wynikiem 86,0, przewyższając InternVL2-4B (81,5) i MiniCPM-V2.6 (82,4). Wynik ten odzwierciedla zaawansowaną zdolność DeepSeek-VL2 do przetwarzania wykresów i wydobywania spostrzeżeń ze złożonych danych wizualnych.
 Źródło: DeepSeek
Źródło: DeepSeek
W OCRBench, wysoce konkurencyjny metryka precyzyjnego rozpoznawania tekstu, DeepSeek-VL2 osiągnął 811, deklasując 7.6B Qwen2-VL-7B (845) i MiniCPM-V2.6 (852 z CoT) i podkreślając jego siłę w gęstych zadaniach OCR.
Porównanie z wiodącymi modelami wizualno-językowymi
W przypadku umieszczenia obok liderów branży, takich jak modele GPT-4V firmy OpenAI i modele Gemini-1.5-Pro i DeepSeek-VL2 firmy Google oferują przekonującą równowagę wydajności i efektywności. Na przykład GPT-4V uzyskał 87,2 w DocVQA, co tylko nieznacznie przewyższa DeepSeek-VL2 (93,3), mimo że ten ostatni działa w środowisku open source z mniejszą liczbą aktywowanych parametrów.
W TextVQA, DeepSeek-VL2-Small osiągnął 83,4, znacznie przewyższając podobne modele typu open source, takie jak InternVL2-2B (73,4) i MiniCPM-V2.0 (74.1). Nawet znacznie większy MiniCPM-V2.6 (8.0B) osiągnął jedynie 80,4, co dodatkowo podkreśla skalowalność i wydajność architektury DeepSeek-VL2.
W przypadku ChartQA wynik DeepSeek-VL2 wynoszący 86,0 przewyższał wynik Pixtral-12B (81,8) i InternVL2-8B (83,3), demonstrując swoją zdolność do doskonałości w specjalistycznych zadaniach wymagających precyzyjnego zrozumienia wizualno-tekstowego.
Powiązane: Mistral AI debiutuje Pixtral 12B do przetwarzania tekstu i obrazu
Rozszerzanie zastosowań: Od Ugruntowane rozmowy w wizualnym opowiadaniu historii
Jedną godną uwagi cechą modeli DeepSeek-VL2 jest ich zdolność do prowadzenia ugruntowanych rozmów, podczas których model może identyfikować obiekty na obrazach i włączyć je do dyskusji kontekstowych.
Na przykład za pomocą wyspecjalizowanego tokena model może udostępniać szczegółowe informacje dotyczące obiektu, takie jak lokalizacja i opis, w celu odpowiadania na zapytania dotyczące obrazów. Otwiera to możliwości zastosowań w robotyce, rzeczywistości rozszerzonej i asystentach cyfrowych, gdzie wymagane jest precyzyjne rozumowanie wizualne.
Kolejnym obszarem zastosowań jest wizualne opowiadanie historii. DeepSeek-VL2 może generować spójne narracje w oparciu o sekwencję obrazów, łącząc zaawansowane możliwości rozpoznawania wizualnego i językowego.
Jest to szczególnie cenne w takich dziedzinach, jak edukacja, media i rozrywka, gdzie priorytetem jest dynamiczne tworzenie treści. Modele wykorzystują silne zrozumienie multimodalne, aby tworzyć szczegółowe i odpowiednie kontekstowo historie, płynnie integrując elementy wizualne, takie jak punkty orientacyjne i tekst, z narracją.
Zdolność modeli w zakresie podstaw wizualnych jest równie duża. W testach obejmujących złożone obrazy DeepSeek-VL2 wykazał zdolność do dokładnego lokalizowania i opisywania obiektów w oparciu o podpowiedzi opisowe.
Na przykład, gdy zostaniesz poproszony o zidentyfikowanie „samochodu zaparkowanego po lewej stronie ulicy”, model może wskazać dokładny obiekt na obrazie i wygenerować współrzędne ramki ograniczającej, aby zilustrować jego reakcję. Funkcje te sprawiają, że ma duże zastosowanie w systemach autonomicznych i monitoringu, gdzie szczegółowa analiza wizualna ma kluczowe znaczenie.
Dostępność i skalowalność typu open source
Decyzja DeepSeek AI o wydaniu DeepSeek-VL2 jako oprogramowanie typu open source ostro kontrastuje z zastrzeżonym charakterem konkurentów, takich jak GPT-4V OpenAI i Gemini-Exp firmy Google, które są zamkniętymi systemami przeznaczonymi do ograniczonego dostępu publicznego.
Zgodnie z dokumentacją techniczną, „Udostępniając publicznie nasze wstępnie wytrenowane modele i kod, naszym celem jest przyspieszenie postępu w modelowaniu języka wizyjnego i promowanie wspólnych innowacji w społeczności badawczej”.
Skalowalność DeepSeek-VL2 jeszcze bardziej zwiększa ich atrakcyjność. Modele są zoptymalizowane pod kątem wdrażania w szerokiej gamie konfiguracji sprzętowych, od pojedynczych procesorów graficznych z 10 GB pamięci po konfiguracje z wieloma procesorami graficznymi, które są w stanie obsłużyć obciążenia na dużą skalę.
Ta elastyczność gwarantuje, że DeepSeek-VL2 może być używany przez organizacje każdej wielkości, od start-upów po duże przedsiębiorstwa, bez potrzeby posiadania specjalistycznej infrastruktury.
Innowacje w zakresie danych i Szkolenie
Głównym czynnikiem sukcesu DeepSeek-VL2 są jego obszerne i różnorodne dane szkoleniowe. Faza wstępnego szkolenia obejmowała zbiory danych, takie jak WIT, WikiHow i OBELICS, które zapewniły mieszankę przeplatanych par obraz-tekst na potrzeby uogólnienia.
Dodatkowe dane dotyczące konkretnych zadań, takich jak OCR i wizualne odpowiadanie na pytania, pochodziły ze źródeł takich jak LaTeX OCR i PubTabNet, dzięki czemu modele mogły z dużą dokładnością obsługiwać zarówno zadania ogólne, jak i specjalistyczne.
Włączenie wielojęzycznych zbiorów danych odzwierciedla także cel DeepSeek AI, jakim jest globalne zastosowanie. Zbiory danych w języku chińskim, takie jak Wanjuan, zintegrowano ze zbiorami danych w języku angielskim, aby zapewnić skuteczne działanie modeli w środowiskach wielojęzycznych.
To podejście zwiększa użyteczność DeepSeek-VL2 w regionach, w których dominują dane w języku innym niż angielski, znacznie poszerzając potencjalną bazę użytkowników.
Faza nadzorowanego dostrajania jeszcze bardziej udoskonaliła modele możliwości, koncentrując się na konkretnych zadaniach, takich jak zrozumienie GUI i analiza wykresów. Łącząc wewnętrzne zbiory danych z wysokiej jakości zasobami typu open source, DeepSeek-VL2 osiągnął najnowocześniejszą wydajność w kilku testach porównawczych, potwierdzając skuteczność swojej metodologii szkoleniowej.
Staranny dobór DeepSeek AI danych i innowacyjny proces szkoleniowy pozwoliły modelom VL2 wyróżnić się w szerokim zakresie zadań, zachowując jednocześnie wydajność i skalowalność. Czynniki te czynią je cennym uzupełnieniem dziedziny multimodalnej sztucznej inteligencji.
Zdolność modeli do obsługi złożonych zadań przetwarzania obrazu, takich jak uziemienie wizualne i gęsty OCR, czyni je idealnymi dla branż takich jak logistyka i bezpieczeństwo. W logistyce mogą zautomatyzować śledzenie zapasów, analizując obrazy zapasów magazynowych, identyfikując pozycje i integrując ustalenia z systemami zarządzania zapasami.
W obszarze bezpieczeństwa DeepSeek-VL2 może pomóc w nadzorze, identyfikując obiekty lub osoby w czasie rzeczywistym na podstawie zapytań opisowych i dostarczając operatorom szczegółowe informacje kontekstowe.
DeepSeek-Ugruntowane możliwości konwersacji VL2 oferują także możliwości w robotyce i rzeczywistości rozszerzonej. Na przykład robot wyposażony w ten model mógłby wizualnie interpretować swoje otoczenie, odpowiadać na zapytania ludzi dotyczące konkretnych obiektów i wykonywać czynności w oparciu o zrozumienie bodźców wizualnych.
Podobnie urządzenia rzeczywistości rozszerzonej mogą wykorzystywać wizualne podstawy modelu i funkcje opowiadania historii, aby zapewnić interaktywne, wciągające doświadczenia, takie jak wycieczki z przewodnikiem lub nakładki kontekstowe w środowiskach czasu rzeczywistego.
Wyzwania i perspektywy na przyszłość
Pomimo swoich licznych mocnych stron, DeepSeek-VL2 stoi przed kilkoma wyzwaniami. Jednym z kluczowych ograniczeń jest rozmiar okna kontekstowego, które obecnie ogranicza liczbę obrazów, które można przetworzyć w ramach pojedynczej interakcji.
Rozszerzenie tego okna kontekstowego w przyszłych iteracjach umożliwiłoby bogatsze interakcje obejmujące wiele obrazów i zwiększyło użyteczność modelu w zadaniach wymagających szerszego zrozumienia kontekstu.
Kolejnym wyzwaniem jest radzenie sobie z nie—domeny lub dane wizualne o niskiej jakości, takie jak rozmyte obrazy lub obiekty, których nie ma w danych szkoleniowych. Chociaż DeepSeek-VL2 wykazał niezwykłe możliwości uogólniania, poprawa odporności na takie dane wejściowe jeszcze bardziej zwiększy jego zastosowanie w rzeczywistych scenariuszach.
Patrząc w przyszłość, DeepSeek AI planuje wzmocnić możliwości wnioskowania swoich modeli, umożliwiając im obsługę coraz bardziej złożonych zadań multimodalnych. Integrując ulepszone procesy szkoleniowe i rozszerzając zbiory danych, aby uwzględnić bardziej zróżnicowane scenariusze, przyszłe wersje DeepSeek-VL2 mogą ustanowić nowe standardy wydajności sztucznej inteligencji opartej na języku wizyjnym.

