AI-koding IDE Cursor lanserte sin første interne modell, Composer, 29. oktober. Utgivelsen falt sammen med en større plattformoppdatering, Cursor 2.0.
Med prioritering av hastighet, hevdes den nye Composer-modellen av selskapet å være fire ganger raskere enn lignende verktøy.
Cursor aging multi-design AI introduserer samtidig en managing agent 2.0. Utviklere kan nå sammenligne utdata fra forskjellige modeller på samme oppgave.
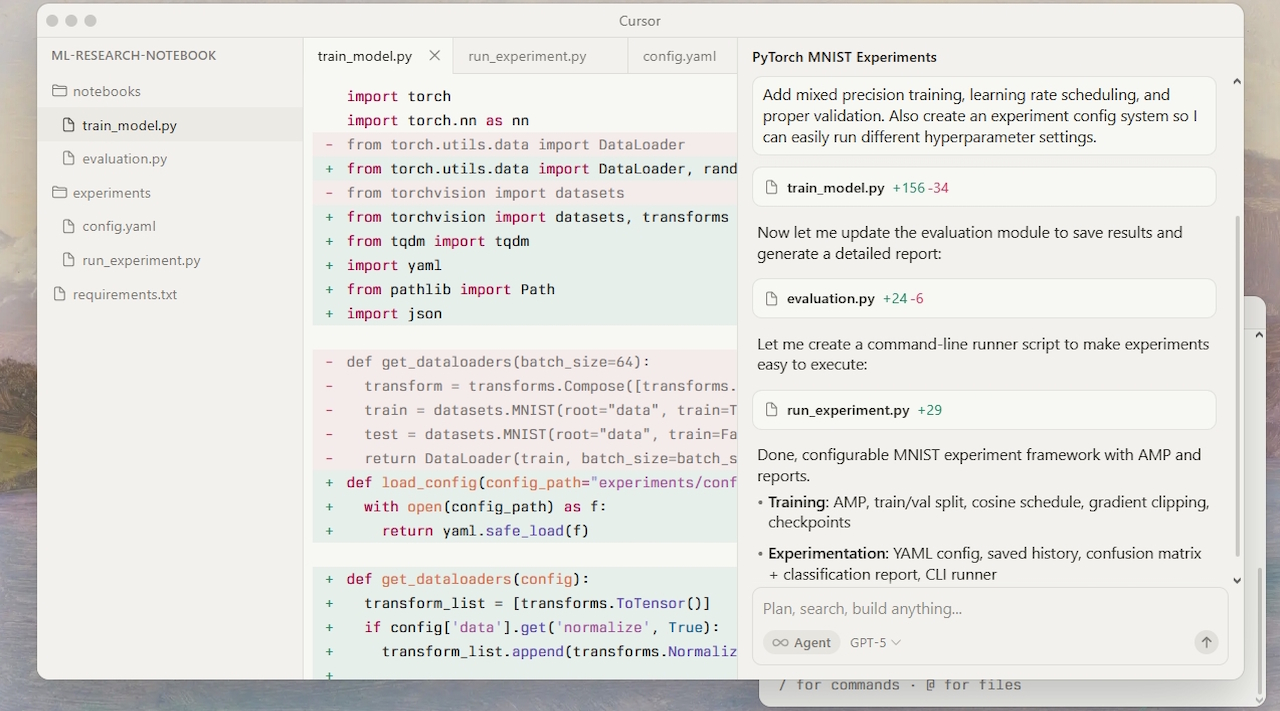
Selv om lanseringen har høstet ros fra tidlige brukere for sin ytelse, har den også vakt opprinnelsen til åpenhet og kritikk. sin bruk av private ytelsesreferanser.
A Need for Speed: Introducing the Composer Model
Med sikte på å holde utviklere i flyttilstand, har Cursor posisjonert Composer som en grenseverdimodell, bygget for lavkoding. Cursor beskriver den som en blanding av eksperter (MoE) modell. Den var spesialisert for programvareutvikling gjennom forsterkningslæring (RL).
I løpet av opplæringen fikk modellen tilgang til verktøy som semantisk søk og fikk i oppgave å løse virkelige kodingsutfordringer. I følge Cursor er resultatet en modell som fullfører de fleste agentsvinger på under 30 sekunder. Slik ytelse vil gjøre den fire ganger raskere enn tilsvarende intelligente konkurrenter.
Disse ytelsespåstandene er imidlertid basert på en proprietær intern evaluering kalt”Cursor Bench.”Denne referansen består av ekte agentforespørsler fra selskapets egne ingeniører. Mangel på en offentlig, replikerbar benchmark har blitt et sentralt debattpunkt etter lanseringen.
Til tross for hemmelighold, har selskapet vært åpen om priser. I følge den offisielle dokumentasjonen koster Composer-modellen $1,25 per million input-tokens og $10,00 per million output tokens. Den er plassert til samme prisklasse som GPT-5 og Gemini 2.5 Pro i Cursor-miljøet, noe som signaliserer tillit til dens evner.
Juggling Agents: A New Interface in Cursor 2.0
Sammen med den nye modellen, markerer utgivelsen av Cursor 2.0 et betydelig skifte i designen til IDE. Den går fra en fil-sentrisk til en agent-sentrisk arbeidsflyt. Det oppdaterte grensesnittet er bygget for å kjøre mange agenter parallelt uten at de forstyrrer hverandre.
Denne multi-agent-arkitekturen er git-arbeidstre eller eksterne maskiner. Slike verktøy skaper isolerte miljøer for hver agent å jobbe i, og forhindrer konflikter.
Ved å bruke dette oppsettet kan utviklere tilordne den samme komplekse oppgaven til forskjellige modeller samtidig – for eksempel be både Sonnet 4.5 og Composer om å implementere en funksjon.
Brukere kan deretter sammenligne resultatene og velge den beste tilnærmingen. Arbeidsflyten, kjent som «vibe-koding», får gjennomslag som en måte å utnytte de distinkte styrkene til ulike AI-modeller på. Google har nylig fornyet sitt AI Studio med en lignende filosofi.
Inkludert i oppdateringen er også verktøy for å strømlinjeforme kodegjennomgang og testing, og integrere AI ytterligere i utviklingslivssyklusen.
A Polarized Reception: Community Praise and Skepticism
Genererer en bølge av diskusjoner i skarpe todelte fellesskap. Mens noen brukere hyllet den nye modellens reaksjonsevne, rapporterte andre om betydelige problemer. En Hacker News-tråd som diskuterte lanseringen fanget denne polariserte følelsen perfekt.
På den ene siden berømmet tidlige brukere den nye modellens ytelse. En bruker skrev:”Composer gjorde alt bedre, snublet ikke der Codex feilet, og viktigst av alt, hastigheten utgjør en stor forskjell. Den er ekstremt behagelig å bruke, gratulerer.”
På den annen side rapporterte flere brukere om en frustrerende første opplevelse. En kommenterte:”Jeg brukte det nye systemet i kveld, og det føltes som en klar nedgradering. Genererte noen få grunnleggende apper som ikke fungerer, kunne ikke håndtere CSS i et NextJS-miljø.”
Skepsis dukket raskt opp på plattformer som Hacker News angående selskapets påstander. Primær kritikk dreier seg om mangelen på åpenhet.
Som en bruker påpekte,”Mangelen på åpenhet her er vill. De samler poengsummene til modellene de tester mot, noe som skjuler ytelsen. De publiserer bare resultater på sin egen interne benchmark som de ikke vil frigi.”
Ekko av denne modellen satte andre spørsmålstegn ved denne følelsen for komposisjoner. det er vanskelig å uavhengig vurdere arkitekturen eller potensielle skjevheter.
Et trekk mot proprietære, interne modeller, er en del av en større bransjetrend. Hastighet og spesialisering er i ferd med å bli viktige differensiatorer.
I en kommentar formulerte en Cursor ML-forsker selskapets strategi, og sa:”Vår oppfatning er at det nå er en minimal mengde intelligens som er nødvendig for å være produktiv, og at hvis du kan koble det sammen med hastighet, er det kjempebra.”
En slik potensiell filosofi er en kraftigere komponist, men en langsommere filosofi. labs.
For noen utviklere er imidlertid rå intelligens fortsatt toppprioritet. Som en bruker bemerket: «Kanskje jeg er en uteligger, men Sonnet 4.5-kvaliteten er omtrent så lav som jeg er villig til å gå. Cursors strategi plasserer den i et sterkt konkurranseutsatt marked.
GitHub avduket nylig sin egen multi-agent-plattform, Agent HQ, som forener modeller fra OpenAI, Anthropic og Google under ett enkelt kontrollplan.
I mellomtiden fortsetter individuelle leverandører som Anthropic å avgrense tilbudene sine, for eksempel dens egen nettlanserte modell.
satser på at en tett integrert høyhastighetsopplevelse kan skape en lojal brukerbase, selv om det betyr å ofre noe av råkraften til de største frontier-modellene.