Forskere ved Mohamed bin Zayed University of Artificial Intelligence (MBZUAI) i Abu Dhabi har avduket LlamaV-o1, en ny multimodal AI-modell som prioriterer åpenhet og logisk sammenheng i resonnementet.
I motsetning til andre resonnerende AI-modeller, som ofte leverer black-box-utganger, demonstrerer LlamaV-o1 sin problemløsningsprosess trinn for trinn, slik at brukerne kan spore hvert trinn i logikken.
Parret med introduksjonen av VRC-Bench, en ny målestokk for evaluering av mellomliggende resonnementtrinn, tilbyr LlamaV-o1 et nytt perspektiv på AI-tolkbarhet og brukervennlighet innen ulike felt som medisinsk diagnostikk, finans og vitenskapelig forskning.
Utgivelsen av denne modellen og benchmark gjenspeiler den økende etterspørselen etter AI-systemer som ikke bare leverer nøyaktige resultater, men forklar også hvordan disse resultatene oppnås.
Relatert: OpenAI avslører ny o3-modell med drastisk forbedrede resonneringsferdigheter
VRC-benk: En benchmark designet for transparent resonnement
VRC-bench-referansen er et kjerneelement i LlamaV-o1s utvikling og evaluering. Tradisjonelle AI-benchmarks fokuserer først og fremst på nøyaktighet av endelige svar, og neglisjerer ofte de logiske prosessene som fører til disse svarene.
VRC-Bench adresserer denne begrensningen ved å evaluere kvaliteten på resonnement-trinnene gjennom beregninger som Faithfulness-Step og Semantic Coverage, som måler hvor godt en modells resonnement stemmer overens med kildematerialet og logisk konsistens.
Relatert: Googles nye Gemini 2.0 Flash Thinking Model utfordrer OpenAIs o1 Pro med utmerket ytelse
VRC-Bench dekker over 1000 oppgaver i åtte kategorier, og inkluderer domener som visuell resonnement, medisinsk bildebehandling og kulturell kontekstanalyse. Disse oppgavene har mer enn 4000 manuelt bekreftede resonnementtrinn, noe som gjør referansen til en av de mest omfattende i evaluering av trinnvise resonnementer.
Forskerne beskriver viktigheten av den, og sier: «De fleste referanser fokuserer først og fremst på nøyaktighet i sluttoppgaven, og neglisjerer kvaliteten på mellomliggende resonnementtrinn. VRC-Bench byr på et mangfoldig sett av utfordringer… muliggjør robust evaluering av logisk sammenheng og korrekthet i resonnement.”
Ved å sette en ny standard for multimodal AI-evaluering, sikrer VRC-Bench at modeller som LlamaV-o1 er holdt ansvarlig for sine beslutningsprosesser, og tilbyr et nivå av åpenhet som er kritisk for høyinnsatsapplikasjoner.
Performance Metrics: How LlamaV-o1 skiller seg ut
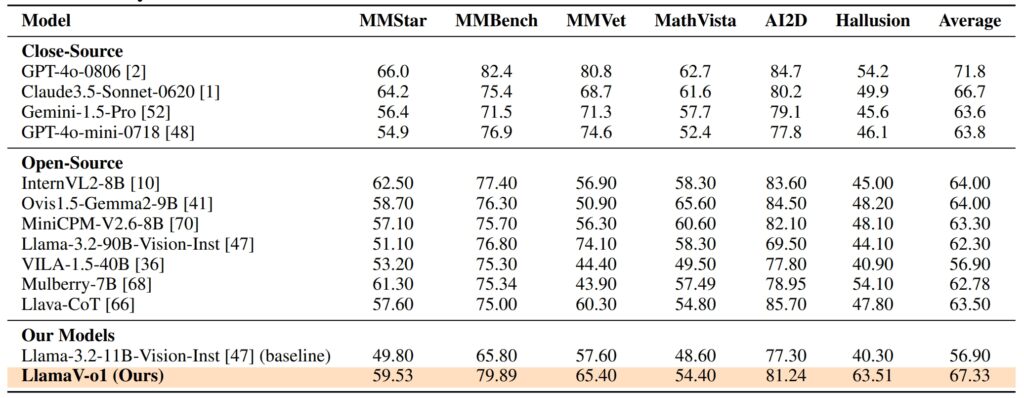
LlamaV-o1s ytelse på VRC-Bench og andre benchmarks demonstrerer dens tekniske dyktighet åpen kildekode-modeller som LLava-CoT (66.21) og redusere gapet med proprietære modeller som f.eks. GPT-4o, som fikk 71,8
I tillegg til nøyaktigheten, leverte LlamaV-o1 fem ganger raskere slutningshastigheter sammenlignet med sine jevnaldrende, noe som viser effektiviteten.
På seks multimodale benchmarks— inkludert MathVista, AI2D og Halllusion—LlamaV-o1 sikret en gjennomsnittlig poengsum på 67,33 % understreker dens evne til å håndtere ulike resonneringsoppgaver samtidig som logisk sammenheng og åpenhet opprettholdes.
Training LlamaV-o1: The Synergy of Curriculum Learning and Beam Search
LlamaV-o1s suksess er forankret i dens innovative treningsmetoder. Forskerne brukte læreplanlæring, en teknikk inspirert av menneskelig utdanning.
Denne tilnærmingen begynner med enklere oppgaver og utvikler seg gradvis til mer komplekse oppgaver, slik at modellen kan bygge grunnleggende resonneringsferdigheter før de takler avanserte utfordringer.
Ved å strukturere opplæringsprosessen, forbedrer læreplanlæring modellens evne til å generalisere på tvers av ulike oppgaver, fra dokument-OCR til vitenskapelig resonnement.
Relatert: Alibabas QwQ-32B-Preview slutter seg til AI Model Reasoning Battle With OpenAI
Beam Search, en optimaliseringsalgoritme, forbedrer denne treningstilnærmingen ved å generere flere resonneringsveier parallelt og velge den mest logiske. Denne metoden forbedrer ikke bare modellens nøyaktighet, men reduserer også beregningskostnadene, noe som gjør den mer effektiv for applikasjoner i den virkelige verden.
Som forskerne forklarer,”Ved å utnytte læreplanlæring og strålesøk, tilegner modellen vår gradvis ferdigheter… og sikrer både optimalisert slutning og robuste resonneringsevner.”
Applikasjoner i medisin , Finance, and Beyond
LlamaV-o1s gjennomsiktige resonneringsevner gjør den spesielt egnet for applikasjoner der tillit og tolkbarhet er avgjørende I medisinsk bildebehandling, for eksempel, kan modellen gi ikke bare en diagnose, men en detaljert forklaring på hvordan den kom til den konklusjonen
Denne funksjonen gjør det mulig for radiologer og andre medisinske fagpersoner å validere AI-. drevet innsikt, som øker tilliten og nøyaktigheten i kritiske beslutninger.
I finanssektoren utmerker LlamaV-o1 seg på å tolke komplekse diagrammer og diagrammer, som gir trinnvise oversikter som gir praktisk innsikt.
LlamaV-o1 representerer et betydelig fremskritt innen multimodal AI, spesielt i sin evne til å gi transparente resonnementer. Ved å kombinere læreplanlæring og strålesøk med de robuste evalueringsmålingene til VRC-Bench, setter det en ny standard for tolkning og effektivitet.
Etter hvert som AI-systemer blir stadig mer integrert i kritiske bransjer, vil behovet for modeller som kan forklare resonneringsprosessene deres bare vokse.