Forskere ved Tencent AI Lab har avduket et nytt AI-rammeverk designet for å knuse fartsgrensene til nåværende store språkmodeller.
Detaljert i en artikkel publisert på nettet denne uken, heter systemet CALM, for Continuous Autoregressive Language Models. Den utfordrer direkte den langsomme, token-by-token-prosessen som driver den mest generative AI i dag.
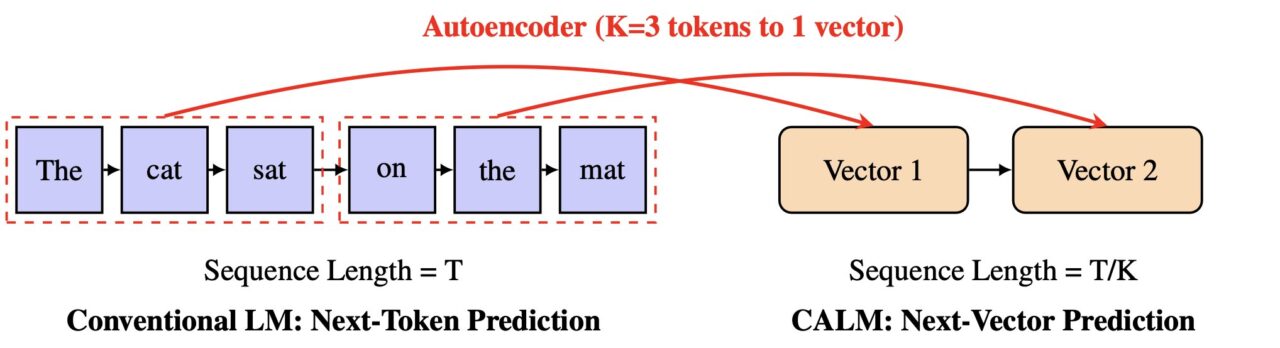
I stedet for å forutsi en liten del av et ord om gangen, lærer CALM å forutsi en enkelt vektor som representerer en hel tekstbit. Denne metoden kan gjøre AI-generering mye raskere og mer effektiv, noe som åpner en ny vei for skalering av modeller.
Dette effektivitetsproblemet har blitt en sentral kampplass for AI-utviklere. Som Google Research tidligere har bemerket, “når vi distribuerer disse modellene til flere brukere, er det en kritisk utfordring å gjøre dem raskere og rimeligere uten å ofre kvalitet.”
Bransjen har utforsket en rekke løsninger, fra Googles spekulative kaskader til nye komprimeringsteknikker. Nå foreslår Tencents arbeid en mer radikal løsning.
Avisen foreslår en blåkopi for en ny klasse av ultra-effektive språkmodeller og til den token-induserte flaskehalsen for hastighet.
Målet er å fundamentalt endre prediksjonsenheten fra et enkelt token med lite informasjon til noe mye rikere.
I en direkte utfordring til status quo til generativ AI, omformer CALM prediksjonsoppgaven fullstendig. Forskerne foreslår en ny skaleringsakse for LLM-er.
“Vi argumenterer for at å overvinne denne flaskehalsen krever en ny designakse for LLM-skalering: å øke den semantiske båndbredden til hvert generative trinn,”skriver de i avisen.
Ved å øke denne”semantiske båndbredden,”kan modellen behandle mer informasjon i en enkelt trinn. CALM oppnår dette gjennom en innovativ to-trinns prosess som opererer i et kontinuerlig, snarere enn diskret, rom.
Kjernen i CALMs design er en autoenkoder med høy kvalitet. Denne komponenten lærer å komprimere en del av K tokens – for eksempel fire tokens – til en enkelt, tett kontinuerlig vektor.
Det er avgjørende at den kan rekonstruere de originale tokenene fra denne vektoren med over 99,9 % nøyaktighet. En separat språkmodell utfører deretter autoregressiv prediksjon i dette nye vektorrommet.
I følge prosjektets offisielle dokumentasjon,”i stedet for å forutsi ett diskret symbol om gangen, lærer CALM å forutsi en enkelt kontinuerlig vektor som representerer en enkelt vektor til Kp>.”reduserer antall generative trinn med en faktor K, noe som fører til betydelige effektivitetsgevinster.
The Likelihood-Free Toolkit: How CALM Learns and Measures Success
Å flytte fra diskrete tokens til kontinuerlige vektorer introduserer en stor utfordring: modellen kan ikke lenger beregne distribusjon over et eksplisitt sannsynlighetslag.
Dette gjør tradisjonelle opplærings-og evalueringsmetoder, som er avhengige av å beregne sannsynligheter, uanvendelige. For å løse dette utviklet Tencent-teamet et omfattende, sannsynlighetsfritt rammeverk.
For trening bruker CALM en energibasert treningsmetode, som bruker en strengt korrekt skåringsregel for å veilede modellen uten å måtte beregne sannsynligheter.
For evaluering introduserte forskerne en ny metrikk kalt BrierLM. Når man beveger seg bort fra tradisjonelle beregninger som forvirring, er BrierLM avledet fra Brier-poengsummen, et verktøy fra sannsynlige prognoser.
Det gir mulighet for en rettferdig, utvalgsbasert sammenligning av modellens evner ved å sjekke hvor godt spådommer stemmer overens med virkeligheten, en metode som passer perfekt for modeller der sannsynlighetene er vanskelige å behandle.
for effektivitet
Den praktiske virkningen av denne nye arkitekturen er en overlegen ytelse-beregningsavveining.
CALM-modellen reduserer treningsberegningskravene med 44 % og konklusjonen med 33 % sammenlignet med en sterk baseline. Dette viser at skalering av den semantiske båndbredden for hvert trinn er en kraftig ny spak for å forbedre beregningseffektiviteten.
Arbeidet posisjonerer CALM som en betydelig konkurrent i det bransjeomfattende kappløpet om å bygge raskere, billigere og mer tilgjengelig AI.
Google har taklet AI-hastighetsproblemet med metoder som spekulativ læring. Andre startups, som Inception, utforsker helt andre arkitekturer som diffusjonsbaserte LLM-er i sin “Mercury Coder” for å unnslippe den”strukturelle flaskehalsen”av autoregresjon.
Sammen fremhever disse varierte tilnærmingsutviklingen. Industrien beveger seg fra et rent fokus på skala til en mer bærekraftig jakt på smartere, mer økonomisk levedyktig kunstig intelligens. CALMs vektorbaserte tilnærming tilbyr en ny vei fremover på den fronten.


