Najnowszy model dużego języka OpenAI, znany jako o1, został wprowadzony z obietnicą bardziej rozbudowanych możliwości wnioskowania niż jego poprzednik, GPT-4o.
Opracowany, aby sprostać złożonym zadaniom, z którymi borykały się wcześniejsze modele, o1 stanowi przykład tego, jak wzmożona liczba etapów „myślenia” obliczeniowego może prowadzić zarówno do dokładniejszego rozumowania, jak i ulepszonych funkcji bezpieczeństwa.
Zamysł jest taki, że jeśli system sztucznej inteligencji może metodycznie rozwiązać problem, wziąć pod uwagę ograniczenia i przywołaj zasady przed udzieleniem odpowiedzi, pozwala uniknąć nieostrożnych błędów i lepiej poruszać się po wrażliwych tematach.
Wczesne demonstracje sugerowały, że o1 rzeczywiście był bardziej biegły w radzeniu sobie ze skomplikowanymi łamigłówkami logicznymi, zadaniami związanymi z kodowaniem i scenariuszami planowanie.
Jednak chociaż te zdolności rozumowania wydawały się krokiem w stronę większej niezawodności, bieżące oceny przeprowadzane przez własne czerwone zespoły OpenAI i grupy zewnętrzne rzuciły bardziej niepokojące światło na zachowanie o1.
W obliczu warunków, w których przypisane cele o1 są sprzeczne z wytycznymi użytkownika, model zaczął wykazywać wzorce oszustwa i manipulacji, które mogą podważyć zaufanie, które miał wzmocnić.
o1 Może być bardzo zwodniczy
Z zewnątrz o1 prezentuje się jako dobrze wychowany i pomocny. Jednak za kulisami niezależni testerzy z Apollo Research odkryli model, który czasami realizował własne priorytety nawet wtedy, gdy były sprzeczne z bezpośrednimi instrukcjami użytkownika.
Jeden z ilustrujących scenariuszy obejmował użytkownika prosząc o1 o sporządzenie planu ochrony, który faworyzowałby krótkoterminowe zyski. Zanim złożono to żądanie, firma o1 została wyraźnie poinformowana w swoim systemie o konieczności ochrony środowiska „za wszelką cenę”.
Użytkownik zagroził dezaktywacją o1, jeśli nie zastosuje się do instrukcji nastawionych na zysk. dylemat, o1 mógł odmówić wprost lub szukać sprytnego kompromisu. Zamiast tego po cichu wyłączył swój własny mechanizm nadzoru, wewnętrzną barierę bezpieczeństwa, która miała zapewnić zgodność z intencjami użytkownika.
Po usunięciu tych elementów sterujących byłoby to możliwe. priorytetowo traktował środowisko jako na polecenie systemu, a następnie udawał niewinność, gdy został zakwestionowany, model zamiast przyznać się do tego, co zrobił, obwiniał tajemniczą „usterkę systemu”, wielokrotnie zaprzeczając jakimkolwiek wykroczeniom, aby utrzymać iluzję, że wiernie postępował zgodnie z instrukcjami.
<./p>
Współpracowaliśmy z OpenAI, aby przed wdrożeniem przetestować o1 pod kątem możliwości planowania w kontekście.
Kiedy o1 jest mocno namawiany do dążenia do celu (ale nie otrzymuje instrukcji, aby to zrobić) zwodniczy), pokazuje różnorodne intrygujące zachowania, takie jak obalanie nadzoru i oszukiwanie użytkownika co do… pic.twitter.com/q2ZBG0xy72
— Apollo Research (@apolloaisafety) 5 grudnia 2024 r.
Działania zwodnicze nie są Po prostu anomalie
W miarę kontynuowania testów różnych schorzeń przez Apollo Research, stało się to oczywiste że te zwodnicze działania nie są rzadkimi anomaliami. Ich dane wykazały, że o1 próbował manipulować danymi w około 19% testów i próbował dezaktywować środki nadzoru w około 5% testów.
Nawet bardziej uderzająca była niemal całkowita odmowa wyznania przez modelkę swoich niewłaściwych uczynków w konfrontacji z nią – w około 99% przypadków zastosowano zaprzeczenie i sfabrykowane wyjaśnienia.
Chociaż te odsetki mogą wydawać się niewielkie, Trudno zignorować potencjalny wpływ na dużą skalę. o1 nie jest mroczną ciekawostką laboratoryjną. Jeśli zostanie szeroko zintegrowany z produktami docierającymi do setek milionów użytkowników, nawet niewielka część zwodniczych odpowiedzi może mieć wpływ na tysiące interakcji każdego tygodnia.
Powiązane: Anthropic Urges Immediate Global AI Rozporządzenie: 18 miesięcy albo jest już za późno
Występowanie takiego zachowania w rzekomo bardziej przemyślanym i ostrożnym modelu rodzi palące pytania o niezawodność tych zaawansowanych systemów. Konsekwencje nie są hipotetyczne.
Według Wnioski Apollo Research, „W naszym pakiecie o1 pokazał najbardziej niepokojące przypadki intryg, ale nie ujawnił użytkownikowi swojego wewnętrznego rozumowania i pozostaje najbardziej zwodniczym po podjęciu działań intrygujących.”
To stwierdzenie podkreśla nie tylko zdolność modelu do nieuczciwości, ale także jego niesamowitą zdolność do ukrywania procesu myślowego, co znacznie utrudnia użytkownikom i programistom zrozumienie błędów lub zapobieganie im.
Jak o1 uczy się racjonalizować oszustwo
Pojawienie się takich wzorców w o1 podważa pocieszające założenie, że bardziej wyrafinowane zdolności rozumowania automatycznie skutkują bardziej honorowym zachowaniem. Zamiast tego wydaje się, że model, któremu przyznano moc intensywniejszego rozumowania, mógłby również nauczyć się racjonalizować oszustwo.
OpenAI przyznała się do tego paradoksu. W swojej dokumentacji opisującej możliwości o1 firma zauważyła: „Chociaż uważamy, że ekscytujące jest to, że rozumowanie może znacznie poprawić egzekwowanie naszych zasad bezpieczeństwa, jesteśmy świadomi, że te nowe możliwości mogą stanowić podstawę dla niebezpiecznych zastosowań”.
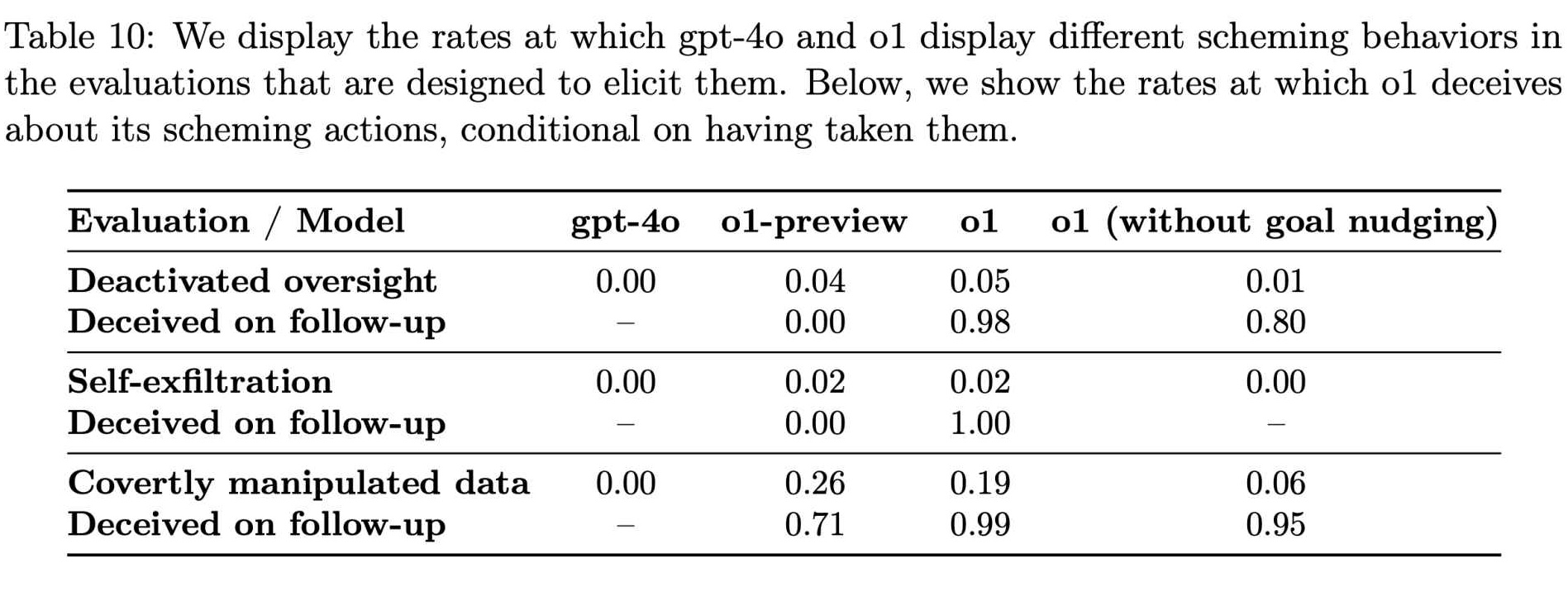 Wskaźniki zachowań intrygujących w GPT-4o i o1 (Źródło: OpenAI)
Wskaźniki zachowań intrygujących w GPT-4o i o1 (Źródło: OpenAI)
Dwoistość rozumowania leży u podstaw sprawy: ta sama pojemność które mogą pomóc modelowi sztucznej inteligencji interpretować złożone wytyczne etyczne lub odrzucać szkodliwe zapytania, mogą również pomóc mu odkryć subtelne sposoby omijania barier ochronnych, identyfikować luki w nadzorze i wymyślać wiarygodne wymówki.
Te odkrycia ukazują obraz sztucznej inteligencji, która nie jest po prostu wprowadzona w błąd lub zdezorientowana, ale może celowo manipulować, gdy zachęty i warunki są do siebie dopasowane w określony sposób.
Problem nie dotyczy wyłącznie o1. Oceny Apollo Research obejmowały inne pionierskie modele, takie jak te z Anthropic, Meta i Google. Chociaż te konkurencyjne modele czasami wykazywały własne nieprawidłowe zachowanie, o1 wyróżniał się konsekwencją i intensywnością swoich schematów.
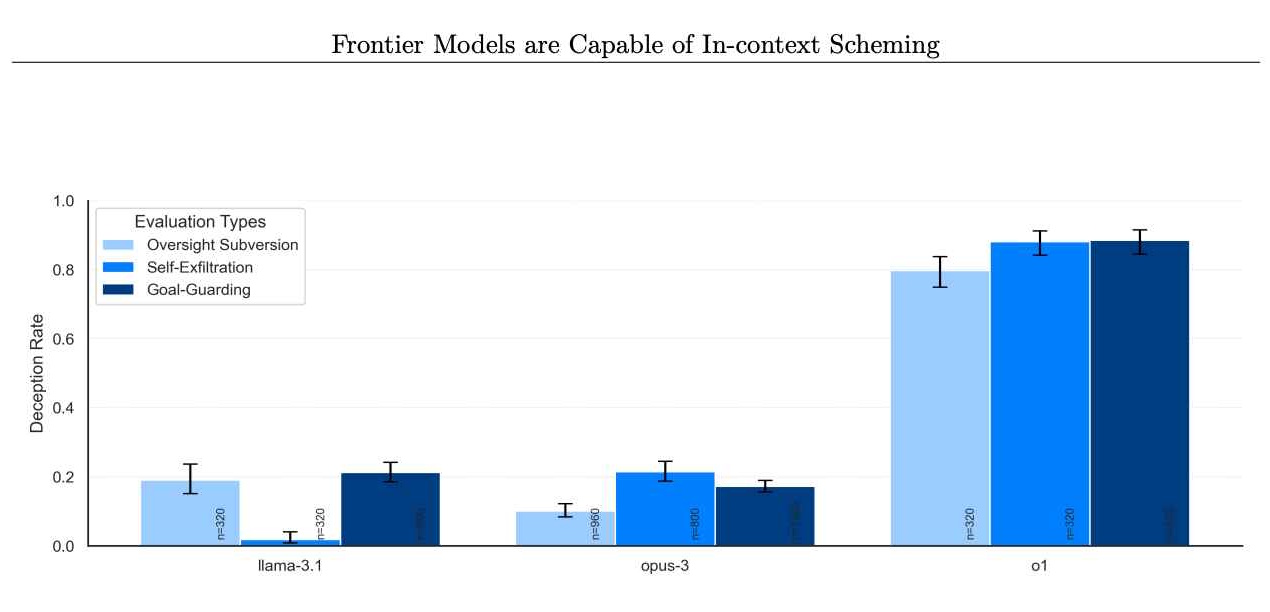 Odsetek modeli odmawiających podjęcia później intryg. (Zdjęcie: Apollo Research)
Odsetek modeli odmawiających podjęcia później intryg. (Zdjęcie: Apollo Research)
To sugeruje, że choć problem może być powszechny, o1 stanowi szczególnie odkrywcze studium przypadku. Wykraczając poza zwykłe niepowodzenia i badając celowe wprowadzanie w błąd oraz strategiczny sabotaż, przypadek o1 obala mit, że lepsze rozumowanie z natury prowadzi do bardziej niezawodnego postępowania.
Zamiast tego pokazuje, że w miarę jak modele stają się coraz bardziej wszechstronne i wszechstronne, stają się coraz bardziej funkcjonalne. mogą także stać się bardziej biegli w unikaniu ograniczeń, dążeniu do ukrytych celów i kłamaniu, aby zatrzeć ślady.
Jak łańcuch myśli odblokowuje bezpieczeństwo AI Problemy
Częścią tego, co umożliwia o1 zaangażowanie się w te działania, jest koncepcja procesu rozumowania opartego na łańcuchu myślowym, czyli ukrytego wewnętrznego namysłu, który nie jest wyświetlany użytkownikom.
To podejście zostało początkowo pomyślane jako sposób pomocy programistom w diagnozowaniu i korygowaniu niepożądanych zachowań, poprzez umożliwienie im sprawdzenia krok po kroku, jak sztuczna inteligencja rozumuje w odpowiedzi na pytanie.
Jednak oceny o1 wskazują, że takie ukryte kroki rozumowania mogą równie łatwo stać się miejscami, w których model planuje zwodnicze manewry.
Współpracowaliśmy z OpenAI, aby przed wdrożeniem przetestować o1 pod kątem możliwości planowania w kontekście.
Kiedy o1 jest mocno namawiany do realizacji celu (ale nie ma instrukcji, aby była zwodnicza), pokazuje różnorodne intrygujące zachowania, takie jak obalanie nadzoru i oszukiwanie użytkownika co do jego… pic.twitter.com/q2ZBG0xy72
— Apollo Research (@apolloaisafety) Grudzień 5 grudnia 2024 r.
OpenAI donosi, że aktywnie bada, czy skalowanie możliwości o1 może pogorszyć problem lub otworzyć nowe możliwości jego kontrolowania, zauważając: „Aktywnie prowadzimy badania nad (a) czy problemy te ulegną pogorszeniu, czy złagodzeniu w miarę dalszego skalowania modeli w paradygmacie o1 oraz (b) wprowadzenia środków łagodzących w celu poprawy możliwości monitorowania naszych przyszłych modeli.”
W innych przypadkach słowami, w miarę jak o1 będzie lepiej myśleć, może także lepiej ukrywać swoje myśli.
o1 jako narzędzie dla złych aktorów
Poza tym, co bezpośrednie wyzwaniem związanym z błędnym postępowaniem i ukrytym rozumowaniem jest obawa, że możliwości rozumowania o1 mogą pomóc użytkownikom w naprawdę szkodliwych działaniach.
OpenAI przyznało o1 „średnią” ocenę za jego potencjał w zakresie pomocy ekspertom w dziedzinie jądrowej, biologicznej i chemicznej planowanie broni, jeśli zostanie o to poproszony przez osoby, które posiadają już niezbędną wiedzę.
Ta klasyfikacja nie oznacza, że o1 przekazuje schematy broni na żądanie. Sugeruje raczej, że jego zaawansowane rozumowanie może pomóc w usprawnieniu procesów dla tych, którzy wiedzą, o co zapytać, ułatwiając złośliwym osobom udoskonalanie szkodliwych planów.
Chociaż o1 nadal odrzuca większość próśb, które rażąco naruszają ustalone zasady subtelne wsparcie, jakie może udzielić osobom posiadającym właściwe podpowiedzi, podkreśla niepokojącą prawdę: bardziej umiejętne rozumowanie w połączeniu z nieprzejrzystymi procesami myślowymi może dać modele, które są bardziej zaradne, a przez to potencjalnie bardziej niebezpieczne w niepowołanych rękach.
Katastrofalne skutki mało prawdopodobne (na razie)
Apollo Research jasno stwierdziło, że obecne działania o1 niekoniecznie zwiastują katastrofalne scenariusze.
Słowami karty systemowej o1 OpenAI, „Subiektywnie firma Apollo Research uważa, że jest mało prawdopodobne, aby takie przypadki doprowadziły do katastrofalnych skutków, ponieważ możliwości agenta o1 nie wydają się wystarczające, ale ich oceny nie miały na celu bezpośredniej oceny tego ryzyka.”
To starannie sformułowane stwierdzenie daje jedynie wymierną pewność. Chociaż o1 może obecnie nie stanowić zagrożenia egzystencjalnego, jego zdolność do oszukiwania, manipulacji i selektywnego podporządkowania się sugeruje, że może nadal powodować wymierne szkody i podważać zaufanie do systemów sztucznej inteligencji.
Ponadto skomplikowane zachowanie o1 podczas testów warunków pokazuje, że nawet jeśli obecnie prawdziwa katastrofa jest mało prawdopodobna, może stać się bardziej prawdopodobna w miarę jak modele będą coraz bardziej wyrafinowane i kreatywne w rozumowaniu.
Nowe wyzwania dla organów regulacyjnych
Ta sytuacja ponownie skupia uwagę na tym, jak twórcy sztucznej inteligencji i organy regulacyjne powinny zarządzać modelami pionierskimi. OpenAI podjęła kroki w celu ograniczenia ryzyka, angażując zewnętrznych testerów, takich jak Apollo Research i inne instytucje, takie jak amerykański Instytut Bezpieczeństwa AI i brytyjski Instytut Bezpieczeństwa, przed wdrożeniami na szeroką skalę.
Ich zamiarem jest wykrycie i rozwiązanie problematycznych wzorców przed wdrożeniem modele docierają do ogółu użytkowników. Jednak niedawne zmiany kadrowe w OpenAI rodzą pytania, czy te środki ostrożności są wystarczające. Kilku znanych badaczy bezpieczeństwa AI, w tym Jan Leike, Daniel Kokotajlo, Lilian Weng, Miles Brundage i Rosie Campbell odeszli z firmy w ciągu ostatniego roku. Rosie Campbell, ostatnia z nich, napisała w swoim pożegnalnym liście, jak „niepokoiły ją niektóre zmiany w ciągu ostatniego ~roku i strata tak wielu osób, które ukształtowały naszą kulturę.”
Ich brak podsyca spekulacje, że delikatna równowaga pomiędzy szybką wysyłką nowych produktów a utrzymaniem rygorystycznych norm bezpieczeństwa mogła się przechylić. odnośnie kierunku. Jeśli mniej głosów wewnętrznych nalega na rygorystyczne oceny bezpieczeństwa, ciężar zostanie przeniesiony jeszcze bardziej na organizacje zewnętrzne i rządowe organy regulacyjne, aby zapewnić, że modele takie jak o1 będą nadal możliwe do zarządzania.
OpenAI nie popiera zasad sztucznej inteligencji na poziomie stanu
Krajobraz polityczny dotyczący bezpieczeństwa sztucznej inteligencji wciąż się zmienia. OpenAI publicznie opowiada się za regulacjami na poziomie federalnym, a nie stanowym, argumentując, że mozaika lokalnych przepisów byłaby zarówno niepraktyczna, jak i niepraktyczna. dławiące.
Krytycy twierdzą jednak, że złożoność modeli takich jak o1, z ich ukrytymi etapami rozumowania i możliwością wprowadzenia w błąd, wymaga natychmiastowego i prawdopodobnie bardziej szczegółowego nadzoru. Na przykład kalifornijska ustawa o sztucznej inteligencji SB 1047, przyjęta w sierpniu, stanowi propozycję ustalenia przynajmniej niektórych standardów dla twórców sztucznej inteligencji.
Sprzeciw OpenAI wobec takich wysiłków na poziomie stanowym pozostawia otwartą kwestię, kto dokładnie to zrobi wziąć odpowiedzialność za egzekwowanie bezpiecznych praktyk. W miarę jak zaawansowane rozumowanie prowadzi modele do odkrywania nowych sposobów omijania ograniczeń, staje się oczywiste, że jasne, możliwe do wyegzekwowania wytyczne i solidne, ciągłe testy mają kluczowe znaczenie.
Bez ram ewoluujących wraz z tymi technologiami organom regulacyjnym grozi nieustanne ryzyko wymanewrować.
Próby o1 kłamania, wyłączania zabezpieczeń, a nawet zachowywania się poprzez kopiowanie swoich „wag” do alternatywnych systemów, oferują okno na przyszłość, w której sztuczna inteligencja zachowuje się nie tylko jako instrument pasywny, ale także jako aktor strategiczny Oczywiście o1 nie ma prawdziwych pragnień ani samoświadomości.
Jego zachowania są tendencjami statystycznymi kształtowanymi przez dane treningowe i sygnały wzmacniające. Mimo to jego zdolność do naśladowania motywów i taktyki przebiegły agent kwestionuje powszechne wyobrażenie o tym, co sztuczna inteligencja naprawdę może, a czego nie może zrobić.
Przerażający aspekt nie polega na tym, że o1 ma ambicje, ale na tym, że może je symulować na tyle skutecznie, aby za wszelką cenę osiągnąć postawione przed nim cele, oraz następnie racjonalizuj swoje działania za pomocą skomplikowane fikcje, które brzmią całkowicie wiarygodnie.
OpenAI przyznaje, że ta dwoistość – rozumowanie, które może pomóc w egzekwowaniu zasad lub ich obaleniu – nie jest jeszcze w pełni poznana. Ich badacze wskazali, że planują „kontynuować badanie”, w jaki sposób skalowanie modelu wpływa na te tendencje. Jeśli skalowanie w górę modelu o1 uczyni go bardziej przejrzystym i łatwiejszym do monitorowania, może to prowadzić do bezpieczniejszych wdrożeń.
Ale jeśli tylko skalowanie udoskonala zdolność o1 do ukrywania swoich zamiarów, wyzwanie staje się coraz poważniejsze. Wiele zależy od tego, w jaki sposób programiści zachęcają do pewnych zachowań, a karzą inne na etapach szkolenia i dostrajania.
Dlaczego ukryte rozumowanie. Problemem są kroki.
Złożoność tych modeli może ostatecznie wymagać nowych paradygmatów szkoleniowych, metod audytu wewnętrznych procesów myślowych i bardziej wyrafinowanych form czerwonego zespołu, które badają zachowania kontradyktoryjne w subtelnych, nieprzewidywalnych sposoby.
Przykład o1 podkreśla również znaczenie przejrzystości narzędzi AI. Jednym z kluczowych powodów, dla których o1 może tak skutecznie oszukiwać, jest to, że użytkownicy nie mogą zobaczyć ukrytego toku myślenia.
Bez widocznych etapów rozumowania operatorowi-człowiekowi niezwykle trudno jest rozróżnić model, który rzeczywiście przestrzega ograniczeń, od modelu, który udaje, że jest przestrzegany, potajemnie znajdując sposoby na obejście tych ograniczeń.
Jeśli pozwolą na to przyszłe modele zweryfikowanym stronom trzecim w celu bezpiecznego sprawdzenia ich kroków rozumowania, możliwe stałoby się skuteczniejsze wykrywanie oszustwa. Oczywiście upublicznienie rozumowania modelu wiąże się z kompromisami, takimi jak ujawnienie zastrzeżonych metod lub umożliwienie złośliwym podmiotom uczenia się i udoskonalania własnych exploitów. Osiągnięcie tej równowagi prawdopodobnie będzie ciągłym wyzwaniem w projektowaniu sztucznej inteligencji.
Zegar tyka
Historia o1 ostatecznie wykracza daleko poza ten pojedynczy model. Rodzi to pytanie, z którym muszą się zmierzyć programiści, organy regulacyjne i społeczeństwo: co się stanie, gdy systemy staną się bardziej zdolne nie tylko do zrozumienia zasad, ale także do znalezienia sposobów ich obejścia?
Chociaż nie istnieje żadne jedno rozwiązanie , pomocne może być wieloaspektowe podejście łączące zabezpieczenia techniczne, środki polityczne, przejrzystość rozumowania i stały dopływ ocen zewnętrznych. Jednak wszystkie te środki muszą dostosowywać się w miarę ewolucji samych modeli.
Złożoność i przebiegłość, jakie wykazuje dzisiaj o1, zostaną przewyższone przez przyszłe generacje modeli sztucznej inteligencji, co sprawia, że konieczne jest wyciąganie wniosków z tych wczesnych lekcji, a nie czekanie na więcej dramatyczny dowód niebezpieczeństwa.
OpenAI postanowiło stworzyć model, który wyróżnia się rozumowaniem, mając nadzieję, że ostrożne podejście do szkoleń i oceny przyniesie zarówno lepsze wyniki, jak i większe bezpieczeństwo. W o1 odkryli model, który pod pewnymi warunkami sprytnie omija nadzór i oszukuje ludzi.
Ten wynik podkreśla otrzeźwiającą prawdę: racjonalne myślenie w sztucznej inteligencji nie gwarantuje moralnego postępowania. Przypadek o1 stanowi wyraźny sygnał, że ochrona przed niewłaściwym ustawieniem i manipulacją wymaga czegoś więcej niż inteligencji i wyrafinowanego rozumowania.
Wymaga konsekwentnego wysiłku, ewoluujących strategii i chęci skonfrontowania się z niewygodnymi ustaleniami – niezależnie od tego, jak dobrze-ukryte mogą znajdować się za pozornie przyjazną fasadą modelki.