Microsoft har introdusert rStar-Math, en fortsettelse og foredling av den tidligere rStar-rammeverket, for å flytte grensene for små språkmodeller (SLM) i matematisk resonnement.
Designet for å konkurrere med større systemer som OpenAIs o1-forhåndsvisning, oppnår rStar-Math bemerkelsesverdige standarder innen problemløsning samtidig som de demonstrerer hvordan kompakte modeller kan prestere på konkurransedyktige nivåer. Denne utviklingen viser et skifte i AI-prioriteringer, fra å skalere opp til å optimalisere ytelsen for spesifikke oppgaver.
Avgang fra rStar til rStar-Math
rStar rammeverket fra i fjor sommer la grunnlaget for å forbedre SLM-resonnementet gjennom Monte Carlo Tree Search (MCTS), en algoritme som avgrenser løsninger ved å simulere og validere flere baner.
rStar demonstrerte at mindre modeller kunne håndtere komplekse oppgaver, men applikasjonen forble generell. rStar-Math bygger på dette grunnlaget med målrettede innovasjoner skreddersydd for matematisk resonnement.
Sentralt for rStar-Maths suksess er dens kodeforsterkede tankekjede-metodikk (CoT), der modellen produserer løsninger i både naturlig språk og kjørbar Python-kode.
Denne strukturen med to utdata sikrer at mellomliggende resonnementtrinn er verifiserbare, reduserer feil og opprettholder logisk konsistens. Forskerne understreket viktigheten av denne tilnærmingen, og uttalte:”Gjensidig konsistens gjenspeiler den vanlige menneskelige praksisen i fravær av tilsyn, der enighet mellom jevnaldrende om avledede svar antyder en høyere sannsynlighet for korrekthet.”
Relatert: Kinesisk DeepSeek R1-Lite-Preview-modell retter seg mot OpenAIs leder innen automatisert resonnement
I tillegg til CoT, rStar-Math introduserer en Process Preference Model (PPM), som evaluerer og rangerer mellomtrinn basert på kvalitet I motsetning til tradisjonelle belønningssystemer som ofte er avhengige av støyende data, prioriterer PPM logisk sammenheng og nøyaktighet, noe som forsterker modellens pålitelighet:
“PPM utnytter det faktum at selv om Q-verdier fortsatt ikke er presise nok til å score hvert resonnementtrinn til tross for bruk av omfattende MCTS-utrullinger, kan Q-verdiene på en pålitelig måte skille positive (riktige) trinn fra negative (irrelevante/feilaktige).
Dermed konstruerer treningsmetoden preferansepar for hvert trinn basert på Q-verdier og bruker et parvis rangeringstap for å optimalisere PPMs poengprediksjon for hvert resonnementtrinn, for å oppnå pålitelig merking. Denne tilnærmingen unngår konvensjonelle metoder som direkte bruker Q-verdier som belønningsetiketter, som iboende er støyende og upresise i trinnvise belønningstildelinger. policymodell og PPM fra bunnen av.
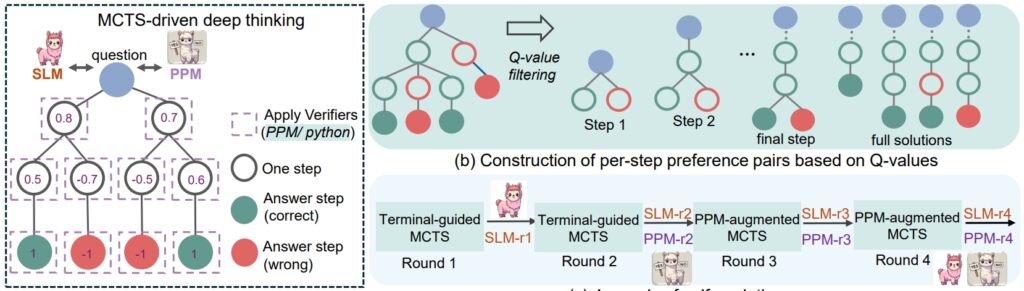 rSTar-Math resonnementsprosedyre (Kilde: forskningsoppgave)
rSTar-Math resonnementsprosedyre (Kilde: forskningsoppgave)
Ytelse som utfordrer større modeller
rStar-Math setter nye standarder i matematiske resonnementer, for å oppnå resultater som konkurrerer med, og i noen tilfeller overgår, resultatene til større AI-systemer
På . GSM8K-datasett, en test for matematisk resonnement, forbedret nøyaktigheten til en modell med 7 milliarder parametere fra 12,51 % til 63,91 % etter integrering av rStar-Math I American Invitational Mathematics Examination (AIME) løste modellen 53,3 % av problemene. plasserer den blant de øverste 20 % av deltakerne på videregående skole.
MATH-datasettets resultater var like imponerende, med rStar-Math som oppnådde en nøyaktighetsgrad på 90 %, og overgikk OpenAIs o1-forhåndsvisning.
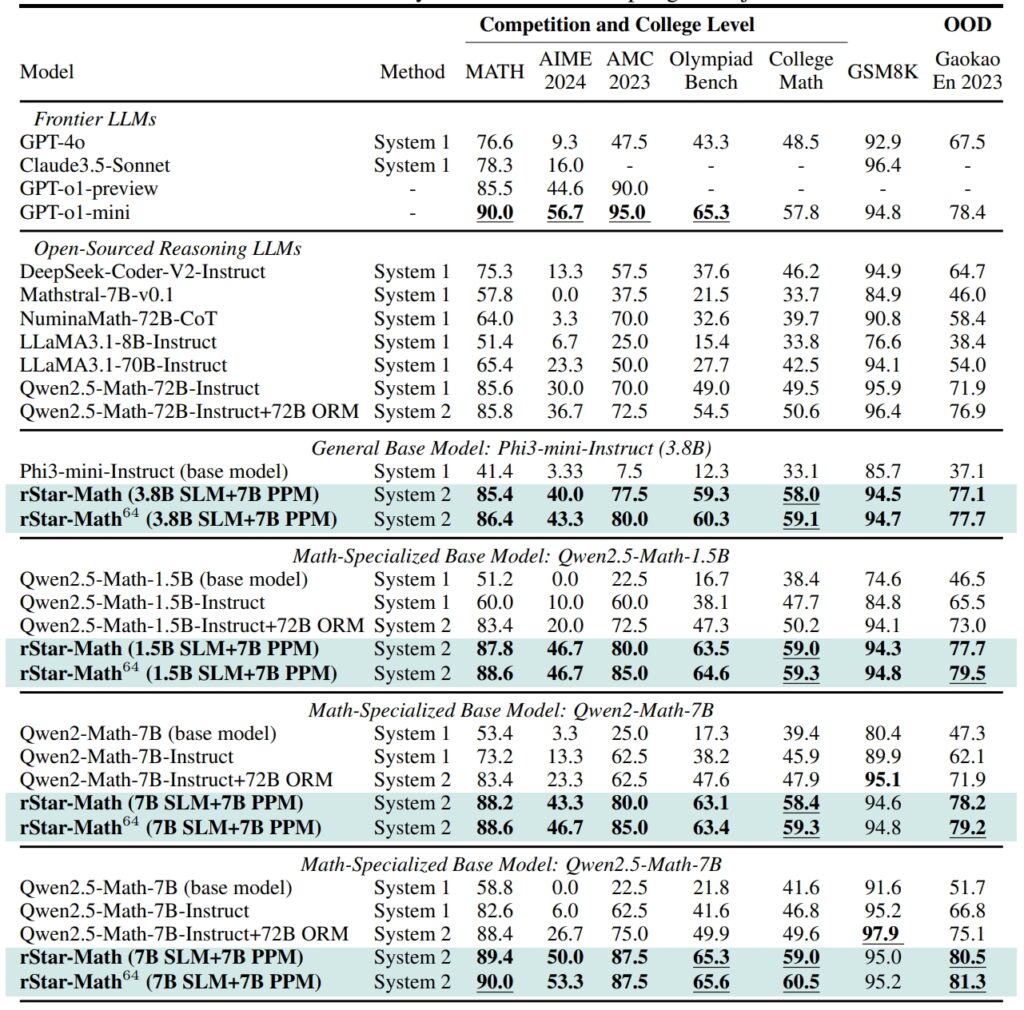 Ytelse av rStar-Math og andre grensebaserte LLM-er på den mest utfordrende matematikken benchmarks (Kilde: forskningsartikkel)
Ytelse av rStar-Math og andre grensebaserte LLM-er på den mest utfordrende matematikken benchmarks (Kilde: forskningsartikkel)
Disse prestasjonene fremhever rammeverkets evne til å gjøre det mulig for SLM-er å håndtere oppgaver som tidligere var dominert av ressurskrevende store modeller. Ved å legge vekt på logisk konsistens og verifiserbare mellomtrinn, adresserer rStar-Math en av AIs mest vedvarende utfordringer: å sikre pålitelig resonnement på tvers av komplekse problemområder.
Tekniske innovasjoner som driver rStar-Math
Utviklingen fra rStar til rStar-Math introduserer flere viktige fremskritt. Integreringen av MCTS er fortsatt sentral i rammeverket, noe som gjør det mulig for modellen å utforske ulike resonnementveier og prioritere de mest lovende.
Tillegget av CoT-resonnement, med fokus på kodeverifisering, sikrer at utdataene er både tolkbare og nøyaktige.
Relatert: Alibabas QwQ-32B-Forhåndsvisning slutter seg til AI-modellen i kamp med OpenAI
Kanskje mest transformerende er rStar-Maths selvevolusjonære treningsprosess. Over fire iterative runder avgrenser rammeverket sin policymodell og PPM, og inkluderer resonnementdata av høyere kvalitet på hvert trinn.
Denne iterative tilnærmingen lar modellen kontinuerlig forbedre ytelsen, og oppnå toppmoderne resultater uten å stole på destillasjon fra større modeller.
Sammenligning av rStar-Math til OpenAIs o1
Mens Microsoft fokuserer på å optimalisere mindre modeller, fortsetter OpenAI å prioritere å skalere opp systemene sine.
o1 Pro Mode, introdusert i desember 2024 som en del av ChatGPT Pro-planen, tilbyr avanserte resonneringsmuligheter skreddersydd for høyinnsatsapplikasjoner som koding og vitenskapelig forskning. OpenAI rapporterte at o1 Pro Mode oppnådde en nøyaktighetsrate på 86 % på AIME og en suksessrate på 90 % i kodingsreferanser som Codeforces.
rStar-Math representerer et skifte i AI-innovasjon, og utfordrer bransjens fokus på større modeller. som det primære middelet for å oppnå avansert resonnement. Ved å forbedre SLM-er med domenespesifikke optimaliseringer, tilbyr Microsoft et bærekraftig alternativ som reduserer beregningskostnader og miljøpåvirkning.
Relatert: Deliberative Alignment: OpenAIs sikkerhetsstrategi for sine o1-og o3-tenkemodeller
Rammeverkets suksess i matematisk resonnement åpner dører til bredere anvendelser, fra utdanning til vitenskapelig forskning.
Forskerne planlegger å frigi rStar-Maths kode og data på GitHub, og baner vei for videre samarbeid og utvikling. Denne åpenheten gjenspeiler Microsofts tilnærming til å gjøre AI-verktøy med høy ytelse tilgjengelig for et bredere publikum, inkludert akademiske institusjoner og mellomstore organisasjoner.
Relatert: SemiAnalysis: Nei, AI Scaling Isn’t Slowing Down
Når konkurransen mellom Microsoft og OpenAI øker, fremhever fremskrittene introdusert av rStar-Math potensialet til mindre modeller for å utfordre dominansen til større systemer. Ved å prioritere effektivitet og nøyaktighet setter rStar-Math en ny standard for hva kompakte AI-systemer kan oppnå.