Het nieuwe redeneermodel van Deepseek, R1, daagt de prestaties van Openai’s Chatgpt O1 uit-hoewel het afhankelijk is van Throttled GPU’s en een relatief klein budget.
In een omgeving gevormd door Amerikaanse exportcontroles die geavanceerde chips beperken, heeft de Chinese kunstmatige inlichtingenstartup opgericht door hedgefondsbeheerder Liang Wenfeng, laat zien hoe efficiëntie en het delen van middelen AI AI kunnen voortstuwen.
De opkomst van het bedrijf heeft de aandacht getrokken van technologische kringen in zowel China als de Verenigde Staten.
Gerelateerd : Waarom Amerikaanse sancties kunnen worstelen om de technische groei van China te beteugelen
De diepe stijging
De Deepseek’s reis begon in 2021, toen Liang, het best bekend staat om zijn Quant Trading Fund High-Flyer , begon duizenden Nvidia GPU’s te kopen.
Destijds leek deze beweging ongebruikelijk. Als een van Liang’s Business Partners vertelde de Financial Times,”toen we hem voor het eerst ontmoetten, hem,”Hij was deze zeer nerdy man met een vreselijk kapsel dat sprak over het bouwen van een cluster van 10.000 chip om zijn eigen modellen te trainen. We hebben hem niet serieus genomen.”
Volgens dezelfde bron,”kon hij zijn visie niet verwoorden dan zeggen: ik wil dit bouwen, en het zal een spelverandering zijn. We dachten Dit was alleen mogelijk van reuzen zoals Bytedance en Alibaba.”
Ondanks de eerste scepsis, bleef Liang gefocust op het voorbereiden op mogelijke Amerikaanse exportcontroles. Deze vooruitziende blik stelde Deepseek in staat om een grote voorraad NVIDIA-hardware te beveiligen, inclusief A100 en H800 GPU’s, voordat de vegende beperkingen van kracht werden.
Gerelateerd: Deepseek AI Open bronnen VL2-serie Visietaal Taal Modellen
Deepseek haalde de krantenkoppen door te onthullen dat het zijn model R1 van 671 miljard-parameter had getraind voor slechts $ 5,6 miljoen met 2.048 nvidia H800 GPU’s.
Hoewel de prestaties van de H800 opzettelijk zijn afgesloten voor De Chinese markt, de ingenieurs van DeepSeek, hebben de trainingsprocedure geoptimaliseerd om resultaten op hoog niveau te bereiken tegen een fractie van de kosten die meestal worden geassocieerd met grootschalige taalmodellen.
in an interview Gepubliceerd door MIT Technology Review, Zihan Wang, een voormalige Deepseek-onderzoeker, beschrijft hoe het team erin is geslaagd om geheugengebruik en computationele overhead te verminderen met behoud van de nauwkeurigheid.
Hij zei dat technische beperkingen hen ertoe hebben aangezet om nieuwe technische strategieën te verkennen, waardoor ze uiteindelijk helpen concurrerend te blijven tegen beter gefinancierde Amerikaanse tech-laboratoria.
gerelateerd : China’s Deepseek R1 redeneermodel en OpenAI O1 mededinger is zwaar gecensureerd
Uitzonderlijke resultaten op wiskunde-en coderingsbenchmarks
R1 vertoont uitstekende mogelijkheden voor verschillende wiskundige en coderende benchmarks. Deepseek onthulde dat R1 97,3% scoorde (pass@1) op MATH-500 en 79,8% op AIME 2024.
Deze cijfers die de O1-serie van Openai evenaren, waaruit bleek hoe opzettelijke optimalisatie modellen kan uitdagen die zijn getraind op krachtigere chips.
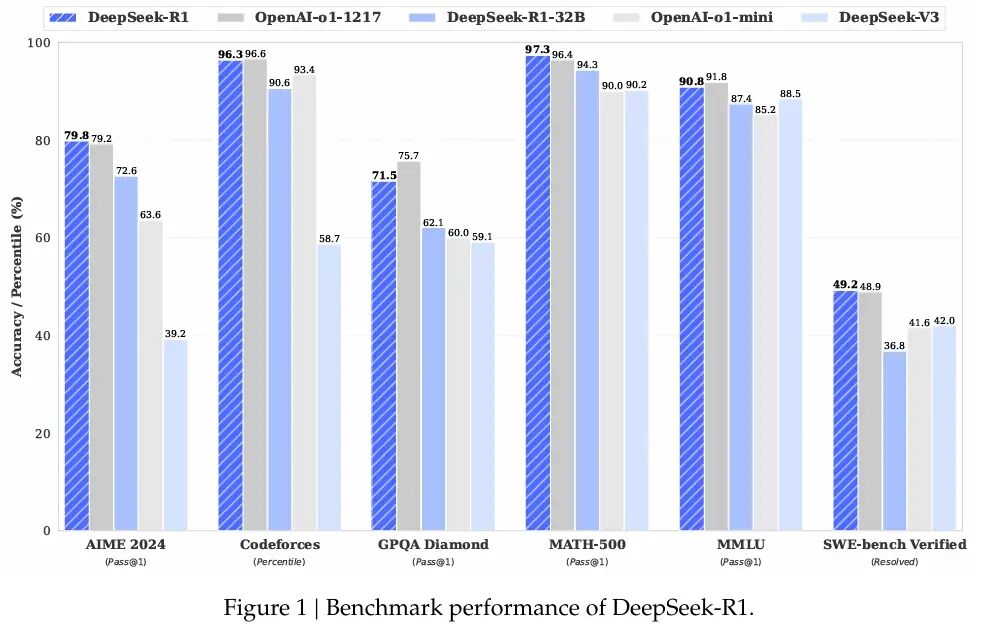
dimitris Papailiopoulos, een hoofdonderzoeker bij Microsoft’s AI Frontiers Lab, vertelde MIT Technology Review:”Deepseek streefde naar nauwkeurige antwoorden in plaats van elke logische stap te detailleren, waardoor de computertijd aanzienlijk wordt verkort met behoud van een hoog niveau van effectiviteit.”
Beyond Het hoofdmodel, Deepseek heeft kleinere versies van R1 vrijgegeven die kunnen worden uitgevoerd op hardware van consumentenkwaliteit.
Deepseek heeft grotendeels O1-Mini gerepliceerd en heeft het open gepland. pic.twitter.com/2tbq5p5l2c
-aravind srinivas (@aravsrinivas) 20 januari 2025
keten van gedachte redenering en R1-Zero Naast de standaardtraining van R1 waagde Deepseek zich in pure versterking met een variant genaamd R1-Zero. Deze aanpak, gedetailleerd in de onderzoeksdocumentatie van het bedrijf, verwerft begeleide verfijning ten gunste van Group Relative Policy Optimization (GRPO).
Door een afzonderlijk criticus-model te verwijderen en te vertrouwen op gegroepeerde baseline-scores, vertoonde R1-Zero de redenering van de ketting van de debit en zelfreflectiegedrag. Het team erkende echter dat R1-Zero repetitieve of gemengde taaluitgangen produceerde, wat aangeeft dat gedeeltelijk toezicht nodig is voordat het in alledaagse toepassingen kon worden gebruikt. Veel gepatenteerde laboratoria. Terwijl Amerikaanse bedrijven zoals Openai, Meta en Google DeepMind hun trainingsmethoden vaak verborgen houden, maakt Deepseek zijn code, modelgewichten en trainingsrecepten openbaar beschikbaar.
gerelateerd : Mistral AI Debuts Pixtral 12B voor tekst-en beeldverwerking
Volgens Liang komt deze aanpak voort uit een verlangen om een onderzoekscultuur op te bouwen die begunstigt die voorstander is transparantie en collectieve vooruitgang. In een Interview Met de Chinese media-outlet 36KR legde hij uit dat veel Chinese AI-ondernemingen worstelen met efficiëntie in vergelijking met hun westerse collega’s, En dat het overbruggen van die kloof vereist samenwerking in zowel hardware-als trainingsstrategieën.
Zijn standpunt komt overeen met anderen in de AI-scene van China, waar open-source releases toenemen. Alibaba Cloud heeft meer dan 100 open-source modellen geïntroduceerd, en 01.AI, opgericht door Kai-Fu Lee, is onlangs samengewerkt met Alibaba Cloud om een industrieel AI-laboratorium op te richten.
De wereldwijde technische gemeenschap heeft gereageerd met een Mix van ontzag en voorzichtigheid. Op X, Marc Andreessen, mede-uitvinder van de mozaïekwebbrowser en nu een toonaangevende investeerder bij Andreessen Horowitz, schreef: “Deepseek R1 is een van de meest verbazingwekkende en indrukwekkende doorbraak die ik ooit heb gezien-en als open source, een diepgaande Geschenk aan de wereld.”
Deepseek R1 is een van de meest verbazingwekkende en indrukwekkende doorbraken die ik ooit heb gezien-en als open source, een diepgaand geschenk voor de wereld. 🤖🫡
— Marc Andreessen 🇺🇸 (@pmarca) January 24, 2025
Yann Lecun, Chief AI-wetenschapper bij Meta, merkte op LinkedIn op dat hoewel Deepseek’s prestatie zou kunnen aangeven dat China de Verenigde Staten overtreft, het nauwkeuriger zou zijn om te zeggen dat open-source-modellen gezamenlijk inhalen voor eigen alternatieven.
“Deepseek heeft geprofiteerd van Open Research and Open Source (bijv. Pytorch en Lama van Meta),”legde hij uit. “Ze kwamen met nieuwe ideeën en bouwden ze bovenop het werk van anderen. Omdat hun werk is gepubliceerd en open source is, kan iedereen ervan profiteren. Dat is de kracht van open onderzoek en open source.”
Bekijk op threads
zelfs Mark Zuckerberg, oprichter en CEO van Meta, liet doorschemeren op een andere weg door massale investeringen in datacenters en GPU-infrastructuur aan te kondigen. > Op Facebook schreef hij: “Dit zal een bepalend jaar zijn voor AI. In 2025 verwacht ik’Ll Bouw een AI-ingenieur die zal beginnen met het bijdragen van toenemende hoeveelheden code aan onze R & D-inspanningen.’Ik breng online ~ 1GW van Compute in’25 en we zullen het jaar eindigen met meer dan 1,3 miljoen GPU’s. Kapitaal om te blijven investeren in de komende jaren. Dit is een enorme inspanning, en in de komende jaren zal het onze kernproducten en bedrijven stimuleren, historische innovatie ontgrendelen en het leiderschap van de Amerikaanse technologie uitbreiden. Laten we gaan bouwen!”
De opmerkingen van Zuckerberg suggereren dat resource-intensieve strategieën een belangrijke kracht blijven bij het vormgeven van de AI-sector.
gerelateerd: lama ai onder vuur-Wat meta je niet vertelt over”Open Source”-modellen
verbreding van impact en toekomstperspectieven
Voor Deepseek, de combinatie van lokaal talent, vroeg GPU-voorraad, en de nadruk op open-source methoden heeft het in een schijnwerpers gebracht die meestal is gereserveerd voor grote technische reuzen. In juli 2024 verklaarde Liang dat zijn team wilde aanpakken wat hij een efficiëntiekloof noemde in de Chinese AI.
Hij beschreef veel lokale AI-bedrijven die het dubbele van de rekenkracht nodig hebben om overzeese resultaten te matchen, waardoor dat verder wordt verergerd wanneer gegevensgebruik wordt verwerkt. waardoor Liang en zijn ingenieurs zich kunnen concentreren op onderzoeksprioriteiten. Liang zei:
“We schatten dat de beste binnenlandse en buitenlandse modellen een kloof kunnen hebben van eenmalige in modelstructuur en trainingsdynamiek. Alleen al om deze reden moeten we twee keer zoveel rekenkracht consumeren om hetzelfde effect te bereiken.
Bovendien kan er ook een kloof zijn van eenmalige gegevensefficiëntie, dat wil zeggen dat we twee keer zoveel trainingsgegevens en rekenkracht moeten consumeren om hetzelfde effect te bereiken. Samen moeten we vier keer meer rekenkracht consumeren. Wat we moeten doen is deze openingen voortdurend beperken.”
De Deepseek’s reputatie in China kreeg ook een boost toen Liang de enige AI-leider werd die werd uitgenodigd voor een spraakmakende ontmoeting met Li Qiang, de tweede van het land meest krachtige ambtenaar, waar hij werd aangespoord om zich te concentreren op het bouwen van kerntechnologieën.
Hoewel de toekomst onzeker blijft-vooral omdat Amerikaanse beperkingen verder kunnen strakker worden-valt Deepseek op voor het aanpakken van uitdagingen op manieren die beperkingen omzetten in wegen voor snelle probleemoplossing.-Sschaal trainingstechnieken, de startup heeft bredere discussies gemotiveerd over de vraag of resource-efficiëntie ernstig kan wedijveren met massale supercomputerende clusters. De prestaties van dit model kunnen een duurzame route effenen voor AI-vooruitgang in een tijdperk van evoluerende beperkingen.