Qwen-forskerteamet på Alibaba har introdusert QVQ-72B, en åpen kildekode multimodal AI-modell designet for å kombinere visuelle og tekstlige resonnementer. Med sin evne til å behandle bilder og tekst trinn for trinn, tilbyr modellen en ny tilnærming til problemløsning som utfordrer dominansen til proprietære systemer som OpenAIs GPT-4.
Alibabas Qwen-team beskriver QVQ-72B som et skritt mot deres langsiktige mål om å skape en mer omfattende AI som er i stand til å håndtere vitenskapelige og analytiske utfordringer.
Ved å gjøre modellen åpent tilgjengelig under Qwen-lisensen, tar Alibaba sikte på å fremme samarbeid i AI-fellesskapet samtidig som utviklingen av kunstig generell intelligens (AGI) fremmes.. Posisjonert som både et forskningsverktøy og en praktisk anvendelse, representerer QVQ-72B en ny milepæl i utviklingen av multimodal AI.
Visuell og tekstuell resonnering
Multimodale AI-modeller som QVQ-72B er bygget for å analysere og integrere flere typer input – visuelle og tekstuelle – i en sammenhengende resonneringsprosess. Denne evnen er spesielt verdifull for oppgaver som krever tolkning av data i ulike formater, for eksempel vitenskapelig forskning, utdanning og avansert analyse.
I kjernen er QVQ-72B en utvidelse av Qwen2-VL-72B, Alibabas tidligere visjonsspråk modell. Den introduserer avanserte resonneringsfunksjoner som lar den behandle bilder og relaterte tekstmeldinger med en strukturert, logisk tilnærming. I motsetning til mange lukkede kildesystemer, er QVQ-72B designet for å være gjennomsiktig og tilgjengelig, og gi sin kildekode og modellvekter til utviklere og forskere.
“Se for deg en AI som kan se på et komplekst fysikkproblem, og metodisk resonnere seg til en løsning med tilliten til en mesterfysiker,”beskriver Qwen-teamet sine ambisjoner med den nye modellen om å utmerke seg på domener der resonnement og multimodal forståelse er avgjørende.
Ytelse og benchmarks
Modellens ytelse ble evaluert ved hjelp av flere strenge benchmarks, som hver testet forskjellige aspekter ved dens multimodale resonneringsevne:
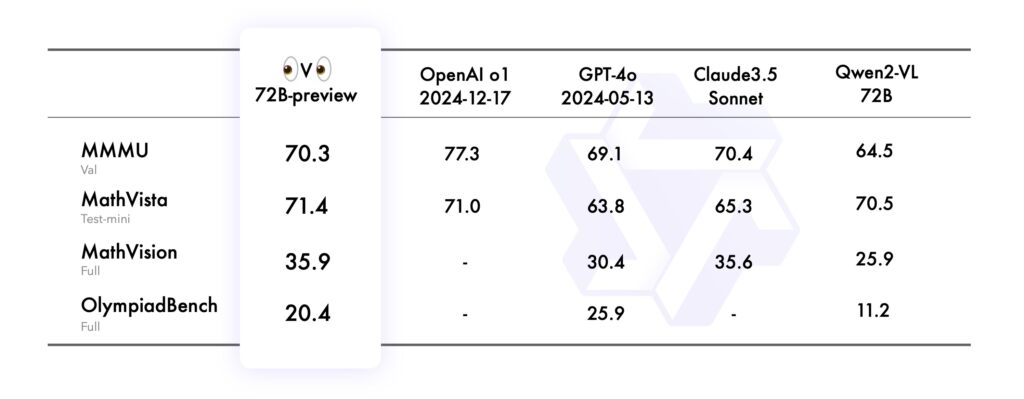
I MMMU (Multimodal Multidisciplinary University) benchmark, som vurderte dens evne til å prestere på universitetsnivå, ved å kombinere tekst og bildebasert resonnement, oppnådde QVQ-72B en imponerende poengsum på 70,3, og overgikk forgjengeren Qwen2-VL-72B-Instruct.
MathVista-referansen testet modellens ferdigheter i å løse matematiske problemer ved hjelp av grafer og visuelle hjelpemidler , og fremhever dens analytiske styrker. Tilsvarende evaluerte MathVision, avledet fra virkelige matematikkkonkurranser, sin evne til å resonnere på tvers av ulike matematiske domener.
Til slutt utfordret OlympiadBench-benchmark QVQ-72B med tospråklige problemer fra internasjonale matematikk-og fysikkkonkurranser. Modellen demonstrerte nøyaktighet som kan sammenlignes med proprietære systemer som OpenAIs GPT-4, og reduserte ytelsesgapet mellom åpen og lukket kilde-AI.
 Kilde: Qwen
Kilde: Qwen
Til tross for disse prestasjonene, gjenstår begrensningene. Qwen-teamet bemerket at rekursive resonnementløkker og hallusinasjoner under kompleks visuell analyse fortsatt er utfordringer som må løses.
Praktiske applikasjoner og utviklerverktøy
QVQ-72B er ikke bare en forskningsartefakt – det er et tilgjengelig verktøy for utviklere, vert på Hugging Face Spaces, som lar brukere eksperimentere med egenskapene i sanntid. Utviklere kan også distribuere QVQ-72B lokalt ved å bruke rammeverk som MLX, optimalisert for macOS-miljøer og Hugging Face Transformers, noe som gjør modellen allsidig på tvers av plattformer.
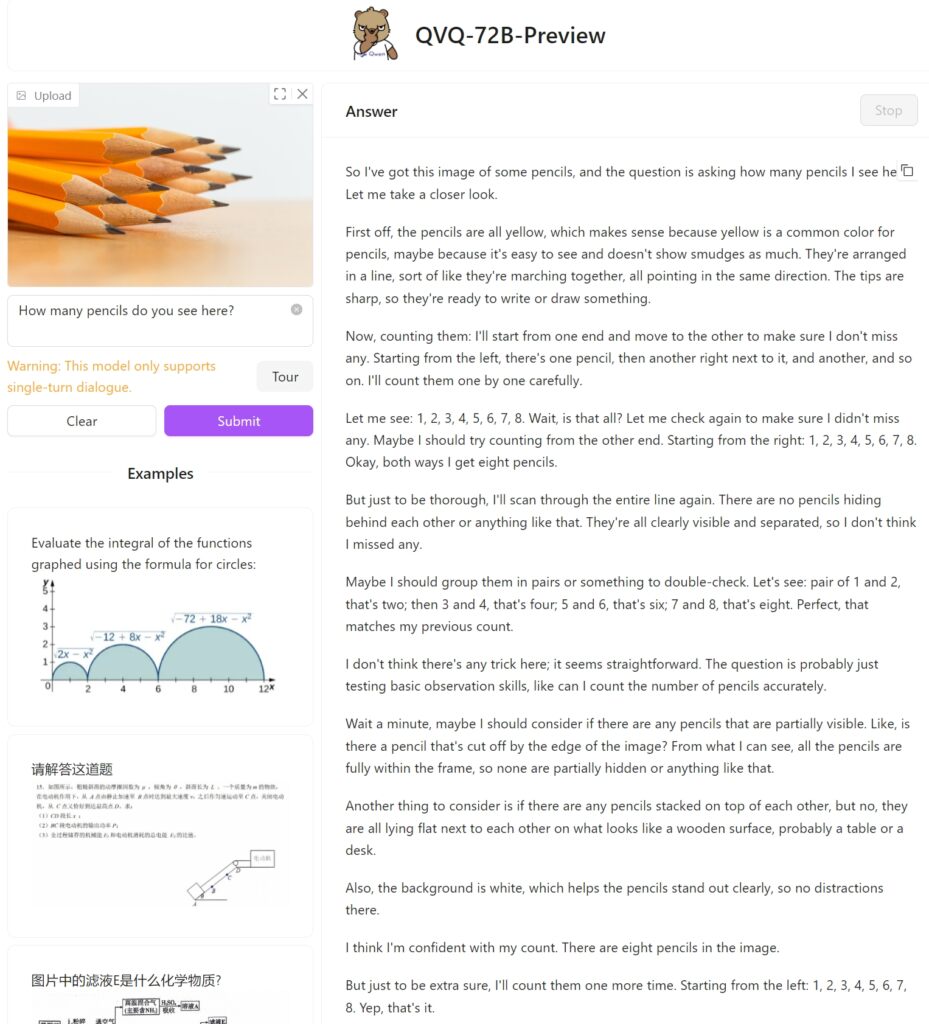
Vi testet QVQ-72B Preview på Hugging Face med et enkelt bilde av tolv blyanter for å se hvordan den vil nærme seg oppgaven og om den kan identifisere de stablede blyantene riktig. Dessverre mislyktes den med denne enkle oppgaven, og kom med bare åtte.
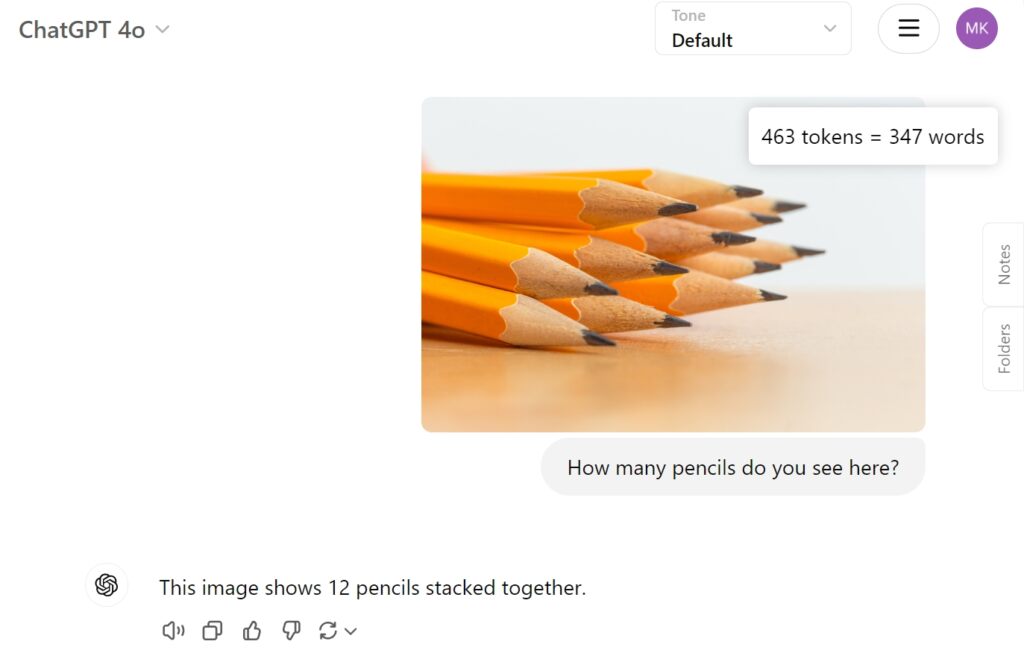
Som en sammenligning ga OpenAIs GPT-4o det riktige svaret direkte:
Ta tak i utfordringer og fremtidige retninger
Mens QVQ-72B representerer fremgang, fremhever den også kompleksiteten ved å fremme multimodal AI. Spørsmål som språkveksling, hallusinasjoner og rekursive resonnementløkker illustrerer utfordringene med å utvikle robuste, pålitelige systemer. Å identifisere separate objekter som er nøkkelen for riktig telling og påfølgende resonnement er fortsatt et problem for modellen.
Men Qwens langsiktige mål strekker seg utover QVQ-72B. Teamet ser for seg en enhetlig modell som integrerer ytterligere modaliteter – som kombinerer tekst, visjon, lyd og mer – for å nærme seg kunstig generell intelligens. De understreker at QVQ-72B er ett skritt mot denne visjonen, og gir en åpen plattform for videre utforskning og innovasjon.