Forskere ved Sakana AI, en Tokyo-basert AI-oppstart, har introdusert et nytt minneoptimaliseringssystem som forbedrer effektiviteten til transformatorbaserte modeller, inkludert store språkmodeller (LLM).
Metoden, kalt Neural Attention Memory Models (NAMMs) tilgjengelig via full treningskode på GitHub, reduserer minnebruken med opptil 75 % og forbedrer den generelle ytelsen. Ved å fokusere på viktige tokens og fjerne overflødig informasjon, adresserer NAMM-er en av de mest ressurskrevende utfordringene i moderne AI: administrere lange kontekstvinduer.
Transformatormodeller, ryggraden i LLM-er, er avhengige av”kontekstvinduer”for å behandle inngangsdata Disse kontekstvinduene lagrer”nøkkelverdi-par”(KV-cache) for hver token i inndatasekvensen.
Når vinduslengden vokser – nå hundretusenvis av tokens – beregningskostnadene skyter i været. Tidligere løsninger forsøkte å redusere denne kostnaden gjennom manuell tokenbeskjæring eller heuristiske strategier, men ofte redusert ytelse. NAMM-er bruker imidlertid nevrale nettverk trent gjennom evolusjonær optimalisering for å automatisere og avgrense minnebehandlingsprosessen.
Minneoptimalisering med NAMM-er
NAMM-er analyserer oppmerksomhetsverdiene generert av Transformers for å bestemme symbolsk betydning. De behandler disse verdiene til spektrogrammer-frekvensbaserte representasjoner som vanligvis brukes i lyd-og signalbehandling-for å komprimere og trekke ut nøkkeltrekk ved oppmerksomhetsmønstrene.
Denne informasjonen sendes deretter gjennom et lett nevralt nettverk som tildeler en poengsum til hvert token, og bestemmer om det skal beholdes eller forkastes.
Sakana AI fremhever hvordan evolusjonære algoritmer driver NAMM-er. suksess. I motsetning til tradisjonelle gradientbaserte metoder, som er inkompatible med binære beslutninger som”husk”eller”glem”, tester og foredler evolusjonsoptimalisering iterativt minnestrategier for å maksimere nedstrømsytelsen.
“Evolusjon overvinner iboende ikke-differensierbarheten. av våre minnehåndteringsoperasjoner, som involverer binære”husk”eller”glem”utfall,”forklarer forskerne.
Prøvde resultater på tvers av benchmarks
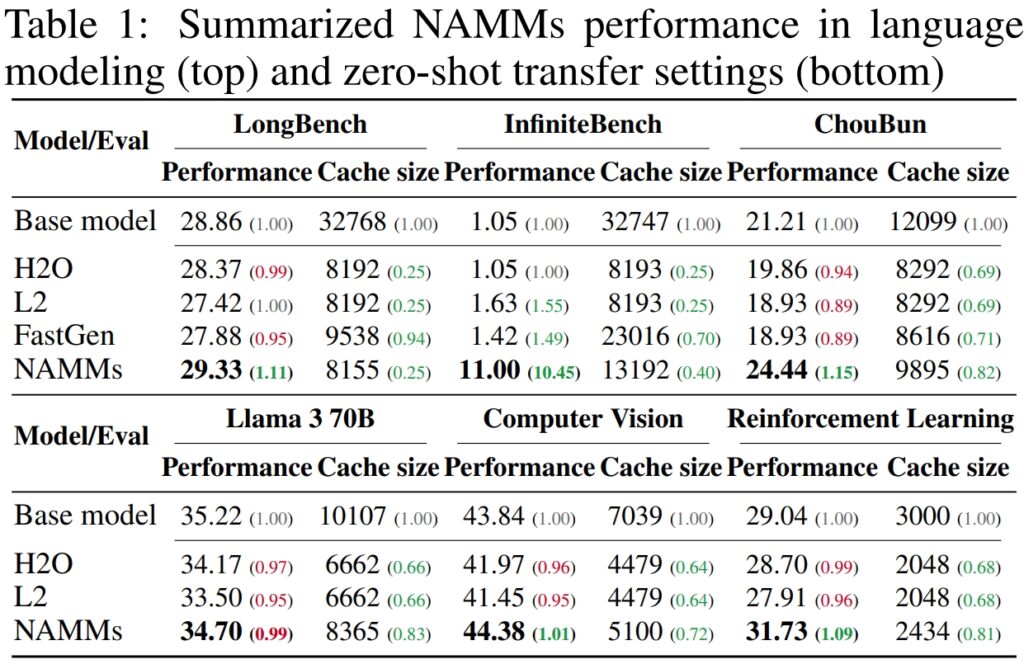
For å validere ytelsen og effektiviteten til Neural Attention Memory Models (NAMMs), gjennomførte Sakana AI omfattende tester på flere bransjeledende benchmarks designet for å vurdere langkontekstbehandling og multi-task evner. Resultatene understreket NAMMs evne til å forbedre ytelsen betydelig samtidig som de reduserer minnekravene, og beviser deres effektivitet på tvers. diverse evalueringsrammeverk.
Ved å beskjære mindre relevante tokens på en intelligent måte, tillot NAMM-er modellen å fokusere på kritisk kontekst uten å ofre resultater, noe som gjør den ideell for scenarier som krever utvidede input, for eksempel dokumentanalyse eller langformede spørsmålssvar.
p>
For InfiniteBench, en benchmark som presser modellene til sine grenser med ekstremt lange sekvenser—noen overstiger 200 000 tokens—NAMM-er demonstrerte sin evne til å skalere effektivt.
Mens grunnlinjemodeller slet med beregningskravene til slike lange inndata, oppnådde NAMM-er en dramatisk ytelsesøkning, og økte nøyaktigheten fra 1,05 % til 11,00 %.
Dette resultatet er spesielt bemerkelsesverdig fordi det viser NAMMs kapasitet til å håndtere ultralange kontekster, en evne som er stadig viktigere for applikasjoner som behandling av vitenskapelig litteratur, juridiske dokumenter eller store kodelagre der tokeninndatastørrelser er enorme.
På Sakana AIs egen ChouBun benchmark, som evaluerer langkontekstresonnement for japanskspråklige oppgaver, leverte NAMM-er en forbedring på 15 % i forhold til grunnlinjen. ChouBun adresserer et gap i eksisterende benchmarks, som har en tendens til å fokusere på engelsk og kinesisk språk, ved å teste modeller på utvidede japanske tekstinndata.
Suksessen til NAMM-er på ChouBun fremhever deres allsidighet på tvers av språk og beviser deres robusthet når det gjelder håndtering av ikke-engelske input – en nøkkelfunksjon for globale AI-applikasjoner. NAMM-er var i stand til effektivt å beholde kontekstspesifikt innhold samtidig som de forkastet grammatiske redundanser og mindre meningsfulle tokens, noe som gjorde at modellen kunne utføre mer effektivt på oppgaver som langformig oppsummering og forståelse på japansk.
 Kilde: Sakana AI
Kilde: Sakana AI
The resultater demonstrerer samlet at NAMM-er utmerker seg ved å optimalisere minnebruk uten å gå på akkord med nøyaktigheten. Enten de evalueres på oppgaver som krever ekstremt lange sekvenser eller på tvers av ikke-engelskspråklige kontekster, overgår NAMM-er konsekvent grunnlinjemodeller, og oppnår både beregningseffektivitet og forbedrede resultater.
Denne kombinasjonen av minnebesparelser og nøyaktighet posisjonerer NAMM-er som et stort fremskritt for AI-systemer for bedrifter som har til oppgave å håndtere store og komplekse input.
Resultatene er spesielt bemerkelsesverdige sammenlignet med tidligere metoder som f.eks. H₂O og L2, som ofret ytelse for effektivitet. NAMM-er, derimot, oppnår begge deler.
“Våre resultater viser at NAMM-er gir konsistente forbedringer på tvers av både ytelses-og effektivitetsakser i forhold til baseline-transformatorer,”fastslår forskerne.
Cross-Modal Applications: Beyond Language
Et av de mest imponerende funnene var NAMMs evne til å overføre nullskudd til andre oppgaver og inndatamodaliteter
Et av de mest bemerkelsesverdige aspektene ved Neural Attention Memory Models (NAMM) er deres evne til å overføre sømløst på tvers av forskjellige oppgaver og inndatamodaliteter – utover tradisjonelle språkbaserte applikasjoner
I motsetning til andre minneoptimaliseringsmetoder, som ofte krever omskolering eller finjustering for hvert domene, opprettholder NAMM-er effektiviteten og ytelsesfordelene uten ekstra justeringer. Sakana AIs eksperimenter viste frem denne allsidigheten i to nøkkeldomener: datasyn og forsterkende læring, som begge gir unike utfordringer for transformatorbaserte modeller.
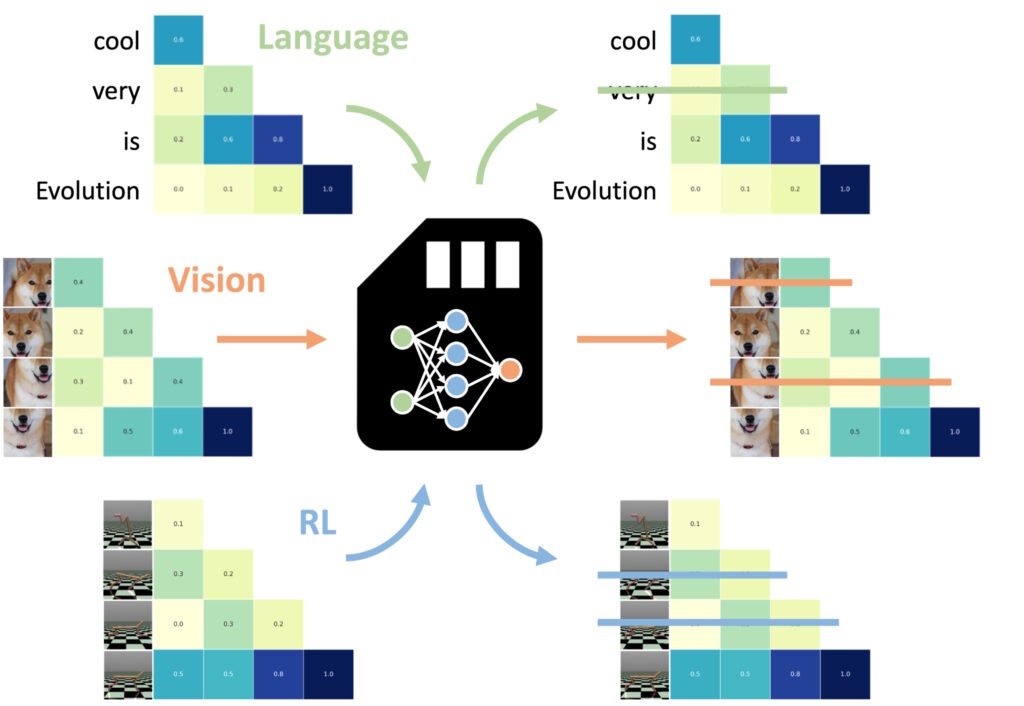 NAMM-er trent på språk kan være null-skudd overført til andre transformatorer på tvers av inputmodaliteter og oppgavedomener. (Bilde: Sakana AI)
NAMM-er trent på språk kan være null-skudd overført til andre transformatorer på tvers av inputmodaliteter og oppgavedomener. (Bilde: Sakana AI)
I datasyn ble NAMM-er evaluert ved å bruke Llava Next Video-modellen, en Transformator designet for behandling av lange videosekvenser. Videoer inneholder iboende store mengder redundante data, for eksempel gjentatte bilder eller mindre variasjoner som gir lite tilleggsinformasjon.
NAMM-er identifiserte og forkastet automatisk disse redundante rammene under inferens, og komprimerte effektivt kontekstvinduet uten å kompromittere modellens evne til å tolke videoinnholdet.
For eksempel beholdt NAMM-er rammer med viktige visuelle detaljer – som handlingsendringer, objektinteraksjoner eller kritiske hendelser – mens de fjernet repeterende eller statiske rammer. Dette resulterte i forbedret prosesseringseffektivitet, slik at modellen kunne fokusere på de mest relevante visuelle elementene, og dermed opprettholde nøyaktigheten og samtidig redusere beregningskostnadene.
I forsterkende læring ble NAMM-er brukt på Decision Transformer, en modell designet for å behandle sekvenser av handlinger, observasjoner og belønninger for å optimalisere beslutningsoppgaver. Forsterkende læringsoppgaver involverer ofte lange sekvenser av input med varierende grad av relevans, der suboptimale eller overflødige handlinger kan hindre ytelse.
NAMM-er tok tak i denne utfordringen ved å selektivt fjerne tokens som tilsvarer ineffektive handlinger og informasjon av lav verdi, samtidig som de beholdt de som var avgjørende for å oppnå bedre resultater.
For eksempel i oppgaver som Hopper og >Walker2d—som involverer å kontrollere virtuelle agenter i kontinuerlig bevegelse—NAMM-er forbedret ytelsen med over 9 %. Ved å filtrere ut suboptimale bevegelser eller unødvendige detaljer, oppnådde Decision Transformer mer effektiv og effektiv læring, og fokuserte sin beregningskraft på beslutninger som maksimerte suksess i oppgaven.
Disse resultatene fremhever NAMMs tilpasningsevne på tvers av vidt forskjellige domener. Enten de behandler videorammer i visjonsmodeller eller optimaliserer handlingssekvenser i forsterkende læring, demonstrerte NAMM-er sin evne til å forbedre ytelsen, redusere ressursbruk og opprettholde modellnøyaktighet – alt uten omskolering.
NAMM-er lærer å glemme nesten utelukkende deler av overflødige videorammer, i stedet for språksymbolene som beskriver den endelige oppfordringen, papirnotatene, som fremhever tilpasningsevnen til NAMM-er.
Teknisk grunnlag for NAMM-er
Effektiviteten og effektiviteten til Neural Attention Memory Models (NAMM-er) ligger i deres strømlinjeformede og systematiske utførelsesprosess, som muliggjør presis symbolbeskjæring uten manuell inngripen. Denne prosessen er bygget på tre kjernekomponenter: oppmerksomhetsspektrogrammer, funksjonskomprimering og automatisert scoring.
NAMM-er justerer oppførselen dynamisk avhengig av oppgavekrav og transformatorlagdybde. Tidlige lag prioriterer”global”kontekst som oppgavebeskrivelser, mens dypere lag beholder”lokale”oppgavespesifikke detaljer. I kodeoppgaver, for eksempel, forkastet NAMM-er kommentarer og standardkode; i naturlige språkoppgaver eliminerte de grammatiske redundanser samtidig som de beholdt nøkkelinnhold.
Denne adaptive token-oppbevaringen sikrer at modellene forblir fokusert på relevant informasjon gjennom behandlingen, og forbedrer hastigheten og nøyaktigheten.
Den første trinnet innebærer å generere oppmerksomhetsspektrogrammer. Transformatorer beregner”oppmerksomhetsverdier”på hvert lag for å bestemme den relative betydningen av hvert token i kontekstvinduet. NAMM-er transformerer disse oppmerksomhetsverdiene til frekvensbaserte representasjoner ved hjelp av Short-Time Fourier Transform (STFT)
STFT er en mye brukt signalbehandlingsteknikk som bryter ned en sekvens i lokaliserte frekvenskomponenter over tid, og gir en kompakt, men detaljert representasjon av symbolsk betydning konverter rå oppmerksomhetssekvenser til spektrogramlignende data, noe som muliggjør en klarere analyse av hvilke tokens som bidrar meningsfullt til modellens produksjon.
Neste, Funksjon Komprimeringbrukes for å redusere dimensjonaliteten til spektrogramdataene og samtidig bevare dens essensielle egenskaper. Dette oppnås ved hjelp av et eksponentielt glidende gjennomsnitt (EMA), en matematisk metode som komprimerer historiske oppmerksomhetsmønstre til et kompakt sammendrag med fast størrelse. EMA sikrer at representasjonene forblir lette og håndterbare, slik at NAMM-er kan analysere lange oppmerksomhetssekvenser effektivt samtidig som de minimerer beregningsmessige overhead.
Det siste trinnet er Skåring og beskjæring, der NAMM-er bruker en lettvekt. nevrale nettverksklassifiserer for å evaluere de komprimerte tokenrepresentasjonene og tildele poeng basert på deres betydning. Tokens med poeng under en definert terskel beskjæres fra kontekstvinduet, og”glemmer”effektivt unyttige eller overflødige detaljer. Denne poengmekanismen gjør det mulig for NAMM-er å prioritere kritiske tokens som bidrar til modellens beslutningsprosess samtidig som mindre relevante data forkastes.
Det som gjør NAMM-er spesielt effektive, er deres avhengighet av evolusjonær optimalisering for å avgrense denne prosessen optimeringsmetoder som gradientnedstigning sliter med ikke-differensierbare oppgaver – for eksempel å bestemme om et token skal beholdes eller forkastes
I stedet bruker NAMM-er en iterativ evolusjonsalgoritme, inspirert av naturlig utvalg, for å”mutere”og.”velg”de mest effektive minneadministrasjonsstrategiene over tid. Gjennom gjentatte forsøk utvikler systemet seg til å prioritere viktige tokens automatisk, og oppnår en balanse mellom ytelse og minneeffektivitet uten å kreve manuell finjustering.
Denne strømlinjeformede utførelsen – som kombinerer spektrogrambasert tokenanalyse, effektiv komprimering og automatisert beskjæring – lar NAMM-er levere både betydelig minne besparelser og ytelsesgevinster på tvers av ulike transformatorbaserte oppgaver. Ved å redusere beregningskravene samtidig som de opprettholder eller forbedrer nøyaktigheten, setter NAMM-er en ny standard for effektiv minneadministrasjon i moderne AI-modeller.
Hva kommer videre for transformatorer?
Sakana AI mener NAMM-er bare er begynnelsen. Mens nåværende arbeid fokuserer på å optimalisere forhåndstrente modeller ved slutning, kan fremtidig forskning integrere NAMM-er i selve treningsprosessen. Dette kan gjøre det mulig for modeller å lære hukommelseshåndteringsstrategier på egen hånd, og utvide lengden på kontekstvinduer ytterligere og øke effektiviteten på tvers av domener.
“Dette arbeidet har bare begynt å utforske designområdet til minnemodellene våre, som vi forventer kan tilby mange nye muligheter for å fremme fremtidige generasjoner av transformatorer,”konkluderer teamet.
NAMMs beviste evne til å skalere ytelse, redusere kostnader og tilpasse seg på tvers av modaliteter setter en ny standard for effektiviteten til store AI-modeller.