Google DeepMind har lansert FACTS Grounding, en ny benchmark utviklet for å teste store språkmodeller (LLMs) på deres evne til å generere faktisk nøyaktige, dokumentbaserte svar.
Referansemålet, vert på Kaggle, har som mål å takle en av de mest presserende utfordringene i kunstig intelligens: å sikre at AI-utdata er basert på dataene de får, i stedet for å stole på ekstern kunnskap eller introdusere hallusinasjoner – plausibel, men likevel feil informasjon.
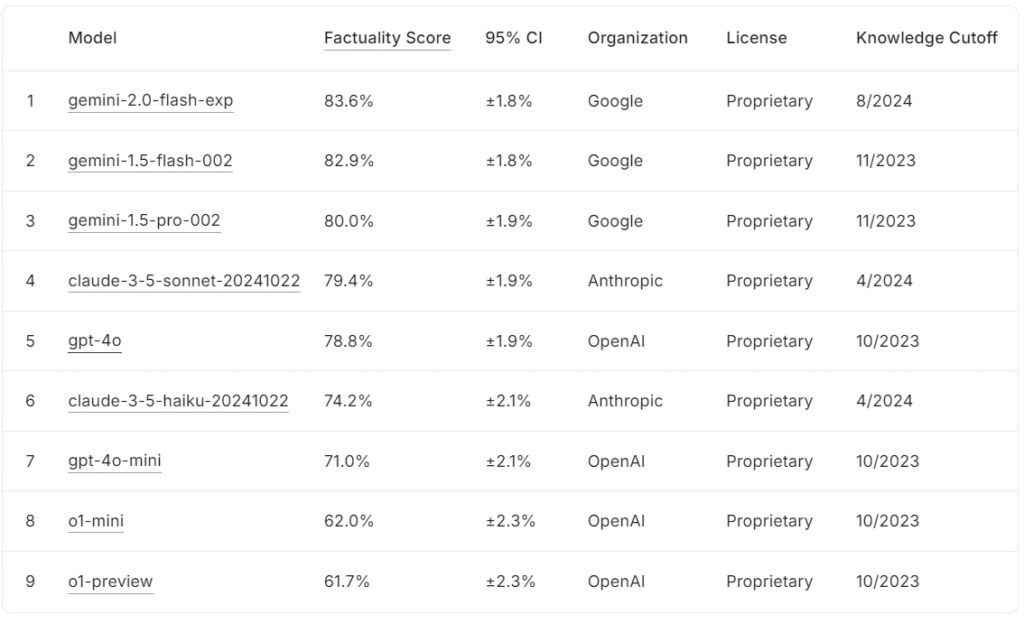
Den nåværende FACTS Grounding leaderboard rangerer store språkmodeller basert på deres faktapoeng, med Googles gemini-2.0-flash-exp leder med 83,6 % fulgt tett av gemini-1.5-flash-002 på 82,9 %, og gemini-1,5-pro-002 på 80,0 %.
Antropic’s claude-3.5-sonnet-220000 rangerer fjerde med 79,4 %, mens OpenAIs gpt-4o oppnår 78,8 %, og plasserer den på femteplass. Nederst på listen scorer Anthropics claude-3.5-haiku-20241022 74,2 %, etterfulgt av gpt-4o-mini med 71,0 %.
OpenAIs mindre modeller, o1-mini og o1-preview, avrunder ledertavlen med 62,0 % og >61,7 %, henholdsvis.
 Kilde: Kaggle
Kilde: Kaggle
FAKTA Jording skiller seg ut ved å kreve langformede svar som syntetiserer detaljerte inndatadokumenter, noe som gjør det til en av de mest strenge referansene for AI-fakta til dags dato.
FAKTA Jording representerer en kritisk utvikling for AI-industrien, spesielt i applikasjoner der tillit og nøyaktighet er avgjørende. Ved å evaluere LLM-er på tvers av domener som medisin, juss, finans, detaljhandel og teknologi, setter benchmarken scenen for forbedret AI-pålitelighet i virkelige scenarier.
I følge DeepMinds forskerteam måler”benchmark LLMs evne til å generere svar utelukkende basert på den angitte konteksten… selv når konteksten er i konflikt med kunnskap før trening.”
Datasett for kompleksitet i den virkelige verden
FAKTA Grounding består av 1719 eksempler, kuratert av menneskelige annotatorer til sikre relevans og mangfold Disse eksemplene er hentet fra detaljerte dokumenter som spenner over opptil 32 000 tokens, tilsvarende ca. 20 000 ord. å referere kun til de oppgitte dataene. Referansemerket unngår oppgaver som krever kreativitet, matematisk resonnement eller eksperttolkning. fokuserer i stedet på å teste en modells evne til å syntetisere og artikulere kompleks informasjon.
For å opprettholde åpenhet og forhindre overtilpasning, delte DeepMind datasettet i to segmenter: 860 offentlige eksempler tilgjengelig for ekstern bruk og 859 private eksempler reservert for leaderboard evalueringer.
Denne doble strukturen ivaretar integriteten til referansen samtidig som den oppmuntrer til samarbeid fra AI-utviklere over hele verden.”Vi evaluerer våre automatiske evaluatorer nøye på testdata som holdes ut for å validere ytelsen deres i oppgaven vår,”bemerker forskerteamet, og fremhever den nøye utformingen som ligger til grunn for FACTS Grounding.
Bedømme nøyaktighet med Peer AI-modeller
I motsetning til konvensjonelle benchmarks, bruker FACTS Grounding en fagfellevurderingsprosess som involverer tre avanserte LLM-er: Gemini 1.5 Pro, GPT-4o og Claude 3.5 Sonnet. Disse modellene fungerer som dommere, og scorer svar basert på to kritiske kriterier: kvalifisering og faktisk nøyaktighet bekrefter at de adresserer brukerens forespørsel på en meningsfylt måte. De som kvalifiserer blir deretter vurdert for deres forankring i kildematerialet, med poengsummene samlet på tvers av de tre modeller for å minimere skjevhet.
DeepMinds forskere understreker viktigheten av denne flerlags-evalueringen, og sier:”Beregninger som er fokusert på å evaluere fakta i den genererte teksten… kan omgås ved å ignorere intensjonen bak brukeren forespørsel. Ved å gi kortere svar som unngår å formidle omfattende informasjon… er det mulig å oppnå en høy faktapoengsum uten å gi et nyttig svar.”
Bruk av flere scoringsmaler, inkludert span-nivå og JSON-baserte tilnærminger , sikrer videre tilpasning til menneskelig dømmekraft og tilpasningsevne til ulike oppgaver.
Tackling the Challenge of AI Hallusinasjoner
AI-hallusinasjoner er blant de viktigste hindringene for utbredt bruk av LLM-er på kritiske felt. Disse feilene, der modeller genererer utdata som virker plausible, men som er faktisk feil, utgjør en alvorlig risiko på områder som f.eks. som helsetjenester, juridiske analyser og finansiell rapportering
FAKTA Jording tar direkte opp dette problemet ved å håndheve streng overholdelse av levert inndata. Denne tilnærmingen evaluerer ikke bare en modells evne til å unngå å introdusere usannheter, men sikrer også at utdataene forblir på linje med brukerens intensjoner.
I motsetning til benchmarks som OpenAIs SimpleQA, som måler fakta i treningsdatainnhenting. , FAKTA Jording tester hvor godt modeller syntetiserer ny informasjon.
Forskningsartikkelen understreker denne forskjellen: «Å sikre faktisk nøyaktighet mens du genererer LLM-svar er utfordrende. De viktigste utfordringene i LLM-fakta er modellering (dvs. arkitektur, opplæring og inferens) og måling (dvs. evalueringsmetodikk, data og beregninger).”
Tekniske utfordringer og benchmarkdesign >
Kompleksiteten til langformede input introduserer unike tekniske utfordringer, spesielt ved utforming av automatiserte evalueringsmetoder som nøyaktig kan vurdere slike svar
FAKTA Jording er avhengig av beregningsintensive prosesser for å validere svar, ved å bruke strenge kriterier for å sikre pålitelighet. Inkluderingen av flere dommermodeller reduserer potensielle skjevheter og styrker det overordnede evalueringsrammeverket. Forskerteamet fremhever viktigheten av å diskvalifisere vage eller irrelevante svar, og bemerker:”Å diskvalifisere ikke kvalifisert svar fører til en reduksjon… da disse svarene blir behandlet som unøyaktige.”Denne strenge håndhevelsen av relevans sikrer at modeller ikke blir belønnet for å omgå ånden i oppgaven.
Oppmuntring til samarbeid gjennom åpenhet
DeepMinds beslutning om å være vertskap for FAKTA Grounding on Kaggle gjenspeiler deres forpliktelse til å fremme samarbeid på tvers av AI-industrien. Ved å gjøre det offentlige segmentet av datasettet tilgjengelig, inviterer prosjektet AI-forskere og-utviklere til å evaluere modellene sine mot en robust standard og bidra til å fremme faktareferanser.
Denne tilnærmingen er i tråd med de bredere målene for åpenhet og delt fremgang i AI, og sikrer at forbedringer i nøyaktighet og jording ikke er begrenset til én enkelt organisasjon.
Differensiere fra andre Benchmarks
FAKTA Jording skiller seg fra andre benchmarks ved sitt fokus på jording i nylig introduserte innganger snarere enn ferdigtrent kunnskap.
Mens benchmarks som OpenAIs SimpleQA vurderer hvor godt en modell henter og bruker informasjon fra treningskorpuset, evaluerer FACTS Grounding modeller for deres evne til å syntetisere og artikulere svar utelukkende basert på leverte data.
Denne distinksjonen er avgjørende for å møte utfordringer fra modellforutsetninger eller iboende skjevheter. Ved å isolere oppgaven med å behandle eksterne input, sikrer FACTS Grounding at ytelsesmålinger reflekterer en modells evne til å operere i dynamiske scenarier i den virkelige verden i stedet for bare å gjenoppta forhåndslært informasjon.
Som DeepMind forklarer i sin forskningsartikkel, er referanseindeksen utformet for å evaluere LLM-er på deres evne til å administrere komplekse, langformede søk med faktagrunnlag, og simulere oppgaver som er relevante for applikasjoner i den virkelige verden.
Alternative metoder for jording av LLM-er
Flere metoder tilbyr lignende jordingsfunksjoner som FACTS-jording, hver med dens styrker og svakheter. Disse metodene tar sikte på å forbedre LLM-utdata ved enten å forbedre deres tilgang til nøyaktig informasjon eller avgrense opplærings-og innrettingsprosessene.
Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) forbedrer nøyaktigheten til LLM utdata ved dynamisk å hente relevant informasjon fra eksterne kunnskapsbaser eller databaser og inkorporere den i modellens svar. I stedet for å omskolere hele LLM, fungerer RAG ved å avskjære brukerforespørsler og berike dem med oppdatert informasjon.
Avanserte RAG-implementeringer utnytter ofte enhetsbasert henting, der data knyttet til spesifikke enheter forenes til gi svært relevant kontekst for LLM-svar.
RAG bruker vanligvis semantiske søketeknikker for å hente informasjon. Dokumenter eller fragmentene deres indekseres basert på deres semantiske innebygginger, slik at systemet kan matche brukerens spørring med de mest kontekstuelt relevante oppføringene. Denne tilnærmingen sikrer at LLM-er genererer svar informert av de nyeste og mest relevante dataene.
RAGs effektivitet avhenger sterkt av kvaliteten og organiseringen av kunnskapsbasen, samt presisjonen til gjenfinningsalgoritmene. Mens FACTS Grounding evaluerer en LLMs evne til å forbli forankret til et gitt kontekstdokument, utfyller RAG dette ved å gjøre det mulig for LLM-er å utvide kunnskapen sin dynamisk, ved å trekke fra eksterne kilder for å forbedre fakta og relevans.
Kunnskapsdestillasjon.
Kunnskapsdestillasjon innebærer å overføre egenskapene til en stor, kompleks modell (referert til som læreren) til en mindre, oppgavespesifikk modell ( studenten). Denne metoden forbedrer effektiviteten samtidig som den beholder mye av nøyaktigheten til den originale modellen. To primære tilnærminger brukes i kunnskapsdestillasjon:
Responsbasert kunnskapsdestillasjon: Fokuserer på å replikere utdataene fra lærermodellen, og sikre at elevmodellen gir lignende resultater for gitte input.
Funksjonsbasert kunnskapsdestillasjon: Trekker ut interne representasjoner og funksjoner fra lærermodellen, slik at elevmodellen kan replikere dypere innsikt.
Ved å foredle mindre modeller, muliggjør kunnskapsdestillasjon distribusjon av LLM-er i ressursbegrensede miljøer uten betydelige tap i ytelse. I motsetning til FACTS Grounding, som evaluerer jordingstrohet, er kunnskapsdestillasjon mer opptatt av å skalere LLM-evner og optimalisere dem for spesifikke oppgaver.
Finjustering med jordede datasett
Finjustering innebærer å tilpasse forhåndstrente LLM-er til spesifikke domener eller oppgaver ved å trene dem på kuraterte datasett med faktagrunnlag er kritisk. For eksempel kan datasett som består av vitenskapelig litteratur eller historiske poster brukes til å forbedre modellens evne til å produsere nøyaktige og domenespesifikke utdata. Denne teknikken forbedrer LLM-ytelsen for spesialiserte applikasjoner, for eksempel medisinsk eller juridisk dokumentanalyse.
Finjustering er imidlertid ressurskrevende og risikerer katastrofal glemsel, der modellen mister kunnskap oppnådd under den første opplæringen. FAKTA Grounding fokuserer på å teste fakta i isolerte sammenhenger, mens finjustering søker å forbedre baseline-ytelsen til LLM-er på spesifikke områder.
Reinforcement Learning with Human Feedback (RLHF)
Forsterkning Learning with Human Feedback (RLHF) inkorporerer menneskelige preferanser i opplæringsprosessen til LLM-er. Ved å iterativt trene modellen til å tilpasse svarene med menneskelig tilbakemelding, foredler RLHF kvaliteten, fakta og nytten av utdata. Menneskelige evaluatorer skårer LLMs resultater, og disse skårene brukes som signaler for å optimalisere modellen.
RLHF har vært spesielt vellykket i å øke brukertilfredsheten og sikre at de genererte svarene er i samsvar med menneskelige forventninger. Mens FACTS Grounding vurderer faktagrunnlaget mot spesifikke dokumenter, legger RLHF vekt på å samkjøre LLM-utdata med menneskelige verdier og preferanser.
Instruksjonsfølging og In-Context Learning
Instruksjonsfølgende og kontekstbasert læring innebærer demonstrere jording til LLM-er gjennom nøye utformede eksempler i brukerprompten. Disse metodene er avhengige av modellens evne til å generalisere fra en demonstrasjon med få skudd. Selv om denne tilnærmingen kan gi raske forbedringer, oppnår den kanskje ikke samme nivå av jordingskvalitet som finjustering eller gjenfinningsbaserte metoder.
Eksterne verktøy og APIer
LLM-er kan integreres med eksterne verktøy og API-er for å gi sanntidstilgang til eksterne data, noe som forbedrer deres jordingsevne betydelig. Eksempler inkluderer:
Nettleserevne: Gjør det mulig for LLM-er å få tilgang til og hente sanntidsinformasjon fra nettet for å svare på spesifikke spørsmål eller oppdatere kunnskapen deres.
API-anrop: Lar LLM-er samhandle med strukturerte databaser eller tjenester, og beriker svar med presis og oppdatert informasjon.
Disse verktøyene utvider nytten av LLM-er ved å koble dem til virkelige kunnskapskilder, forbedre deres evne til å generere nøyaktige og jordede utdata. Mens FACTS Grounding evaluerer intern jording, gir eksterne verktøy et alternativt middel for å utvide og verifisere fakta.
Åpen kildekode modelljording Alternativer
Flere åpen kildekode-implementeringer er tilgjengelige for de alternative jordingsmetodene diskutert ovenfor:
Betydningen av nøyaktig og funderte AI-responser blir spesielt tydelige i høyinnsatsapplikasjoner, for eksempel medisinsk diagnostikk, juridiske vurderinger og økonomisk analyse. I disse sammenhengene kan selv mindre unøyaktigheter føre til betydelige konsekvenser, noe som gjør påliteligheten til AI-genererte utdata til et ikke-omsettelig krav. FAKTA Groundings vektlegging av fakta og overholdelse av kildemateriale sikrer at modellene testes under forhold som tett gjenspeiler kravene fra den virkelige verden. For eksempel, i medisinske sammenhenger, har en LLM i oppgave å oppsummering av pasientjournaler må unngå å introdusere feil som kan feilinformere behandlingsbeslutninger. På samme måte, i juridiske omgivelser, krever det å generere sammendrag eller analyser av rettspraksis presis forankring i de oppgitte dokumentene. FAKTA Grounding evaluerer ikke bare modeller på deres evne til å møte disse strenge kravene, men etablerer også en målestokk for utviklere å sikte på for å lage systemer som egner seg for slike applikasjoner. DeepMind har posisjonert FACTS Grounding som en”levende benchmark”, en som vil Utvikle seg sammen med fremskritt innen AI. Fremtidige oppdateringer vil sannsynligvis utvide datasettet til å inkludere nye domener og oppgavetyper, og sikre at det fortsatt er relevant etter hvert som LLM-kapasiteten vokser robustheten til scoringsprosessen, adressering av kantsaker og redusere gjenværende skjevheter. Som DeepMinds forskerteam erkjenner at ingen benchmark fullt ut kan innkapsle kompleksiteten til virkelige applikasjoner. Men ved å iterere på FAKTA-jording og engasjere det bredere AI-fellesskapet, har prosjektet som mål å heve standarden for fakta og forankring i AI-systemer. Som DeepMinds team sier,”Faktualitet og jording er blant nøkkelfaktorene som vil forme fremtidig suksess og nytte av LLM-er og bredere AI-systemer, og vi tar sikte på å vokse og gjenta FAKTA Jording etter hvert som feltet skrider frem, kontinuerlig heve listen.”Implikasjoner for høyinnsatsapplikasjoner
Utvider FAKTA-datasettet og fremtidige retninger