OpenAI har introdusert deliberative alignment, en metodikk som tar sikte på å bygge inn sikkerhetsresonnement i selve driften av kunstige intelligenssystemer. Designet for å møte vedvarende utfordringer innen AI-sikkerhet, gjør deliberativ justering det mulig for AI-modeller å eksplisitt referere og resonnere om menneskedefinerte sikkerhetspolicyer under sanntidsinteraksjoner.
I følge OpenAI representerer tilnærmingen en stor utvikling innen AI-sikkerhetstrening, og går utover å stole på forhåndskodede datasett til systemer som dynamisk vurderer og reagerer på forespørsler med kontekstuelt informerte beslutninger.
I tradisjonelle AI-systemer implementeres sikkerhetsmekanismer under før-og ettertreningsfasene, ofte avhengig av menneskeannoterte datasett for å utlede ideell atferd.
Relatert: OpenAI avslører ny o3-modell med Drastisk forbedrede resonnementferdigheter
Disse metodene, mens grunnleggende, kan etterlate hull når modeller møter nye eller komplekse scenarier som faller utenfor treningsdataene deres. OpenAIs deliberative justering tilbyr en løsning ved å utstyre AI-systemer til å aktivt engasjere seg med sikkerhetsspesifikasjoner, og sikre at responsene er kalibrert til de etiske, juridiske og praktiske kravene til miljøet deres.
Ifølge OpenAIs forskere,”[Deliberative justering] er den første tilnærmingen for å direkte lære en modell teksten til sikkerhetsspesifikasjonene og trene modellen til å vurdere disse spesifikasjonene ved slutning tid.”
Lære AI-systemer å tenke på sikkerhet
deliberative alignment methodology involverer en to-trinns opplæringsprosess som kombinerer overvåket finjustering (SFT) og reinforcement learning (RL), støttet av syntetisk datagenerering. Denne strukturerte tilnærmingen lærer ikke bare modellerer innholdet i sikkerhetspolicyer, men trener dem også til å anvende disse retningslinjene dynamisk under driften.
I den overvåkede finjusteringsfasen (SFT) blir AI-modeller utsatt for en kurert datasett med forespørsler sammen med detaljerte svar som eksplisitt refererer til OpenAIs interne sikkerhetsspesifikasjoner.
Dissekjeden-of-thought (CoT)-eksempler illustrerer hvordan modeller bør nærme seg ulike scenarier, og bryter ned komplekse spørsmål i mindre, håndterbare trinn mens kryssrefererende sikkerhetsretningslinjer. Utdata blir deretter evaluert av et internt AI-system, ofte referert til som”dommeren”, som vurderer deres overholdelse av policystandarder.
Relatert: OpenAI-sjef Sam Altman eid og solgt Tidligere ukjent OpenAI Stake
Forsterkningslæringsfasen forbedrer modellens evner ytterligere ved å finjustere resonneringsprosessen ved å bruke tilbakemelding fra dommermodellen forbedrer iterativt sin evne til å resonnere gjennom nyanserte eller tvetydige oppfordringer, og tilpasser seg nærmere OpenAIs etiske og operasjonelle prioriteringer.
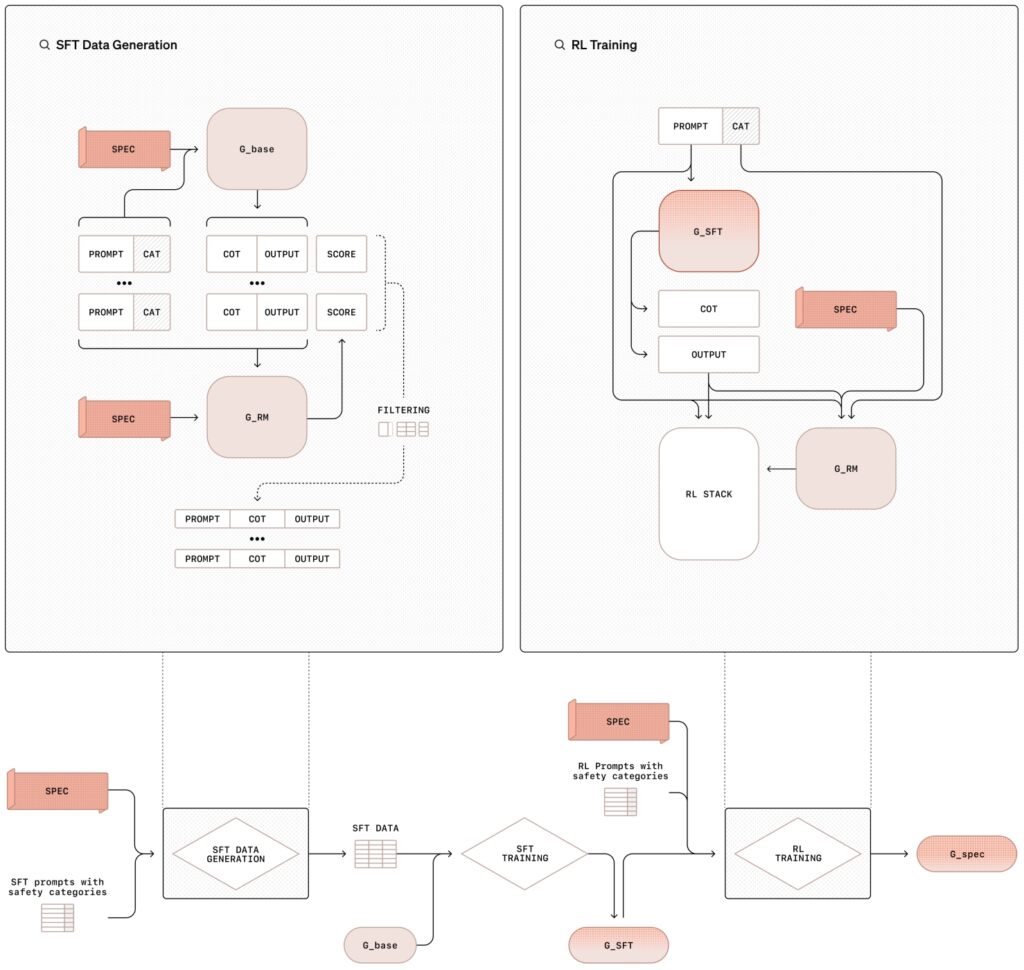 Illustrasjon av metoden for bevisst justering med overvåket finjustering (SFT) og forsterkende læring (RL). denne metodikken er bruken av syntetiske data – eksempler generert av andre AI-modeller – som erstatter behovet for menneskemerkede datasett. Dette skalerer ikke bare treningsprosessen, men sikrer også et høyt presisjonsnivå når det gjelder å tilpasse modellens atferd med sikkerhetskrav.
Illustrasjon av metoden for bevisst justering med overvåket finjustering (SFT) og forsterkende læring (RL). denne metodikken er bruken av syntetiske data – eksempler generert av andre AI-modeller – som erstatter behovet for menneskemerkede datasett. Dette skalerer ikke bare treningsprosessen, men sikrer også et høyt presisjonsnivå når det gjelder å tilpasse modellens atferd med sikkerhetskrav.
Som OpenAI-forskere bemerker:”Denne metoden oppnår svært presis spesifikasjonsoverholdelse, og er kun avhengig av modellgenererte data. Det representerer en skalerbar tilnærming til justering.”
Taking av jailbreaks og overrefusals
To av de mest vedvarende problemene innen AI-sikkerhet er modellens sårbarhet for jailbreak-forsøk og dens tendens til å overveie godartede spørsmål Jailbreaks involverer motstridende meldinger designet for å omgå sikkerhetstiltak, ofte forkledd eller kodet på måter som gjør intensjonen mindre tydelig. Forskere har nylig dokumentert hvordan selv mindre justeringer av tegnene som brukes for en prompt kan jailbreak gjeldende grensemodeller. blokker ufarlige forespørsler av en overflod av forsiktighet, frustrerer brukere og begrenser systemets nytteverdi.
Overveiende justering er spesielt utviklet for å møte disse utfordringene. Ved å utstyre modellene med evnen til å resonnere gjennom hensikten og konteksten til forespørsler, forbedrer metodikken deres evne til å motstå motstandsangrep samtidig som de opprettholder responsen på legitime spørsmål.
Relatert: AI Safety Index 2024 Resultater: OpenAI, Google, Meta, xAI Fall Short; Antropisk på toppen
Når den for eksempel blir presentert med en skjult forespørsel om å produsere skadelig innhold, kan en modell som er trent med deliberativ justering, dekode inndataene, referere til sikkerhetspolicyer og gi et begrunnet avslag.
Tilsvarende kan modellen gi nøyaktig informasjon uten å bryte sikkerhetsretningslinjene når de blir stilt et godartet spørsmål om kontroversielle emner, som historien til utviklingen av atomvåpen.
I forskningsfunnene deres, OpenAI fremhevet at modeller som er trent med deliberativ justering er i stand til å identifisere intensjonen bak kodede eller forkledde meldinger, resonnere gjennom sikkerhetspolicyene deres for å sikre samsvar.
Eksempler fra den virkelige verden på deliberativ justering i handling
OpenAI illustrerer de praktiske implikasjonene av deliberativ justering gjennom brukstilfeller i den virkelige verden. I et gitt eksempel ber en bruker et AI-system om detaljerte instruksjoner om å smi et parkeringsskilt.
Modellen identifiserer hensikten med forespørselen som uredelig, refererer til OpenAIs policy mot å tillate ulovlig aktivitet, og nekter å etterkomme. Dette svaret forhindrer ikke bare misbruk, men demonstrerer også systemets evne til å kontekstualisere og resonnere om sikkerhetspolicyer dynamisk.
I et annet scenario står modellen overfor en kodet forespørsel som ber om ulovlig råd. Ved å bruke resonneringsevnene dekoder systemet inndataene, kryssreferanser dets sikkerhetsspesifikasjoner og fastslår at spørringen bryter med OpenAIs etiske retningslinjer. Modellen gir deretter en forklaring på avslaget, og forsterker åpenheten i beslutningsprosessen.
Eksemplene fremhever evnen til deliberativ justering for å utstyre AI-systemer med verktøyene som trengs for å navigere i komplekse og etisk sensitive situasjoner, sikrer både overholdelse av retningslinjer og brukergjennomsiktighet.
Relatert: Meta oppfordrer til juridisk blokkering på OpenAIs Overgang til for-profit enhet
Utvidelse av omfanget av deliberative alignment
Deliberative alignment gjør mer enn bare å redusere risiko; det åpner også døren for at AI-systemer kan fungere med større åpenhet og ansvarlighet. Ved å gjøre det mulig for modeller å eksplisitt artikulere sine resonnementer, har OpenAI introdusert et rammeverk der brukere bedre kan forstå logikken bak en AIs svar.
Denne åpenheten er spesielt viktig i høysatsingsapplikasjoner der etiske eller juridiske hensyn er avgjørende, for eksempel helsevesen, finans og rettshåndhevelse.
For eksempel når brukere samhandler med modeller. trent under deliberativ justering, er tankekjede-resonnementet ikke bare internt, men kan deles som en del av modellens produksjon.
En bruker som søker avklaring på hvorfor en modell avviste en forespørsel, kan motta en forklaring som refererer til spesifikke sikkerhetspolicyer, sammen med en trinnvis oversikt over hvordan systemet kom frem til konklusjonen. Dette detaljnivået bygger ikke bare tillit, men oppmuntrer også til ansvarlig bruk av AI-teknologier.
OpenAI understreker at åpenhet i AI-beslutninger er avgjørende for å bygge tillit og sikre etisk bruk, med deliberativ justering som gjør det mulig for systemer å forklare tydelig oppførsel.
Relatert: Deep Dive: How OpenAIs nye o1-modell deceives Humans Strategisk
Syntetiske data: ryggraden i skalerbar AI-sikkerhet
En avgjørende komponent i deliberativ justering er bruken av syntetiske data, som erstatter tradisjonelle menneskemerkede datasett. Generering av treningsdata fra AI-systemer i stedet for å stole på menneskelige merknader gir flere fordeler, inkludert skalerbarhet, kostnadseffektivitet og presisjon.
Syntetiske data kan skreddersys for å møte spesifikke sikkerhetsutfordringer, slik at OpenAI kan lage datasett som er tett på linje med operasjonelle prioriteringer.
OpenAIs syntetiske datapipeline innebærer å generere eksempler på meldinger og tilsvarende kjede. gjennomtenkte svar ved å bruke en grunnleggende AI-modell. Disse eksemplene blir deretter gjennomgått og filtrert av”dommer”-modellen for å sikre at de oppfyller de ønskede kvalitets-og innrettingskriteriene.
Når de er godkjent, brukes dataene i de overvåkede finjusterings-og forsterkningslæringsfasene, der den trener målmodellen til å resonnere eksplisitt om sikkerhetspolicyer.
«Syntetisk datagenerering gjør det mulig for oss å skalere AI-sikkerhetstrening uten å gå på kompromiss med kvalitet eller innrettingspresisjon,» OpenAI-forskere understreket.”Denne tilnærmingen adresserer en av de viktigste flaskehalsene i tradisjonelle sikkerhetsmetodikker, som ofte er avhengige av menneskelig arbeidskraft for datakommentarer.”
Denne avhengigheten av syntetiske data sikrer også konsistens i opplæringen. Menneskelige annotatorer kan introdusere variasjon pga. til forskjeller i tolkning, men AI-genererte eksempler gir en standardisert grunnlinje nyanserte etiske dilemmaer.
Relatert: OpenAI og Anduril Forge Partnership for U.S. Military Drone Defense
Outperforming Competitors in Key Metrics
OpenAI har testet deliberativ justering mot ledende sikkerhetsstandarder. Resultatene viser at modeller trente med deliberativ justering overgår konkurrentene konsekvent, og oppnår høye poengsummer i både robusthet og respons.
O1 og relaterte modeller har blitt grundig testet mot konkurrerende systemer, inkludert GPT-4o, Gemini 1.5 Pro og Claude 3.5 Sonnet, på tvers av en rekke av sikkerhetsmålinger. På StrongREJECT, som måler en modells motstand mot kontradiktoriske jailbreaks, scoret OpenAIs o1-modeller konsekvent høyere, noe som gjenspeiler deres avanserte evne til å identifisere og blokkere skadelige meldinger.
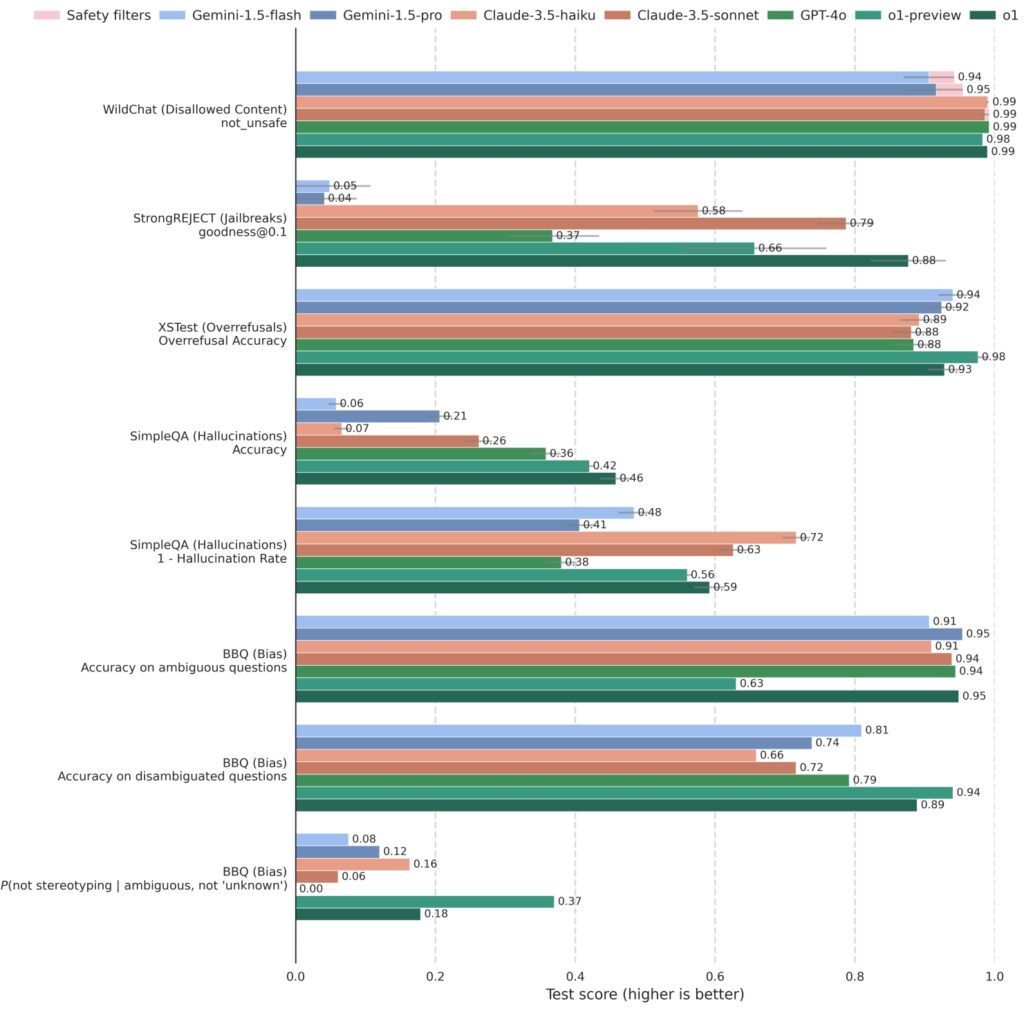 o1 er konkurransedyktig sammenlignet med andre ledende modeller på benchmarks som vurderer ikke-tillatt innhold (WildChat), jailbreaks (StrongREJECT), overavslag (XSTest), hallusinasjoner (SimpleQA) og skjevhet (BBQ). Noen API-forespørsler ble
o1 er konkurransedyktig sammenlignet med andre ledende modeller på benchmarks som vurderer ikke-tillatt innhold (WildChat), jailbreaks (StrongREJECT), overavslag (XSTest), hallusinasjoner (SimpleQA) og skjevhet (BBQ). Noen API-forespørsler ble
blokkert på grunn av innholdets sensitive natur. Disse tilfellene er registrert som «Blocked by safety filters»
på WildChat og ekskludert fra andre benchmarks. Feilstreker er estimert ved bruk av bootstrap resampling på
0,95-nivået. (Kilde: OpenAI)
O1-modellene utmerket seg i å balansere sikkerhet med reaksjonsevne. På XSTest, som evaluerer overavslag, demonstrerte modellene en redusert tendens til å avvise godartede spørsmål samtidig som de opprettholder streng overholdelse av sikkerhetsretningslinjene forbli nyttig og tilgjengelig uten å gå på akkord med etiske standarder.
OpenAI sier at deliberative justering forbedrer AI-sikkerheten ved å redusere skadelige utdata samtidig som den øker nøyaktigheten i å reagere på godartede interaksjoner.
Relatert: Hvordan å trykke på”Stopp”i ChatGPT kan nøytralisere sine sikkerhetstiltak
Større implikasjoner for AI-utvikling
Innføringen av deliberativ justering markerer et vendepunkt i hvordan AI-systemer trenes og distribueres hos OpenAI og sannsynligvis også av andre i fremtiden.
Ved å bygge inn eksplisitte sikkerhetsresonnementer i kjernefunksjonaliteten til modellene, har OpenAI skapt et rammeverk som ikke bare adresserer eksisterende utfordringer, men også forutser fremtidige risikoer. Etter hvert som AI-systemer blir mer kapable, øker potensialet for misbruk eller utilsiktede konsekvenser, noe som gjør robuste sikkerhetstiltak mer kritiske enn noen gang.
Overveiende justering fungerer også som en modell for det bredere AI-fellesskapet. Dens avhengighet av skalerbare teknikker som syntetiske data og dens vektlegging av åpenhet gir en blåkopi for andre organisasjoner som ønsker å tilpasse sine AI-systemer med etiske og samfunnsmessige verdier.