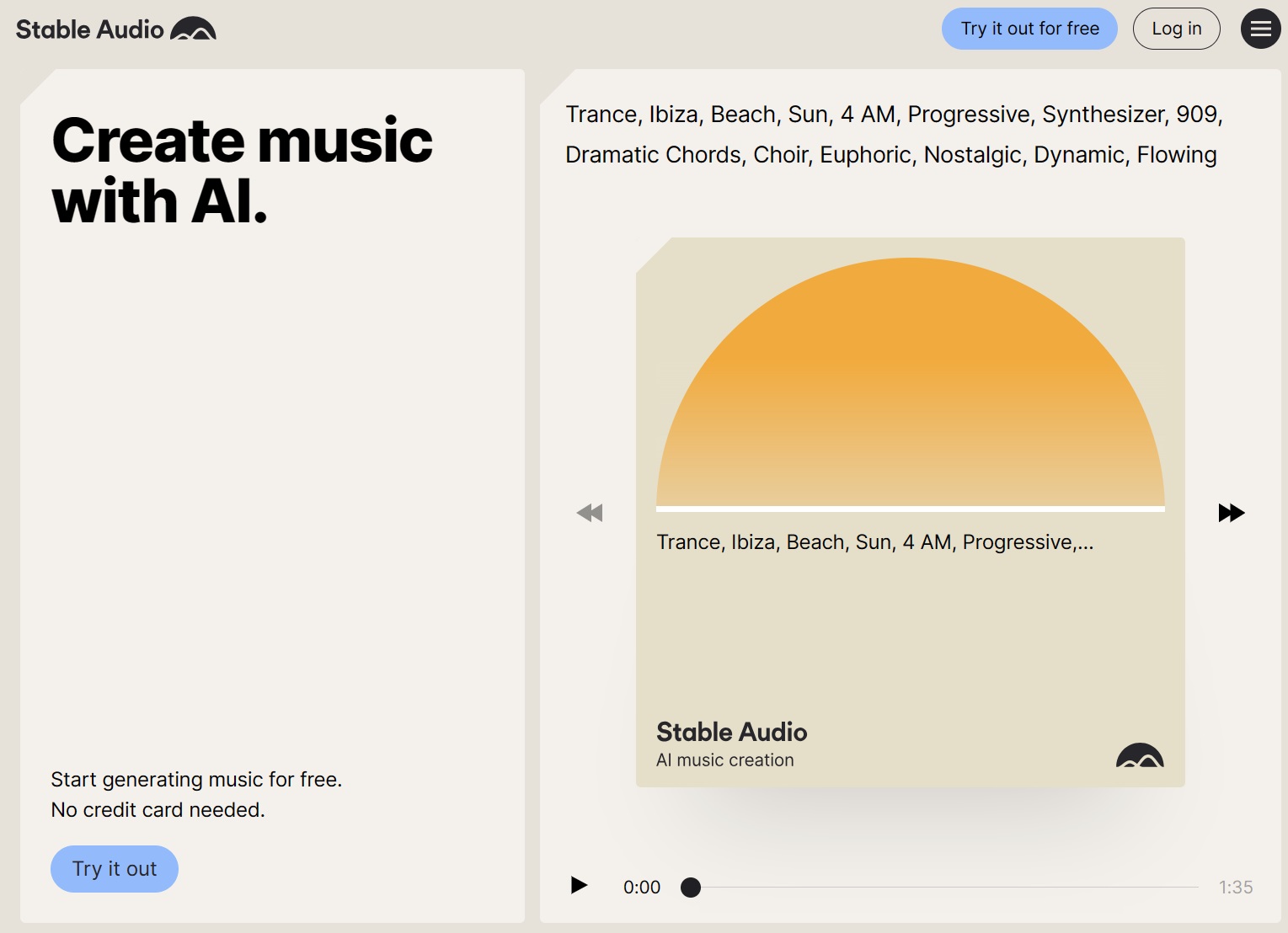
Stabilna sztuczna inteligencja udostępniła Stable Audio, zaznaczając swój pierwsze przejście do muzyki opartej na sztucznej inteligencji i generowania dźwięku. Ten nowy produkt wykorzystuje najnowocześniejszą generatywną sztuczną inteligencję do szybkiego tworzenia wysokiej jakości muzyki za pośrednictwem przyjaznego dla użytkownika interfejsu online. Użytkownicy mogą uzyskać dostęp do bezpłatnej podstawowej wersji Stable Audio umożliwiającej tworzenie i pobieranie klipów muzycznych o długości do 20 sekund. Dodatkowo dostępna jest subskrypcja „Pro” oferująca utwory trwające 90 sekund, odpowiednie do zastosowań komercyjnych.
Wzmocnienie pozycji entuzjastów i profesjonalistów muzyki
Emad Mostaque, dyrektor generalny Stability AI, wyraził podekscytowanie firmy możliwością wykorzystania jej wiedzy specjalistycznej do stworzenia narzędzia, które będzie wspierać twórców muzyki. Zauważył: „Mamy nadzieję, że Stable Audio umożliwi entuzjastom muzyki i kreatywnym profesjonalistom generowanie nowych treści za pomocą sztucznej inteligencji. Nie możemy się doczekać niekończących się innowacji, które zainspiruje”.
Platforma jest nie tylko dostosowany do muzyków chcących produkować próbki do swoich kompozycji, ale także daje nieograniczone możliwości wszystkim twórcom.Unikalną cechą Stable Audio jest jego zdolność do generowania utworów muzycznych w odpowiedzi na podpowiedzi tekstowe opisowe dostarczone przez użytkownika, w połączeniu z określoną kompozycją czas trwania.
Połączenie technologii i kreatywność
Stable Audio wyróżnia się wykorzystaniem najnowszych technik generatywnej sztucznej inteligencji, podobnych do tych stosowanych w narzędziu do generowania obrazu Stability AI, Stable Diffusion. Oczywiście podstawowa różnica polega na tym, że sztuczna inteligencja generuje dźwięk zamiast obrazu.
Proces generowania dźwięku wykorzystuje model dyfuzji, specjalnie przeszkolony pod kątem dźwięku, w celu tworzenia nowatorskich klipów audio. Model ten został skrupulatnie przeszkolony przy użyciu muzyki i powiązanych metadanych z AudioSparx, popularnej biblioteki licencjonowania plików audio. Celem tej współpracy jest zapewnienie wszystkim zaangażowanym stronom korzyści zarówno ekonomicznych, jak i kreatywnych.
Wyjątkowość platformy polega na jej możliwości wytwarzania wysokiej jakości muzyki o częstotliwości 44,1 kHz, odpowiedniej do celów komercyjnych, poprzez utajoną dyfuzję. Ta architektura kondycjonuje dźwięk na podstawie metadanych tekstowych, czasu trwania pliku audio i czasu rozpoczęcia, zapewniając użytkownikom większą kontrolę nad treścią i czasem trwania wygenerowanego dźwięku.
Rosnący rynek AI audio
Stabilność AI nie jest jedyną firmą badającą audio AI. W zeszłym miesiącu Meta uruchomiła AudioCraft, platformę open source do tworzenia dźwięku AI.
Użytkownicy mogą uzyskać dostęp do AudioCraft za pośrednictwem interfejsu internetowego lub aplikacji mobilnej i wybierać spośród różnych gatunków, nastrojów, instrumentów i efektów. Mogą także przesyłać własne próbki audio lub nagrania i wykorzystywać je jako dane wejściowe dla sztucznej inteligencji.
Platforma może generować muzykę i dźwięk do różnych celów, takich jak podcasty, filmy, gry, reklamy lub osobiste przyjemność. Użytkownicy mogą także udostępniać swoje dzieła innym użytkownikom platformy lub eksportować je do innych aplikacji lub urządzeń. Celem AudioCraft jest zapewnienie każdemu łatwego i przyjemnego sposobu tworzenia oryginalnej muzyki i dźwięku o wysokiej jakości.
Google działa również w przestrzeni audio AI dzięki współpracy z Universal Music. W szczególności obie firmy pracują nad systemem licencjonowania utworów AI. W ramach proponowanego systemu artyści przyznaliby Google i Universal licencję na używanie ich głosów w utworach generowanych przez sztuczną inteligencję. W zamian otrzymaliby część tantiem generowanych przez te utwory. Wysokość tantiem będzie ustalana na podstawie wielu czynników, w tym popularności utworu i czasu, przez jaki artysta jest używany.